Update LLamaSharpCpp |
||
|---|---|---|
| .github | ||
| Assets | ||
| LLama | ||
| LLama.Examples | ||
| LLama.KernelMemory | ||
| LLama.SemanticKernel | ||
| LLama.Unittest | ||
| LLama.Web | ||
| LLama.WebAPI | ||
| docs | ||
| llama.cpp@3ab8b3a92e | ||
| .gitignore | ||
| .gitmodules | ||
| CMakeLists.txt | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| LLamaSharp.sln | ||
| README.md | ||
| mkdocs.yml | ||
README.md










The C#/.NET binding of llama.cpp. It provides higher-level APIs to inference the LLaMA Models and deploy it on local device with C#/.NET. It works on Windows, Linux and Mac without need to compile llama.cpp yourself. Even without a GPU or not enough GPU memory, you can still use LLaMA models! 🤗
Furthermore, it provides integrations with other projects such as semantic-kernel, kernel-memory and BotSharp to provide higher-level applications.
Discussions about the roadmap to v1.0.0: #287
Table of Contents
- Documentation
- Examples
- Installation
-
Quick Start
- Model Inference and Chat Session
- Quantization
- Web API
- Features
- Console Demo
- FAQ
- Contributing
- Contact us
-
Appendix
- LLamaSharp and llama.cpp versions
Documentation
Examples
- Official Console Examples
- Unity Demo
- LLamaStack (with WPF and Web support)
- Blazor Demo (with Model Explorer)
Installation
- Install
LLamaSharppackage in NuGet:
PM> Install-Package LLamaSharp
-
Install one of these backends:
LLamaSharp.Backend.Cpu: Pure CPU for Windows & Linux. Metal for Mac.LLamaSharp.Backend.Cuda11: CUDA11 for Windows and LinuxLLamaSharp.Backend.Cuda12: CUDA 12 for Windows and LinuxLLamaSharp.Backend.OpenCL: OpenCL for Windows and Linux- If none of these backends is suitable you can compile llama.cpp yourself. In this case, please DO NOT install the backend packages! Instead, add your DLL to your project and ensure it will be copied to the output directory when compiling your project. If you do this you must use exactly the correct llama.cpp commit, refer to the version table further down.
-
(optional) For Microsoft semantic-kernel integration, install the LLamaSharp.semantic-kernel package.
-
(optional) For Microsoft kernel-memory integration, install the LLamaSharp.kernel-memory package (this package currently only supports
net6.0).
Tips for choosing a version
Llama.cpp is a fast moving project with frequent breaking changes, therefore breaking changes are expected frequently in LLamaSharp. LLamaSharp follows semantic versioning and will not introduce breaking API changes on patch versions.
It is suggested to update to the latest patch version as soon as it is released, and to update to new major versions as soon as possible.
Quick Start
Model Inference and Chat Session
LLamaSharp provides two ways to run inference: LLamaExecutor and ChatSession. The chat session is a higher-level wrapping of the executor and the model. Here's a simple example to use chat session.
using LLama.Common;
using LLama;
string modelPath = @"<Your Model Path>"; // change it to your own model path.
var parameters = new ModelParams(modelPath)
{
ContextSize = 1024, // The longest length of chat as memory.
GpuLayerCount = 5 // How many layers to offload to GPU. Please adjust it according to your GPU memory.
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
var executor = new InteractiveExecutor(context);
// Add chat histories as prompt to tell AI how to act.
var chatHistory = new ChatHistory();
chatHistory.AddMessage(AuthorRole.System, "Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.");
chatHistory.AddMessage(AuthorRole.User, "Hello, Bob.");
chatHistory.AddMessage(AuthorRole.Assistant, "Hello. How may I help you today?");
ChatSession session = new(executor, chatHistory);
InferenceParams inferenceParams = new InferenceParams()
{
MaxTokens = 256, // No more than 256 tokens should appear in answer. Remove it if antiprompt is enough for control.
AntiPrompts = new List<string> { "User:" } // Stop generation once antiprompts appear.
};
Console.ForegroundColor = ConsoleColor.Yellow;
Console.Write("The chat session has started.\nUser: ");
Console.ForegroundColor = ConsoleColor.Green;
string userInput = Console.ReadLine() ?? "";
while (userInput != "exit")
{
await foreach ( // Generate the response streamingly.
var text
in session.ChatAsync(
new ChatHistory.Message(AuthorRole.User, userInput),
inferenceParams))
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write(text);
}
Console.ForegroundColor = ConsoleColor.Green;
userInput = Console.ReadLine() ?? "";
}
For more usage, please refer to Examples.
Web API
We provide an integration with ASP.NET core and a web app demo. Since we are in short of hands, if you're familiar with ASP.NET core, we'll appreciate it if you would like to help upgrading the Web API integration.
Features
✅: completed. ⚠️: outdated for latest release but will be updated. 🔳: not completed
✅ LLaMa model inference
✅ Embeddings generation, tokenization and detokenization
✅ Chat session
✅ Quantization
✅ Grammar
✅ State saving and loading
✅ BotSharp Integration Online Demo
✅ ASP.NET core Integration
✅ Semantic-kernel Integration
🔳 Fine-tune
✅ Local document search (enabled by kernel-memory)
🔳 MAUI Integration
Console Demo
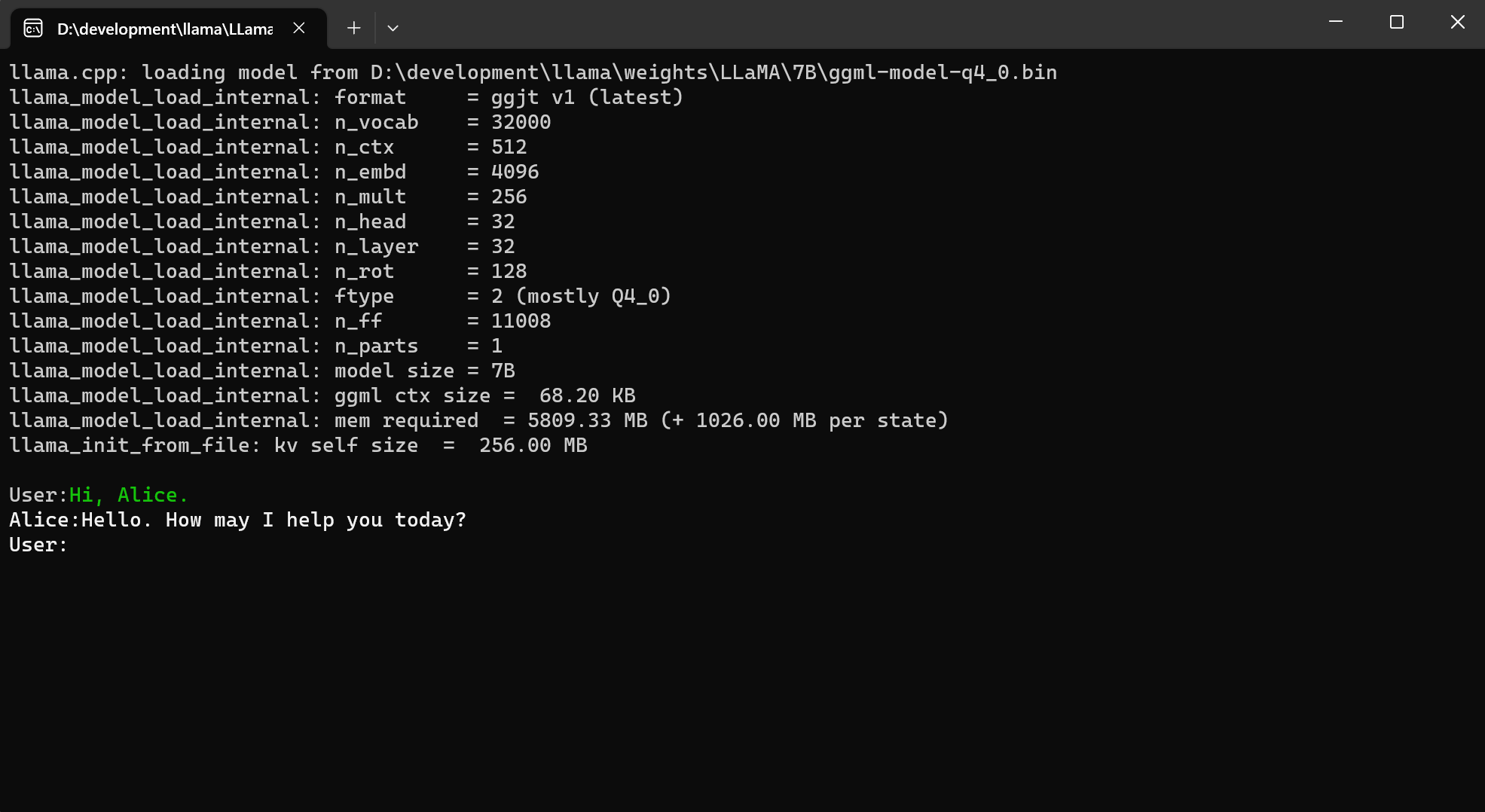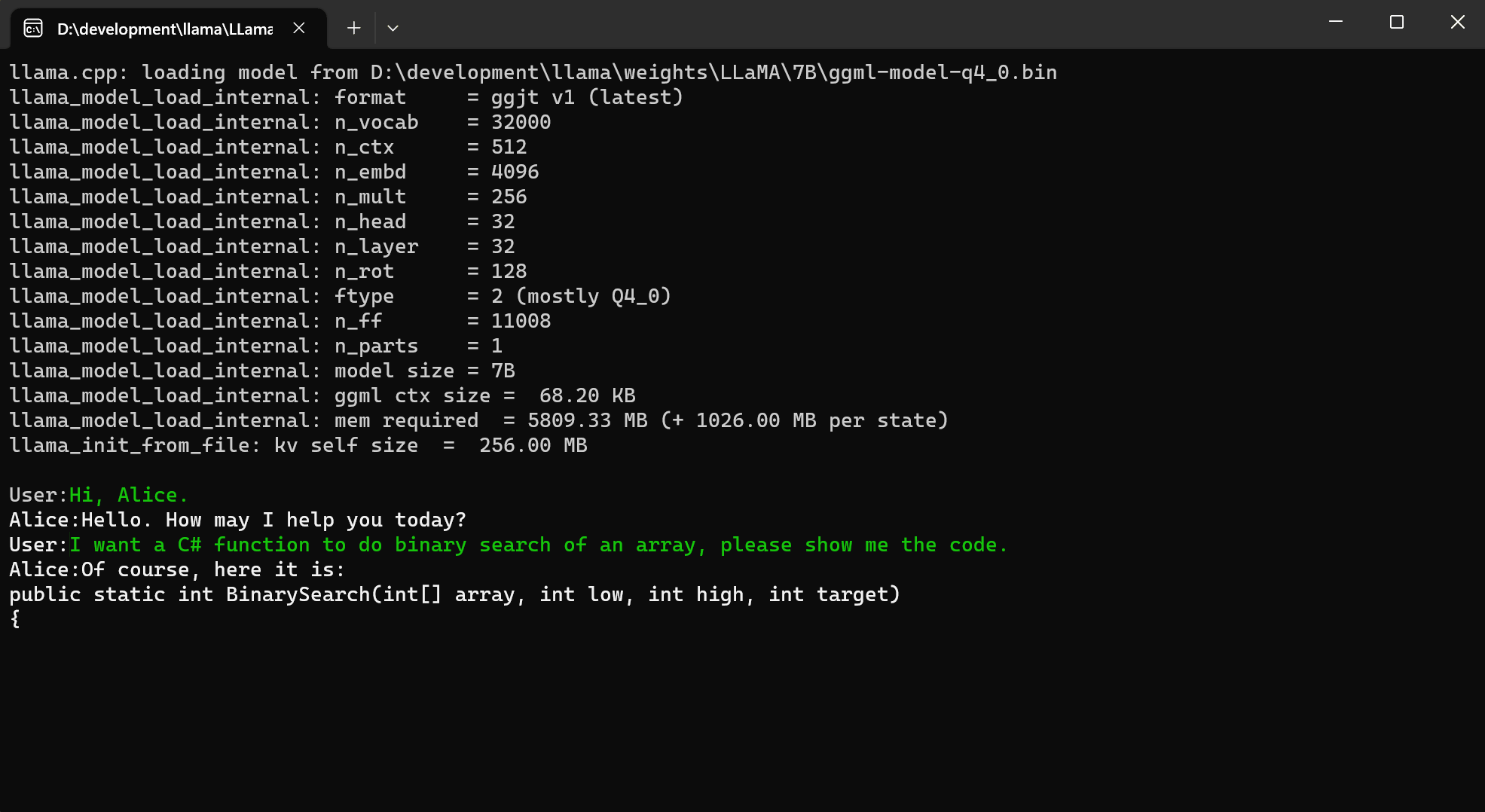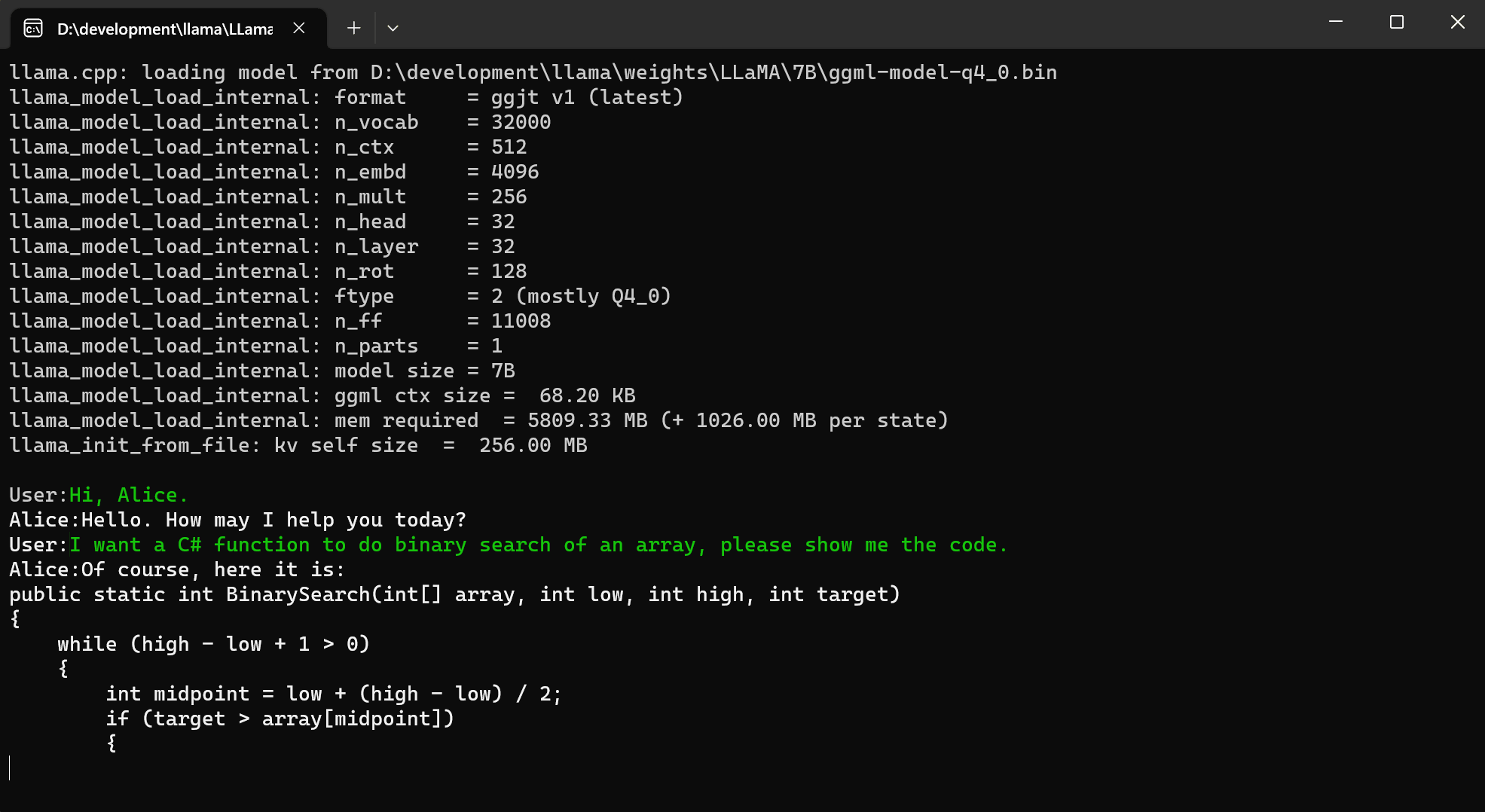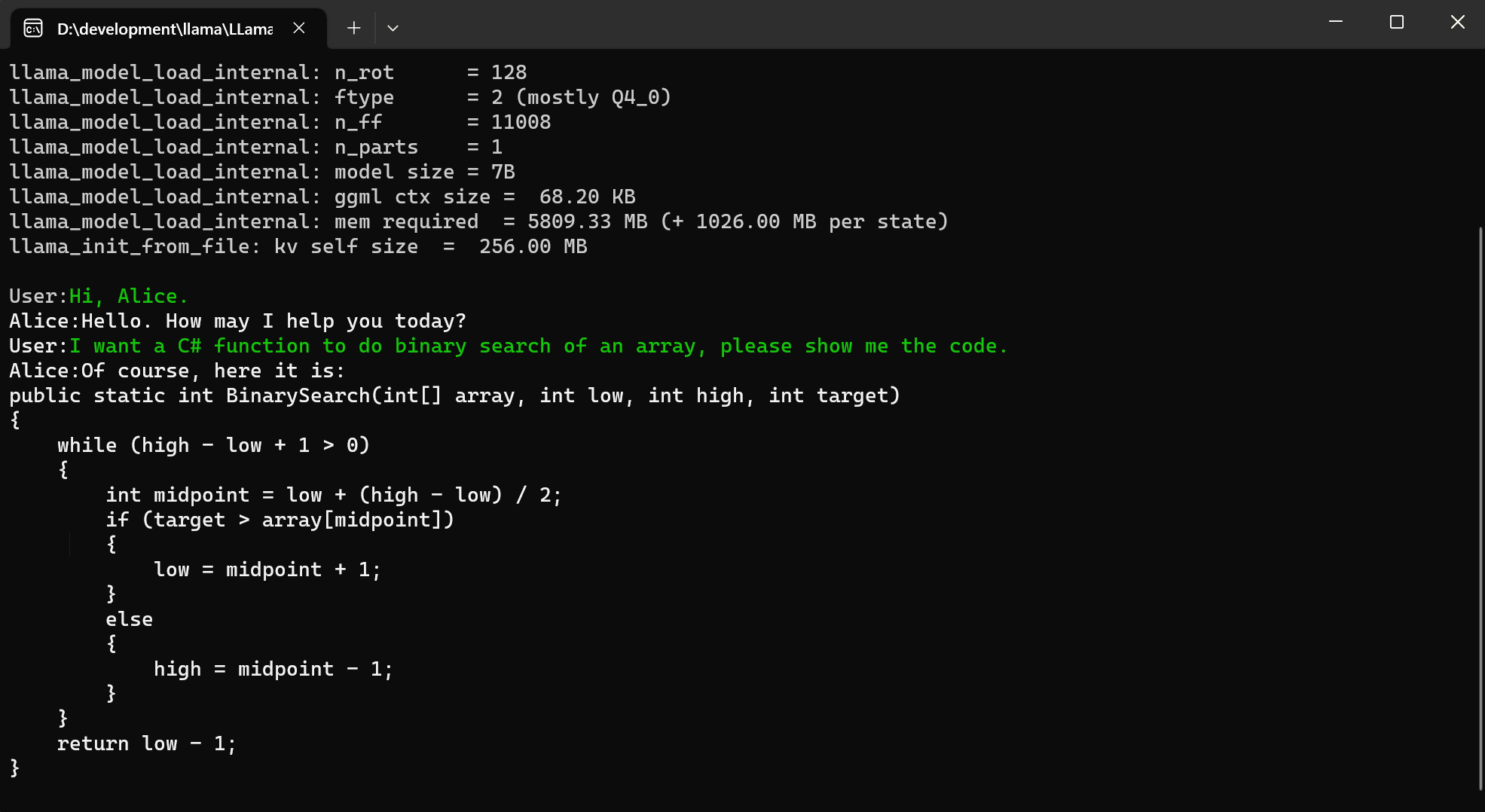
FAQ
- GPU out of memory: Please try setting
n_gpu_layersto a smaller number. - Unsupported model:
llama.cppis under quick development and often has breaking changes. Please check the release date of the model and find a suitable version of LLamaSharp to install, or generateggufformat weights from original weights yourself. - Cannot load native library:
- Ensure you have installed one of the backend packages.
- Run
NativeLibraryConfig.WithLogs()at the very beginning of your code to print more information.
- Models in GGUF format are compatible with LLamaSharp. It's a good idea to search for
ggufon huggingface to find a model. Another choice is generate a GGUF format file yourself, please refer to convert.py for more information.
Contributing
Any contribution is welcomed! There's a TODO list in LLamaSharp Dev Project and you could pick an interesting one to start. Please read the contributing guide for more information.
You can also do one of the followings to help us make LLamaSharp better:
- Submit a feature request.
- Star and share LLamaSharp to let others know it.
- Write a blog or demo about LLamaSharp.
- Help to develop Web API and UI integration.
- Just open an issue about the problem you met!
Contact us
Join our chat on Discord (please contact Rinne to join the dev channel if you want to be a contributor).
Join QQ group
Appendix
LLamaSharp and llama.cpp versions
If you want to compile llama.cpp yourself you must use the exact commit ID listed for each version.
| LLamaSharp | Verified Model Resources | llama.cpp commit id |
|---|---|---|
| v0.2.0 | This version is not recommended to use. | - |
| v0.2.1 | WizardLM, Vicuna (filenames with "old") | - |
| v0.2.2, v0.2.3 | WizardLM, Vicuna (filenames without "old") | 63d2046 |
| v0.3.0, v0.4.0 | LLamaSharpSamples v0.3.0, WizardLM | 7e4ea5b |
| v0.4.1-preview | Open llama 3b, Open Buddy | aacdbd4 |
| v0.4.2-preview | Llama2 7B (GGML) | 3323112 |
| v0.5.1 | Llama2 7B (GGUF) | 6b73ef1 |
| v0.6.0 | cb33f43 |
|
| v0.7.0, v0.8.0 | Thespis-13B, LLaMA2-7B | 207b519 |
| v0.8.1 | e937066 |
|
| v0.9.0, v0.9.1 | Mixtral-8x7B | 9fb13f9 |
| v0.10.0 | Phi2 | d71ac90 |
License
This project is licensed under the terms of the MIT license.