32 KiB
🤗 Transformers로 작업을 해결하는 방법how-transformers-solve-tasks
🤗 Transformers로 할 수 있는 작업에서 자연어 처리(NLP), 음성 및 오디오, 컴퓨터 비전 작업 등의 중요한 응용을 배웠습니다. 이 페이지에서는 모델이 이러한 작업을 어떻게 해결하는지 자세히 살펴보고 내부에서 어떤 일이 일어나는지 설명합니다. 주어진 작업을 해결하는 많은 방법이 있으며, 일부 모델은 특정 기술을 구현하거나 심지어 새로운 방식으로 작업에 접근할 수도 있지만, Transformer 모델의 경우 일반적인 아이디어는 동일합니다. 유연한 아키텍처 덕분에 대부분의 모델은 인코더, 디코더 또는 인코더-디코더 구조의 변형입니다. Transformer 모델뿐만 아니라 우리의 라이브러리에는 오늘날 컴퓨터 비전 작업에 사용되는 몇 가지 합성곱 신경망(CNNs)도 있습니다. 또한, 우리는 현대 CNN의 작동 방식에 대해 설명할 것입니다.
작업이 어떻게 해결되는지 설명하기 위해, 유용한 예측을 출력하고자 모델 내부에서 어떤 일이 일어나는지 살펴봅니다.
- 오디오 분류 및 자동 음성 인식(ASR)을 위한 Wav2Vec2
- 이미지 분류를 위한 Vision Transformer (ViT) 및 ConvNeXT
- 객체 탐지를 위한 DETR
- 이미지 분할을 위한 Mask2Former
- 깊이 추정을 위한 GLPN
- 인코더를 사용하는 텍스트 분류, 토큰 분류 및 질의응답과 같은 NLP 작업을 위한 BERT
- 디코더를 사용하는 텍스트 생성과 같은 NLP 작업을 위한 GPT2
- 인코더-디코더를 사용하는 요약 및 번역과 같은 NLP 작업을 위한 BART
더 나아가기 전에, 기존 Transformer 아키텍처에 대한 기본적인 지식을 숙지하는 것이 좋습니다. 인코더, 디코더 및 어텐션의 작동 방식을 알면 다양한 Transformer 모델이 어떻게 작동하는지 이해하는 데 도움이 됩니다. 시작 단계거나 복습이 필요한 경우, 더 많은 정보를 위해 코스를 확인하세요!
음성 및 오디오speech-and-audio
Wav2Vec2는 레이블이 지정되지 않은 음성 데이터에 대해 사전훈련된 모델로, 오디오 분류 및 자동 음성 인식을 위해 레이블이 지정된 데이터로 미세 조정합니다.
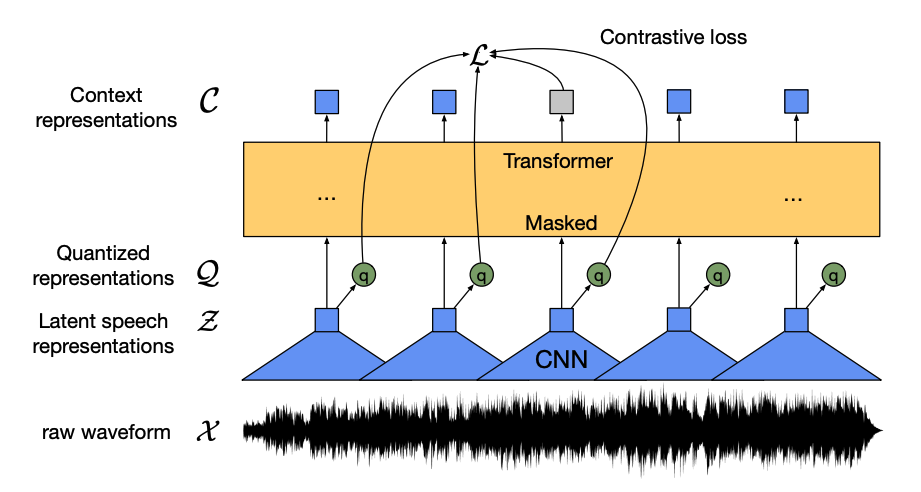
이 모델에는 4가지 주요 구성 요소가 있습니다:
-
*특징 인코더(feature encoder)*는 원시 오디오 파형(raw audio waveform)을 가져와서 제로 평균 및 단위 분산으로 표준화하고, 각각 20ms 길이의 특징 벡터의 시퀀스로 변환합니다.
-
오디오 파형은 본질적으로 연속적이기 때문에, 텍스트 시퀀스를 단어로 나누는 것과 같이 분할할 수 없습니다. 그래서 *양자화 모듈(quantization module)*로 전달되는 특징 벡터는 이산형 음성 단위를 학습하기 위한 것입니다. 음성 단위는 코드북(codebook)(어휘집이라고 생각할 수 있습니다)이라는 코드단어(codewords) 콜렉션에서 선택됩니다. 코드북에서 연속적인 오디오 입력을 가장 잘 나타내는 벡터 또는 음성 단위가 선택되어 모델을 통과합니다.
-
특징 벡터의 절반은 무작위로 마스크가 적용되며, 마스크된 특징 벡터는 상대적 위치 임베딩을 추가하는 Transformer 인코더인 *문맥 네트워크(context network)*로 전달됩니다.
-
문맥 네트워크의 사전훈련 목표는 *대조적 작업(contrastive task)*입니다. 모델은 잘못된 예측 시퀀스에서 마스크된 예측의 실제 양자화된 음성 표현을 예측하며, 모델이 가장 유사한 컨텍스트 벡터와 양자화된 음성 단위(타겟 레이블)를 찾도록 권장합니다.
이제 wav2vec2가 사전훈련되었으므로, 오디오 분류 또는 자동 음성 인식을 위해 데이터에 맞춰 미세 조정할 수 있습니다!
오디오 분류audio-classification
사전훈련된 모델을 오디오 분류에 사용하려면, 기본 Wav2Vec2 모델 상단에 시퀀스 분류 헤드를 추가하면 됩니다. 분류 헤드는 인코더의 은닉 상태(hidden states)를 받는 선형 레이어입니다. 은닉 상태는 각각 길이가 다른 오디오 프레임에서 학습된 특징을 나타냅니다. 고정 길이의 벡터 하나를 만들기 위해, 은닉 상태는 먼저 풀링되고, 클래스 레이블에 대한 로짓으로 변환됩니다. 가장 가능성이 높은 클래스를 찾기 위해 로짓과 타겟 사이의 교차 엔트로피 손실이 계산됩니다.
오디오 분류에 직접 도전할 준비가 되셨나요? 완전한 오디오 분류 가이드를 확인하여 Wav2Vec2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
자동 음성 인식automatic-speech-recognition
사전훈련된 모델을 자동 음성 인식에 사용하려면, 연결주의적 시간 분류(CTC, Connectionist Temporal Classification)를 위해 기본 Wav2Vec2 모델 상단에 언어 모델링 헤드를 추가합니다. 언어 모델링 헤드는 인코더의 은닉 상태를 받아서 로짓으로 변환합니다. 각 로짓은 토큰 클래스(토큰 수는 작업의 어휘에서 나타납니다)를 나타냅니다. CTC 손실은 텍스트로 디코딩된 토큰에서 가장 가능성이 높은 토큰 시퀀스를 찾기 위해 로짓과 타겟 사이에서 계산됩니다.
자동 음성 인식에 직접 도전할 준비가 되셨나요? 완전한 자동 음성 인식 가이드를 확인하여 Wav2Vec2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
컴퓨터 비전computer-vision
컴퓨터 비전 작업에 접근하는 2가지 방법이 있습니다:
- 이미지를 패치 시퀀스로 분리하고 Transformer로 병렬 처리합니다.
- ConvNeXT와 같은 현대 CNN을 사용합니다. 이는 합성곱 레이어를 기반으로 하지만 현대 네트워크 설계를 적용합니다.
세 번째 방법은 Transformer와 합성곱(예를 들어, Convolutional Vision Transformer 또는 LeViT)을 결합하는 것입니다. 우리는 살펴볼 두 가지 방법만 결합하기 때문에 여기서 이 방법을 다루지 않습니다.
ViT와 ConvNeXT는 일반적으로 이미지 분류에서 사용되지만, 물체 감지, 분할, 깊이 추정과 같은 다른 비전 작업에는 각각 DETR, Mask2Former, GLPN이 더 적합하므로 이러한 모델을 살펴보겠습니다.
이미지 분류image-classification
ViT와 ConvNeXT 모두 이미지 분류에 사용될 수 있지만, ViT는 어텐션 메커니즘을, ConvNeXT는 합성곱을 사용하는 것이 주된 차이입니다.
Transformertransformer
ViT은 합성곱을 전적으로 순수 Transformer 아키텍처로 대체합니다. 기존 Transformer에 익숙하다면, ViT를 이해하는 방법의 대부분을 이미 파악했다고 볼 수 있습니다.

ViT가 도입한 주요 변경 사항은 이미지가 Transformer로 어떻게 전달되는지에 있습니다:
-
이미지는 서로 중첩되지 않는 정사각형 패치로 분할되고, 각 패치는 벡터 또는 *패치 임베딩(patch embedding)*으로 변환됩니다. 패치 임베딩은 적절한 입력 차원을 만드는 2D 합성곱 계층에서 생성됩니다(기본 Transformer의 경우 각 패치의 임베딩마다 768개의 값이 필요합니다). 224x224 픽셀 이미지가 있다면, 16x16 이미지 패치 196개로 분할할 수 있습니다. 텍스트가 단어로 토큰화되는 것처럼, 이미지도 패치 시퀀스로 "토큰화"됩니다.
-
학습 가능한 임베딩(learnable embedding)(특수한
[CLS]토큰)이 BERT와 같이 패치 임베딩의 시작 부분에 추가됩니다.[CLS]토큰의 마지막 은닉 상태는 부착된 분류 헤드의 입력으로 사용되고, 다른 출력은 무시됩니다. 이 토큰은 모델이 이미지의 표현을 인코딩하는 방법을 학습하는 데 도움이 됩니다. -
패치와 학습 가능한 임베딩에 마지막으로 추가할 것은 위치 임베딩입니다. 왜냐하면 모델은 이미지 패치의 순서를 모르기 때문입니다. 위치 임베딩도 학습 가능하며, 패치 임베딩과 동일한 크기를 가집니다. 최종적으로, 모든 임베딩이 Transformer 인코더에 전달됩니다.
-
[CLS]토큰을 포함한 출력은 다층 퍼셉트론 헤드(MLP)에 전달됩니다. ViT의 사전훈련 목표는 단순히 분류입니다. 다른 분류 헤드와 같이, MLP 헤드는 출력을 클래스 레이블에 대해 로짓으로 변환하고 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 클래스를 찾습니다.
이미지 분류에 직접 도전할 준비가 되셨나요? 완전한 이미지 분류 가이드를 확인하여 ViT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
CNNcnn
이 섹션에서는 합성곱에 대해 간략하게 설명합니다. 그러나 이미지의 모양과 크기가 어떻게 변화하는지에 대한 사전 이해가 있다면 도움이 될 것입니다. 합성곱에 익숙하지 않은 경우, fastai book의 합성곱 신경망 챕터를 확인하세요!
ConvNeXT는 성능을 높이기 위해 새로운 현대 네트워크 설계를 적용한 CNN 구조입니다. 그러나 합성곱은 여전히 모델의 핵심입니다. 높은 수준의 관점에서 볼 때, 합성곱은 작은 행렬(커널)에 이미지 픽셀의 작은 윈도우를 곱하는 연산입니다. 이는 특정 텍스쳐(texture)이나 선의 곡률과 같은 일부 특징을 계산합니다. 그러고 다음 픽셀 윈도우로 넘어가는데, 여기서 합성곱이 이동하는 거리를 *보폭(stride)*이라고 합니다.

패딩이나 보폭이 없는 기본 합성곱, 딥러닝을 위한 합성곱 연산 가이드
이 출력을 다른 합성곱 레이어에 전달할 수 있으며, 각 연속적인 레이어를 통해 네트워크는 핫도그나 로켓과 같이 더 복잡하고 추상적인 것을 학습합니다. 합성곱 레이어 사이에 풀링 레이어를 추가하여 차원을 줄이고 특징의 위치 변화에 대해 모델을 더 견고하게 만드는 것이 일반적입니다.

ConvNeXT는 CNN을 5가지 방식으로 현대화합니다:
-
각 단계의 블록 수를 변경하고 더 큰 보폭과 그에 대응하는 커널 크기로 이미지를 "패치화(patchify)"합니다. 겹치지 않는 슬라이딩 윈도우는 ViT가 이미지를 패치로 분할하는 방법과 유사하게 이 패치화 전략을 만듭니다.
-
병목(bottleneck) 레이어는 채널 수를 줄였다가 다시 복원합니다. 왜냐하면 1x1 합성곱을 수행하는 것이 더 빠르고, 깊이를 늘릴 수 있기 때문입니다. 역 병목(inverted bottlenect)은 채널 수를 확장하고 축소함으로써 그 반대로 수행하므로, 메모리 효율이 더 높습니다.
-
병목 레이어의 일반적인 3x3 합성곱 레이어를 각 입력 채널에 개별적으로 합성곱을 적용한 다음 마지막에 쌓는 *깊이별 합성곱(depthwise convolution)*으로 대체합니다. 이는 네트워크 폭이 넓혀 성능이 향상됩니다.
-
ViT는 어텐션 메커니즘 덕분에 한 번에 더 많은 이미지를 볼 수 있는 전역 수신 필드를 가지고 있습니다. ConvNeXT는 커널 크기를 7x7로 늘려 이 효과를 재현하려고 시도합니다.
-
또한 ConvNeXT는 Transformer 모델을 모방하는 몇 가지 레이어 설계를 변경합니다. 활성화 및 정규화 레이어가 더 적고, 활성화 함수가 ReLU 대신 GELU로 전환되고, BatchNorm 대신 LayerNorm을 사용합니다.
합성곱 블록의 출력은 분류 헤드로 전달되며, 분류 헤드는 출력을 로짓으로 변환하고 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 레이블을 찾습니다.
객체 탐지object-detection
DETR, DEtection TRansformer는 CNN과 Transformer 인코더-디코더를 결합한 종단간(end-to-end) 객체 탐지 모델입니다.
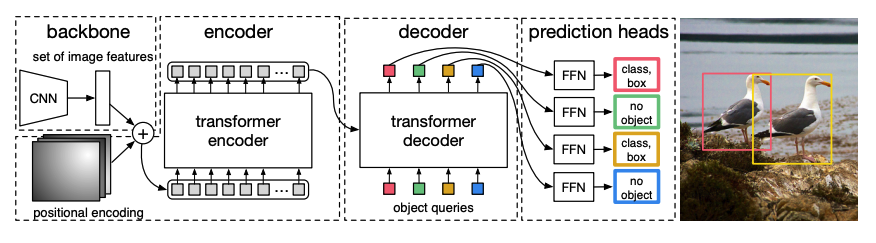
-
사전훈련된 CNN *백본(backbone)*은 픽셀 값으로 나타낸 이미지를 가져와 저해상도 특징 맵을 만듭니다. 특징 맵에 대해 1x1 합성곱을 적용하여 차원을 줄이고, 고수준 이미지 표현을 가진 새로운 특징 맵을 생성합니다. Transformer는 시퀀스 모델이기 때문에 특징 맵을 위치 임베딩과 결합된 특징 벡터의 시퀀스로 평탄화합니다.
-
특징 벡터는 어텐션 레이어를 사용하여 이미지 표현을 학습하는 인코더에 전달됩니다. 다음으로, 인코더의 은닉 상태는 디코더에서 객체 쿼리와 결합됩니다. 객체 쿼리는 이미지의 다른 영역에 초점을 맞춘 학습된 임베딩으로 학습되고, 각 어텐션 레이어를 진행하면서 갱신됩니다. 디코더의 은닉 상태는 각 객체 쿼리에 대한 바운딩 박스 좌표와 클래스 레이블을 예측하는 순방향 네트워크에 전달되며, 객체가 없는 경우
no object가 출력됩니다.DETR은 각 객체 쿼리를 병렬로 디코딩하여 N 개의 최종 예측을 출력합니다. 여기서 N은 쿼리 수입니다. 한 번에 하나의 요소를 예측하는 일반적인 자기회귀 모델과 달리, 객체 탐지는 한 번에 N 개의 예측을 수행하는 집합 예측 작업(
바운딩 박스,클래스 레이블)입니다. -
DETR은 훈련 중 *이분 매칭 손실(bipartite matching loss)*을 사용하여 고정된 수의 예측과 고정된 실제 정답 레이블(ground truth labels) 세트를 비교합니다. N개의 레이블 세트에 실제 정답 레이블보다 적은 경우,
no object클래스로 패딩됩니다. 이 손실 함수는 DETR이 예측과 실제 정답 레이블 간 1:1 대응을 찾도록 권장합니다. 바운딩 박스 또는 클래스 레이블 중 하나라도 잘못된 경우, 손실이 발생합니다. 마찬가지로, 존재하지 않는 객체를 예측하는 경우, 패널티를 받습니다. 이로 인해 DETR은 이미지에서 눈에 잘 띄는 물체 하나에 집중하는 대신, 다른 객체를 찾도록 권장됩니다.
객체 탐지 헤드가 DETR 상단에 추가되어 클래스 레이블과 바운딩 박스의 좌표를 찾습니다. 객체 탐지 헤드에는 두 가지 구성 요소가 있습니다: 디코더 은닉 상태를 클래스 레이블의 로짓으로 변환하는 선형 레이어 및 바운딩 박스를 예측하는 MLP
객체 탐지에 직접 도전할 준비가 되셨나요? 완전한 객체 탐지 가이드를 확인하여 DETR을 미세 조정하고 추론에 사용하는 방법을 학습하세요!
이미지 분할image-segmentation
Mask2Former는 모든 유형의 이미지 분할 작업을 해결하는 범용 아키텍처입니다. 전통적인 분할 모델은 일반적으로 시멘틱(semantic) 또는 파놉틱(panoptic) 분할과 같은 이미지 분할의 특정 하위 작업에 맞춰 조정됩니다. Mask2Former는 모든 작업을 마스크 분류 문제로 구성합니다. 마스크 분류는 픽셀을 N개 세그먼트로 그룹화하고, 주어진 이미지에 대해 N개의 마스크와 그에 대응하는 클래스 레이블을 예측합니다. 이 섹션에서 Mask2Former의 작동 방법을 설명한 다음, 마지막에 SegFormer를 미세 조정해볼 수 있습니다.

Mask2Former에는 3가지 주요 구성 요소가 있습니다:
-
Swin 백본이 이미지를 받아 3개의 연속된 3x3 합성곱에서 저해상도 이미지 특징 맵을 생성합니다.
-
특징 맵은 픽셀 디코더에 전달됩니다. 이 디코더는 저해상도 특징을 고해상도 픽셀 임베딩으로 점진적으로 업샘플링합니다. 픽셀 디코더는 실제로 원본 이미지의 1/32, 1/16, 1/8 해상도의 다중 스케일 특징(저해상도 및 고해상도 특징 모두 포함)을 생성합니다.
-
이러한 서로 다른 크기의 특징 맵은 고해상도 특징에서 작은 객체를 포착하기 위해 한 번에 하나의 Transformer 디코더 레이어에 연속적으로 공급됩니다. Mask2Former의 핵심은 디코더의 마스크 어텐션 메커니즘입니다. 전체 이미지를 참조할 수 있는 크로스 어텐션(cross-attention)과 달리, 마스크 어텐션은 이미지의 특정 영역에만 집중합니다. 이는 이미지의 지역적 특징만으로 모델이 충분히 학습할 수 있기 때문에 더 빠르고 성능이 우수합니다.
-
DETR과 같이, Mask2Former는 학습된 객체 쿼리를 사용하고 이를 픽셀 디코더에서의 이미지 특징과 결합하여 예측 집합(
클래스 레이블,마스크 예측)을 생성합니다. 디코더의 은닉 상태는 선형 레이어로 전달되어 클래스 레이블에 대한 로짓으로 변환됩니다. 로짓과 클래스 레이블 사이의 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 것을 찾습니다.마스크 예측은 픽셀 임베딩과 최종 디코더 은닉 상태를 결합하여 생성됩니다. 시그모이드 교차 엔트로피 및 Dice 손실은 로짓과 실제 정답 마스크(ground truth mask) 사이에서 계산되어 가장 가능성이 높은 마스크를 찾습니다.
이미지 분할에 직접 도전할 준비가 되셨나요? 완전한 이미지 분할 가이드를 확인하여 SegFormer를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
깊이 추정depth-estimation
GLPN, Global-Local Path Network는 SegFormer 인코더와 경량 디코더를 결합한 깊이 추정을 위한 Transformer입니다.

-
ViT와 같이, 이미지는 패치 시퀀스로 분할되지만, 이미지 패치가 더 작다는 점이 다릅니다. 이는 세그멘테이션이나 깊이 추정과 같은 밀도 예측 작업에 더 적합합니다. 이미지 패치는 패치 임베딩으로 변환되어(패치 임베딩이 생성되는 방법은 이미지 분류 섹션을 참조하세요), 인코더로 전달됩니다.
-
인코더는 패치 임베딩을 받아, 여러 인코더 블록에 전달합니다. 각 블록은 어텐션 및 Mix-FFN 레이어로 구성됩니다. 후자의 목적은 위치 정보를 제공하는 것입니다. 각 인코더 블록의 끝에는 계층적 표현을 생성하기 위한 패치 병합(patch merging) 레이어가 있습니다. 각 인접한 패치 그룹의 특징은 연결되고, 연결된 특징에 선형 레이어가 적용되어 패치 수를 1/4의 해상도로 줄입니다. 이는 다음 인코더 블록의 입력이 되며, 이러한 전체 프로세스는 1/8, 1/16, 1/32 해상도의 이미지 특징을 가질 때까지 반복됩니다.
-
경량 디코더는 인코더에서 마지막 특징 맵(1/32 크기)을 가져와 1/16 크기로 업샘플링합니다. 여기서, 특징은 선택적 특징 융합(SFF, Selective Feature Fusion) 모듈로 전달됩니다. 이 모듈은 각 특징에 대해 어텐션 맵에서 로컬 및 전역 특징을 선택하고 결합한 다음, 1/8로 업샘플링합니다. 이 프로세스는 디코딩된 특성이 원본 이미지와 동일한 크기가 될 때까지 반복됩니다. 출력은 두 개의 합성곱 레이어를 거친 다음, 시그모이드 활성화가 적용되어 각 픽셀의 깊이를 예측합니다.
자연어처리natural-language-processing
Transformer는 초기에 기계 번역을 위해 설계되었고, 그 이후로는 사실상 모든 NLP 작업을 해결하기 위한 기본 아키텍처가 되었습니다. 어떤 작업은 Transformer의 인코더 구조에 적합하며, 다른 작업은 디코더에 더 적합합니다. 또 다른 작업은 Transformer의 인코더-디코더 구조를 모두 활용합니다.
텍스트 분류text-classification
BERT는 인코더 전용 모델이며, 텍스트의 풍부한 표현을 학습하기 위해 양방향의 단어에 주목함으로써 심층 양방향성(deep bidirectionality)을 효과적으로 구현한 최초의 모델입니다.
-
BERT는 WordPiece 토큰화를 사용하여 문장의 토큰 임베딩을 생성합니다. 단일 문장과 한 쌍의 문장을 구분하기 위해 특수한
[SEP]토큰이 추가됩니다. 모든 텍스트 시퀀스의 시작 부분에는 특수한[CLS]토큰이 추가됩니다.[CLS]토큰이 있는 최종 출력은 분류 작업을 위한 분류 헤드로 입력에 사용됩니다. BERT는 또한 한 쌍의 문장에서 각 토큰이 첫 번째 문장인지 두 번째 문장에 속하는지 나타내는 세그먼트 임베딩(segment embedding)을 추가합니다. -
BERT는 마스크드 언어 모델링과 다음 문장 예측, 두 가지 목적으로 사전훈련됩니다. 마스크드 언어 모델링에서는 입력 토큰의 일부가 무작위로 마스킹되고, 모델은 이를 예측해야 합니다. 이는 모델이 모든 단어를 보고 다음 단어를 "예측"할 수 있는 양방향성 문제를 해결합니다. 예측된 마스크 토큰의 최종 은닉 상태는 어휘에 대한 소프트맥스가 있는 순방향 네트워크로 전달되어 마스크된 단어를 예측합니다.
두 번째 사전훈련 대상은 다음 문장 예측입니다. 모델은 문장 B가 문장 A 다음에 오는지 예측해야 합니다. 문장 B가 다음 문장인 경우와 무작위 문장인 경우 각각 50%의 확률로 발생합니다. 다음 문장인지 아닌지에 대한 예측은 두 개의 클래스(
IsNext및NotNext)에 대한 소프트맥스가 있는 순방향 네트워크로 전달됩니다. -
입력 임베딩은 여러 인코더 레이어를 거쳐서 최종 은닉 상태를 출력합니다.
사전훈련된 모델을 텍스트 분류에 사용하려면, 기본 BERT 모델 상단에 시퀀스 분류 헤드를 추가합니다. 시퀀스 분류 헤드는 최종 은닉 상태를 받는 선형 레이어이며, 로짓으로 변환하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 타겟 간에 계산되어 가장 가능성이 높은 레이블을 찾습니다.
텍스트 분류에 직접 도전할 준비가 되셨나요? 완전한 텍스트 분류 가이드를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
토큰 분류token-classification
개체명 인식(Named Entity Recognition, NER)과 같은 토큰 분류 작업에 BERT를 사용하려면, 기본 BERT 모델 상단에 토큰 분류 헤드를 추가합니다. 토큰 분류 헤드는 최종 은닉 상태를 받는 선형 레이어이며, 로짓으로 변환하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 각 토큰 간에 계산되어 가장 가능성이 높은 레이블을 찾습니다.
토큰 분류에 직접 도전할 준비가 되셨나요? 완전한 토큰 분류 가이드를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
질의응답question-answering
질의응답에 BERT를 사용하려면, 기본 BERT 모델 위에 스팬(span) 분류 헤드를 추가합니다. 이 선형 레이어는 최종 은닉 상태를 받고, 답변에 대응하는 스팬의 시작과 끝 로그를 계산하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 각 레이블 위치 간에 계산되어 답변에 대응하는 가장 가능성이 높은 텍스트의 스팬을 찾습니다.
질의응답에 직접 도전할 준비가 되셨나요? 완전한 질의응답 가이드를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
💡 사전훈련된 BERT를 다양한 작업에 사용하는 것이 얼마나 쉬운지 주목하세요. 사전훈련된 모델에 특정 헤드를 추가하기만 하면 은닉 상태를 원하는 출력으로 조작할 수 있습니다!
텍스트 생성text-generation
GPT-2는 대량의 텍스트에 대해 사전훈련된 디코딩 전용 모델입니다. 프롬프트를 주어지면 설득력 있는 (항상 사실은 아니지만!) 텍스트를 생성하고 명시적으로 훈련되지 않았음에도 불구하고 질의응답과 같은 다른 NLP 작업을 완수할 수 있습니다.
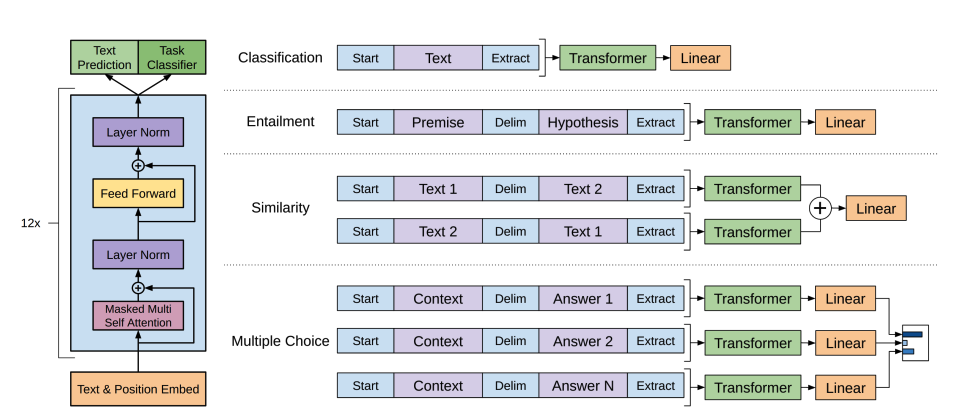
-
GPT-2는 단어를 토큰화하고 토큰 임베딩을 생성하기 위해 바이트 페어 인코딩(BPE, byte pair encoding)을 사용합니다. 위치 인코딩은 시퀀스에서 각 토큰의 위치를 나타내기 위해 토큰 임베딩에 추가됩니다. 입력 임베딩은 여러 디코더 블록을 거쳐 일부 최종 은닉 상태를 출력합니다. 각 디코더 블록 내에서 GPT-2는 마스크드 셀프 어텐션(masked self-attention) 레이어를 사용합니다. 이는 GPT-2가 이후 토큰(future tokens)에 주의를 기울일 수 없도록 합니다. 왼쪽에 있는 토큰에만 주의를 기울일 수 있습니다. 마스크드 셀프 어텐션에서는 어텐션 마스크를 사용하여 이후 토큰에 대한 점수(score)를
0으로 설정하기 때문에 BERT의 [mask] 토큰과 다릅니다. -
디코더의 출력은 언어 모델링 헤드에 전달되며, 언어 모델링 헤드는 은닉 상태를 로짓으로 선형 변환을 수행합니다. 레이블은 시퀀스의 다음 토큰으로, 로짓을 오른쪽으로 하나씩 이동하여 생성됩니다. 교차 엔트로피 손실은 이동된 로짓과 레이블 간에 계산되어 가장 가능성이 높은 다음 토큰을 출력합니다.
GPT-2의 사전훈련 목적은 전적으로 인과적 언어 모델링에 기반하여, 시퀀스에서 다음 단어를 예측하는 것입니다. 이는 GPT-2가 텍스트 생성에 관련된 작업에 특히 우수하도록 합니다.
텍스트 생성에 직접 도전할 준비가 되셨나요? 완전한 인과적 언어 모델링 가이드를 확인하여 DistilGPT-2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
텍스트 생성에 대한 자세한 내용은 텍스트 생성 전략 가이드를 확인하세요!
요약summarization
BART 및 T5와 같은 인코더-디코더 모델은 요약 작업의 시퀀스-투-시퀀스 패턴을 위해 설계되었습니다. 이 섹션에서 BART의 작동 방법을 설명한 다음, 마지막에 T5를 미세 조정해볼 수 있습니다.
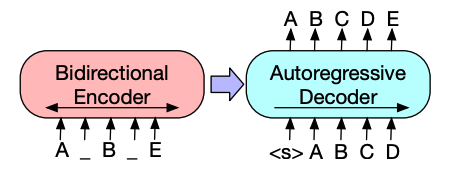
-
BART의 인코더 아키텍처는 BERT와 매우 유사하며 텍스트의 토큰 및 위치 임베딩을 받습니다. BART는 입력을 변형시키고 디코더로 재구성하여 사전훈련됩니다. 특정 변형 기법이 있는 다른 인코더와는 달리, BART는 모든 유형의 변형을 적용할 수 있습니다. 그러나 text infilling 변형 기법이 가장 잘 작동합니다. Text Infiling에서는 여러 텍스트 스팬을 단일 [
mask] 토큰으로 대체합니다. 이는 모델이 마스크된 토큰을 예측해야 하고, 모델에 누락된 토큰의 수를 예측하도록 가르치기 때문에 중요합니다. 입력 임베딩과 마스크된 스팬이 인코더를 거쳐 최종 은닉 상태를 출력하지만, BERT와 달리 BART는 마지막에 단어를 예측하는 순방향 네트워크를 추가하지 않습니다. -
인코더의 출력은 디코더로 전달되며, 디코더는 인코더의 출력에서 마스크 토큰과 변형되지 않은 토큰을 예측해야 합니다. 이는 디코더가 원본 텍스트를 복원하는 데 도움이 되는 추가적인 문맥을 얻도록 합니다. 디코더의 출력은 언어 모델링 헤드에 전달되며, 언어 모델링 헤드는 은닉 상태를 로짓으로 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 토큰이 오른쪽으로 이동된 레이블 간에 계산됩니다.
요약에 직접 도전할 준비가 되셨나요? 완전한 요약 가이드를 확인하여 T5를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
텍스트 생성에 대한 자세한 내용은 텍스트 생성 전략 가이드를 확인하세요!
번역translation
번역은 시퀀스-투-시퀀스 작업의 또 다른 예로, BART 또는 T5와 같은 인코더-디코더 모델을 사용할 수 있습니다. 이 섹션에서 BART의 작동 방법을 설명한 다음, 마지막에 T5를 미세 조정해볼 수 있습니다.
BART는 원천 언어를 타겟 언어로 디코딩할 수 있는 입력에 매핑하기 위해 무작위로 초기화된 별도의 인코더를 추가하여 번역에 적용합니다. 이 새로운 인코더의 임베딩은 원본 단어 임베딩 대신 사전훈련된 인코더로 전달됩니다. 원천 인코더는 모델 출력의 교차 엔트로피 손실로부터 원천 인코더, 위치 임베딩, 입력 임베딩을 갱신하여 훈련됩니다. 첫 번째 단계에서는 모델 파라미터가 고정되고, 두 번째 단계에서는 모든 모델 파라미터가 함께 훈련됩니다.
BART는 이후 번역을 위해 다양한 언어로 사전훈련된 다국어 버전의 mBART로 확장되었습니다.
번역에 직접 도전할 준비가 되셨나요? 완전한 번역 가이드를 확인하여 T5를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
텍스트 생성에 대한 자세한 내용은 텍스트 생성 전략 가이드를 확인하세요!