22 KiB
CogVLM & CogAgent
🔥🔥🔥 🆕 2023/12/15: CogAgent 正式上线! CogAgent是基于CogVLM的开发优化的图像理解模型,具备基于视觉的GUI Agent能力,并在图像理解能力上有进一步提升。支持1120*1120分辨率的图像输入,具备图像多轮对话、GUI Agent、Grounding等多种能力。
🌟 跳转至模型详细介绍:CogVLM介绍,🆕 CogAgent介绍
CogVLM🌐 测试Demo:网页链接 📖 论文:CogVLM: Visual Expert for Pretrained Language Models CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数,支持490*490分辨率的图像理解与多轮对话。 CogVLM-17B 在 10 个经典跨模态基准测试上取得了 SOTA 性能,包括 NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC。 |
CogAgent🌐 测试Demo:即将上线 📖 论文:CogAgent: A Visual Language Model for GUI Agents CogAgent 是基于CogVLM改进的开源视觉语言模型。CogAgent-18B 拥有110亿视觉参数和70亿语言参数,支持1120*1120分辨率的图像理解,在CogVLM功能的基础上,具备GUI图像的Agent能力。 CogAgent-18B 在9个跨模态基准测试上取得了 SOTA 的通用性能,包括VQAv2、OK-VQA、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet、和 POPE。在AITW、Mind2Web等GUI操作数据集上大幅超过已有模型。 |
Release
-
🔥🔥🔥
2023/12/15CogAgent上线。CogAgent是基于CogVLM的开发优化的图像理解模型,具备基于视觉的GUI Agent能力,并在图像理解能力上有进一步提升。支持1120*1120分辨率的图像输入,具备图像多轮对话、GUI Agent、Grounding等多种能力。 -
🔥
2023/12/7CogVLM 支持4-bit量化了!推理只需要占用 11GB 显存!点击查看更多细节。 -
🔥
2023/11/20cogvlm-chat 更新 v1.1 版本,该版本同时支持对话和问答,在多项数据集刷新 SOTA 效果。 -
🔥
2023/11/20CogVLM 的 🤗huggingface 版已开源!包括cogvlm-chat, cogvlm-grounding-generalist/base, cogvlm-base-490/224. 仅使用几行代码即可进行推理,具体使用方法请参考这里。 -
2023/10/27CogVLM 中英双语版正式上线了!欢迎体验! -
2023/10/5CogVLM-17B开源上线。
快速入门
情况1:直接使用网页端Demo进行推理。
-
点击此处可进入CogAgent 网页端 Demo
-
点击此处可进入CogVLM 网页端 Demo。
若需要使用Agent与Grounding功能,请参考修炼手册-Task Prompts
情况2:本地部署 CogVLM / CogAgent 进行推理
我们提供两种图形用户界面(GUI)进行模型推断,分别是命令行界面(CLI)和网页演示。
硬件要求
- 模型推断:1 * A100(80G) 或 2 * RTX 3090(24G)。
- 微调:4 * A100(80G) [推荐] 或 8 * RTX 3090(24G)。
模型权重
若使用代码仓库中的basic_demo/cli_demo*.py运行,会自动下载SAT或是huggingface权重。您也可以选择手动下载需要的权重。
-
CogAgent
模型名称 分辨率 简介 Huggingface model SAT model cogagent-chat 1120 CogAgent模型的对话版本,支持GUI Agent、图像多轮对话、视觉定位等功能 link link -
CogVLM
模型名称 分辨率 简介 Huggingface model SAT model cogvlm-chat-v1.1 490 CogVLM模型的对话版本v1.1,支持像 GPT-4V 一样的图像多轮对话 link link cogvlm-chat 490 CogVLM模型的对话版本,支持像 GPT-4V 一样的图像多轮对话 link link cogvlm-base-224 224 文本-图像预训练后的原始权重。 link link cogvlm-base-490 490 从 cogvlm-base-224 微调得到的 490px 分辨率版本 link link cogvlm-grounding-generalist 490 支持不同的视觉定位任务,例如 REC、Grounding Captioning 等 link link
首先,需要安装依赖项。
pip install -r requirements.txt
python -m spacy download en_core_web_sm
所有代码均位于basic_demo/下,请先切换到该目录下,再进行后续操作。
情况2.1 命令行界面(CLI) - SAT版
通过CLI执行以下命令。
# CogAgent
python cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16 --stream_chat
# CogVLM
python cli_demo_sat.py --from_pretrained cogvlm-chat --version chat_old --bf16 --stream_chat
python cli_demo_sat.py --from_pretrained cogvlm-grounding-generalist --version base --bf16 --stream_chat
该程序会自动下载 sat 模型并在命令行中进行交互。您可以通过输入指令并按 Enter 生成回复。 输入 clear 可清除对话历史,输入 stop 可停止程序。
若您希望手动下载权重,则可将--from_pretrained后替换为模型路径。
我们的模型支持SAT的4-bit量化和8-bit量化,
您可以将--bf16调整为--fp16,或--fp16 --quant 4,或--fp16 --quant 8。
例如,
python cli_demo_sat.py --from_pretrained cogagent-chat --fp16 --quant 8 --stream_chat
python cli_demo_sat.py --from_pretrained cogvlm-chat-v1.1 --fp16 --quant 4 --stream_chat
# SAT版本中,--quant 需和 --fp16配合使用
在这里查看不同模型和--version的对应关系。
情况2.2 命令行界面(CLI) - huggingface版
通过CLI执行以下命令。
# CogAgent
python cli_demo_hf.py --from_pretrained THUDM/cogagent-chat-hf --bf16
# CogVLM
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --bf16
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-grounding-generalist --bf16
若您希望手动下载权重,则可将--from_pretrained后替换为模型路径。
您可以将--bf16调整为--fp16,或--quant 4。例如,我们的模型支持hf的4-bit量化,
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --quant 4
情况2.3 网页演示
我们还提供基于Gradio的本地网页演示。首先,通过运行 pip install gradio 安装Gradio。然后运行 web_demo.py(样例代码使用SAT实现的模型),具体使用方式如下:
python web_demo.py --from_pretrained cogagent-chat --version chat --bf16
python web_demo.py --from_pretrained cogvlm-chat-v1.1 --version chat_old --bf16
python web_demo.py --from_pretrained cogvlm-grounding-generalist --version base --bf16
基于Gradio的 GUI 界面如下:
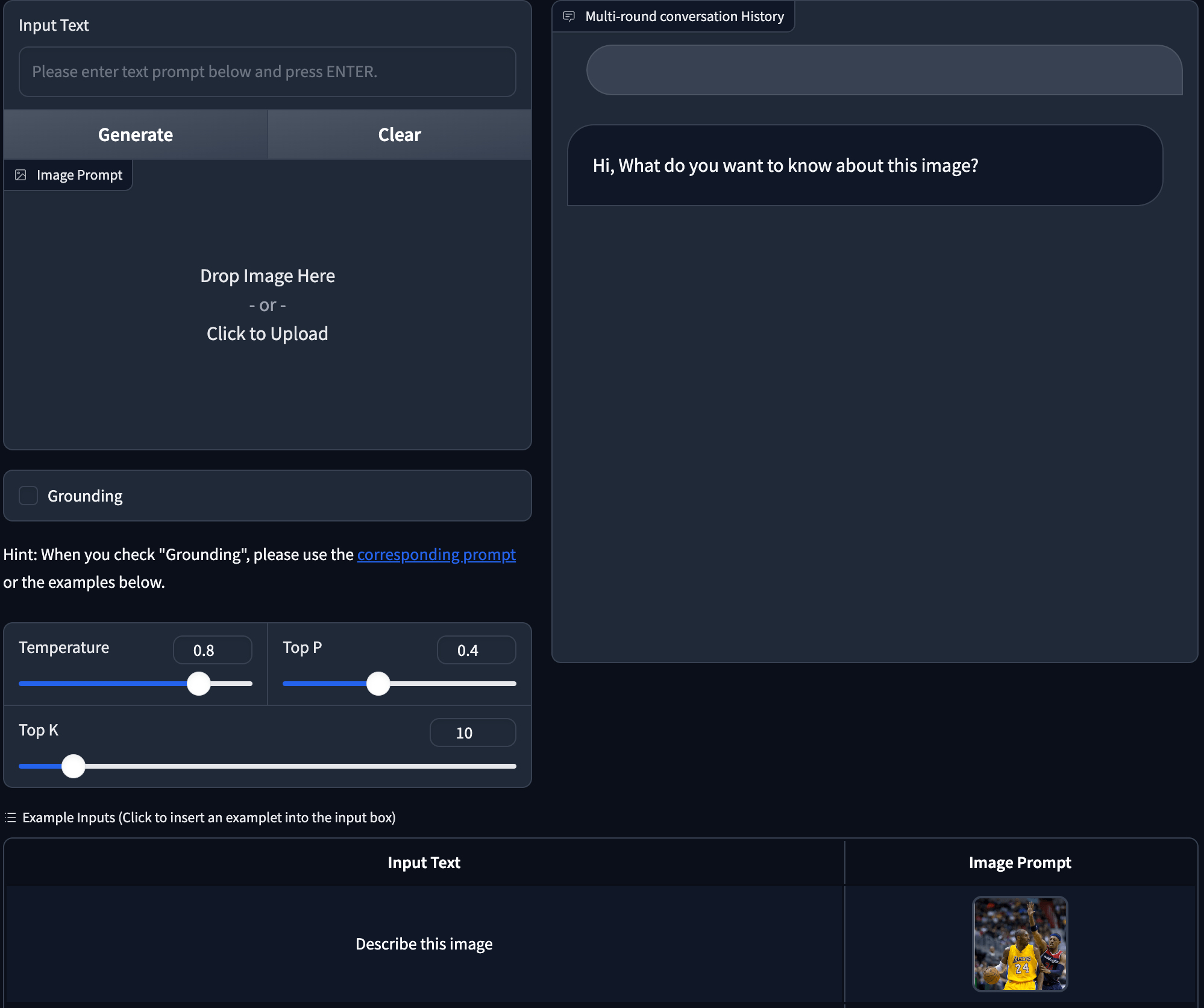
情况3:OpenAI Vision format
我们提供了与 GPT-4V 相同的API示例,你可以在 openai_demo中查看。
- 首先,启动节点
python openai_demo/openai_api.py
- 接着,运行请求示例节点,这是一个连续对话例子
python openai_demo/openai_api_request.py
- 你将能获得类似如下的输出
This image showcases a tranquil natural scene with a wooden pathway leading through a field of lush green grass. In the distance, there are trees and some scattered structures, possibly houses or small buildings. The sky is clear with a few scattered clouds, suggesting a bright and sunny day.
CogVLM介绍
-
CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数,支持490*490分辨率的图像理解。
-
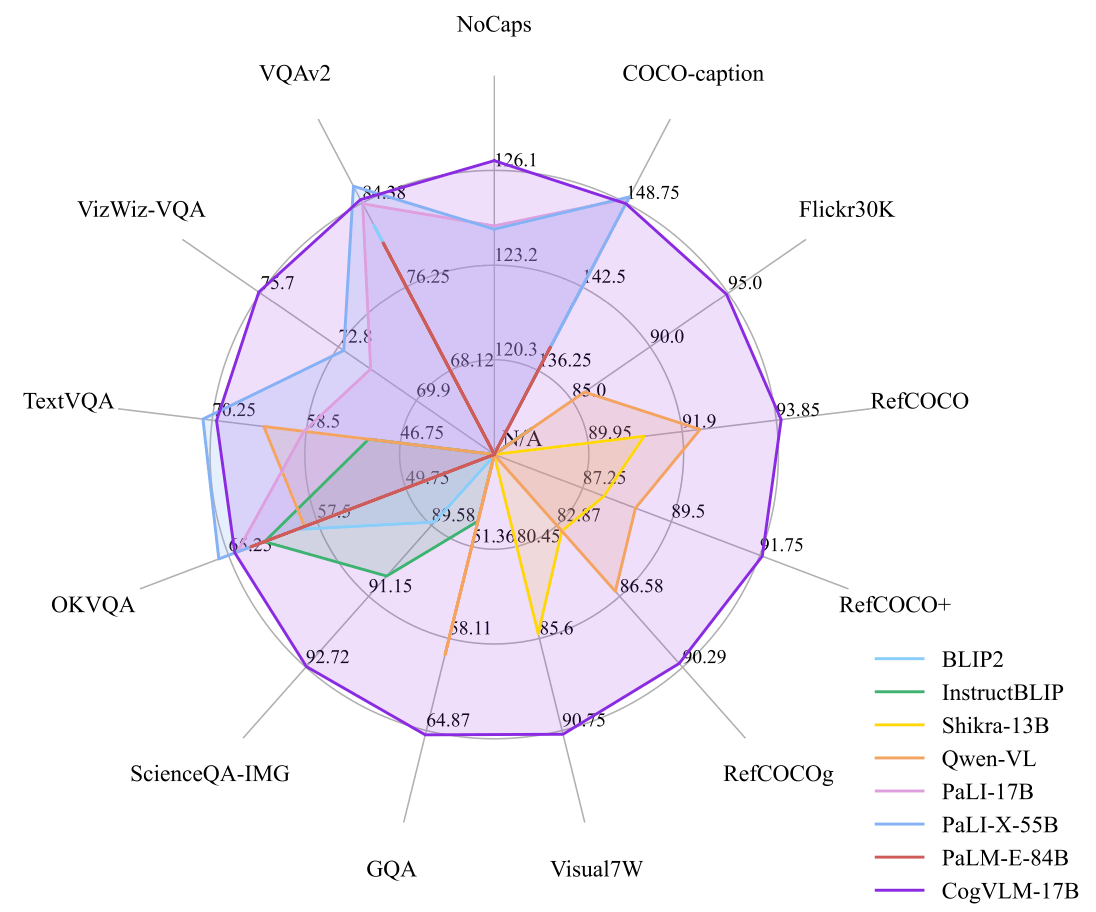
CogVLM-17B 在 10 个经典跨模态基准测试上取得了 SOTA 性能,包括 NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA 和 TDIUC,而在 VQAv2、OKVQA、TextVQA、COCO captioning 等方面则排名第二,超越或与 PaLI-X 55B 持平。您可以通过线上 demo 体验 CogVLM 多模态对话。
点击查看MM-VET, POPE, TouchStone结果。
| Method | LLM | MM-VET | POPE(adversarial) | TouchStone |
| BLIP-2 | Vicuna-13B | 22.4 | - | - |
| Otter | MPT-7B | 24.7 | - | - |
| MiniGPT4 | Vicuna-13B | 24.4 | 70.4 | 531.7 |
| InstructBLIP | Vicuna-13B | 25.6 | 77.3 | 552.4 |
| LLaMA-Adapter v2 | LLaMA-7B | 31.4 | - | 590.1 |
| LLaVA | LLaMA2-7B | 28.1 | 66.3 | 602.7 |
| mPLUG-Owl | LLaMA-7B | - | 66.8 | 605.4 |
| LLaVA-1.5 | Vicuna-13B | 36.3 | 84.5 | - |
| Emu | LLaMA-13B | 36.3 | - | - |
| Qwen-VL-Chat | - | - | - | 645.2 |
| DreamLLM | Vicuna-7B | 35.9 | 76.5 | - |
| CogVLM | Vicuna-7B | **52.8** | **87.6** | **742.0** |
示例
-
CogVLM 能够准确地描述图像,几乎不会出现幻觉。
点击查看与 LLAVA-1.5 和 MiniGPT-4 的比较。

-
CogVLM 能理解和回答各种类型的问题,并有一个视觉定位版本。

- CogVLM 有时比 GPT-4V(ision) 提取到更多的细节信息。

点击展开更多示例。

CogAgent介绍
CogAgent 是基于CogVLM改进的模型。CogAgent-18B 拥有110亿视觉参数和70亿语言参数。
CogAgent-18B 在9个跨模态基准测试上取得了 SOTA 的通用性能,包括VQAv2、OK-VQA、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet、和 POPE。在AITW、Mind2Web等GUI操作数据集上取得了SOTA的性能,大幅超过已有模型。
除了CogVLM已有的全部功能(视觉多轮对话、视觉定位)外,CogAgent
-
支持更高分辨率的视觉输入和对话问答。支持1120*1120超高分辨率的图像输入。
-
具备视觉Agent的能力,针对任意GUI截图,对于用户给定的任务,CogAgent均能返回计划、下一个动作、含坐标的具体操作;
-
提升了GUI相关的问答能力,可以针对任意GUI截图进行问答,例如网页、PPT、手机软件,甚至能够解说原神界面。
-
通过预训练与微调,在OCR相关任务上的能力大幅提升。
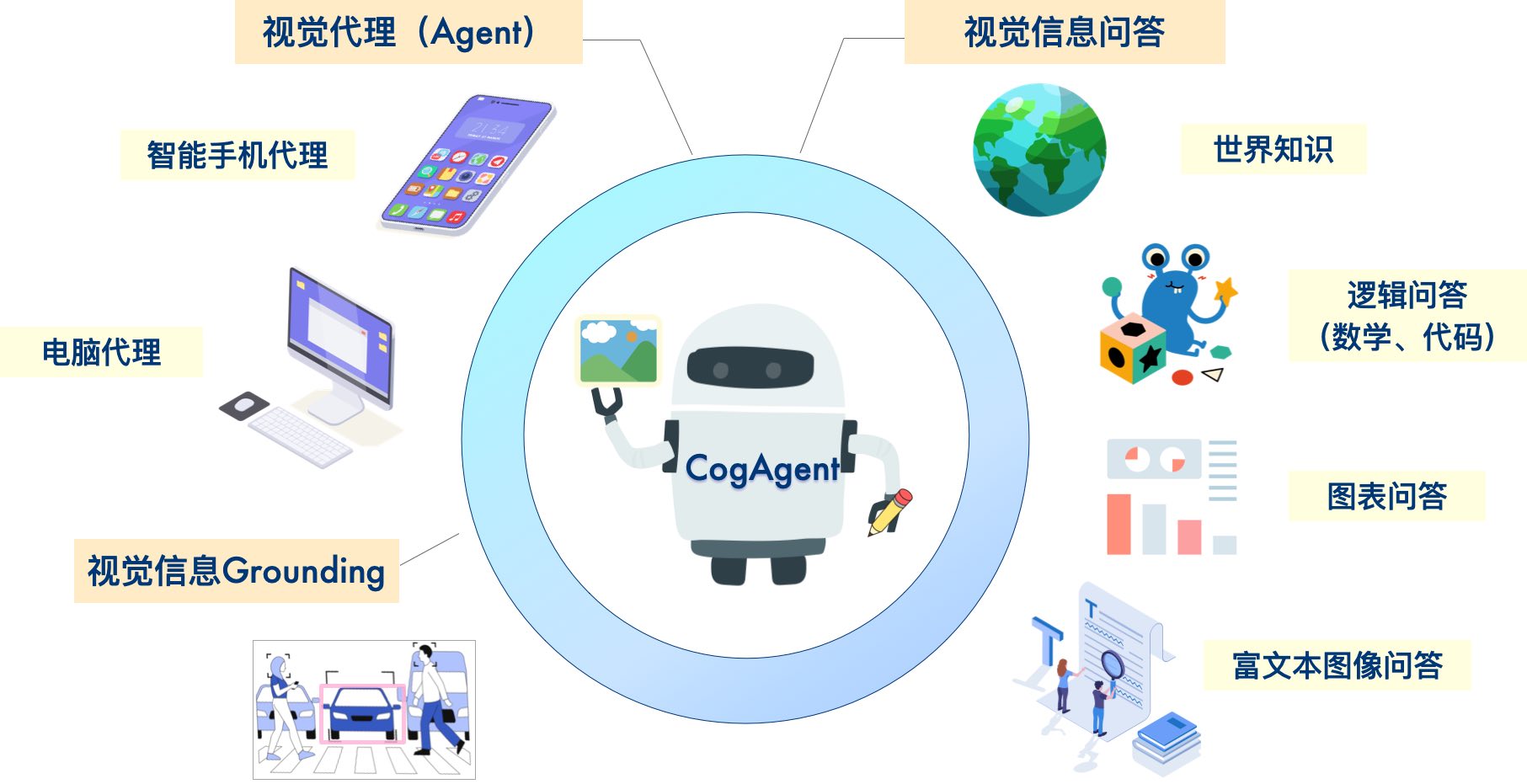
GUI Agent示例

修炼手册
Task Prompts
-
普通多轮对话:正常问答即可。
-
GUI(屏幕截图)的Agent任务:使用Agent模板,将其中的<TASK>替换为用双引号包围的任务指令。该方法可以获得模型推测的Plan和Next Action。若在句末加上
(with grounding),则模型会进一步返回含坐标的形式化表示。例如:若想让模型告诉我,对当前GUI截图,如何完成“Search for CogVLM”这一任务,我们需要依次完成以下几步:
-
在Agent模板中随机选一个模板。这里我们选择了
What steps do I need to take to <TASK>?。 -
把<TASK>替换为用双引号包围的任务指令,即
What steps do I need to take to "Search for CogVLM"?。若将其输入给模型,将会得到: Plan: 1. Type 'CogVLM' into the Google search bar. 2. Review the search results that appear. 3. Click on a relevant result to read more about CogVLM or access further resources. Next Action: Move the cursor to the Google search bar, and type 'CogVLM' into it. -
若想在句末加上
(with grounding),即把模型输入更改为What steps do I need to take to "Search for CogVLM"?(with grounding),将会得到 Plan: 1. Type 'CogVLM' into the Google search bar. 2. Review the search results that appear. 3. Click on a relevant result to read more about CogVLM or access further resources. Next Action: Move the cursor to the Google search bar, and type 'CogVLM' into it. Grounded Operation:[combobox] Search -> TYPE: CogVLM at the box 212,498,787,564
- 一个小提示:对于GUI的Agent的任务,建议每张图仅进行单轮对话,效果更佳。
-
-
普通图片的Grounding。我们支持三种模式的Grounding,包括
- 含Grounding bounding box坐标的图片描述。模板位于caption_with_box模板。任选一个模板作为模型输入即可,例如:Can you provide a description of the image and include the coordinates x0,y0,x1,y1 for each mentioned object?
- 根据物体描述,返回对应的bounding box坐标。模板位于caption2box模板。使用时,将
<expr>替换为物体的描述。例如:Can you point out chidren in blue T-shirts in the image and provide the bounding boxes of its location? - 根据bounding box坐标,返回对应的描述。模板位于box2caption模板。使用时,将
<objs>替换为位置坐标,例如:Tell me what you see within the designated area 120,540,400,760 in the picture.
坐标表示格式: 模型输入输出的bounding box坐标表示都采用 [[x1, y1, x2, y2]]的格式,原点位于左上角,x轴向右,y轴向下,(x1, y1)和(x2, y2)分别是左上和右下角,数值为相对坐标*1000(补前缀0至三位数)。
Which --version to use
由于模型功能的区别,不同模型版本可能有不同的text processor的--version,即使用的prompt格式不同。
| 模型名称 | --version |
|---|---|
| cogagent-chat | chat |
| cogvlm-chat | chat_old |
| cogvlm-chat-v1.1 | chat_old |
| cogvlm-grounding-generalist | base |
| cogvlm-base-224 | base |
| cogvlm-base-490 | base |
许可
此存储库中的代码是根据 Apache-2.0 许可 开放源码,而使用 CogVLM 模型权重必须遵循 模型许可。
引用 & 鸣谢
如果您觉得我们的工作有帮助,请考虑引用以下论文:
@misc{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{hong2023cogagent,
title={CogAgent: A Visual Language Model for GUI Agents},
author={Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2312.08914},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
在 CogVLM 的指令微调阶段,我们使用了来自 MiniGPT-4 、 LLAVA 、 LRV-Instruction、 LLaVAR 和 Shikra 项目的一些英文图像-文本数据,以及许多经典的跨模态工作数据集。我们衷心感谢他们的贡献。