4.2 KiB
VideoMAE
Overview
The VideoMAE model was proposed in VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training by Zhan Tong, Yibing Song, Jue Wang, Limin Wang. VideoMAE extends masked auto encoders (MAE) to video, claiming state-of-the-art performance on several video classification benchmarks.
The abstract from the paper is the following:
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.
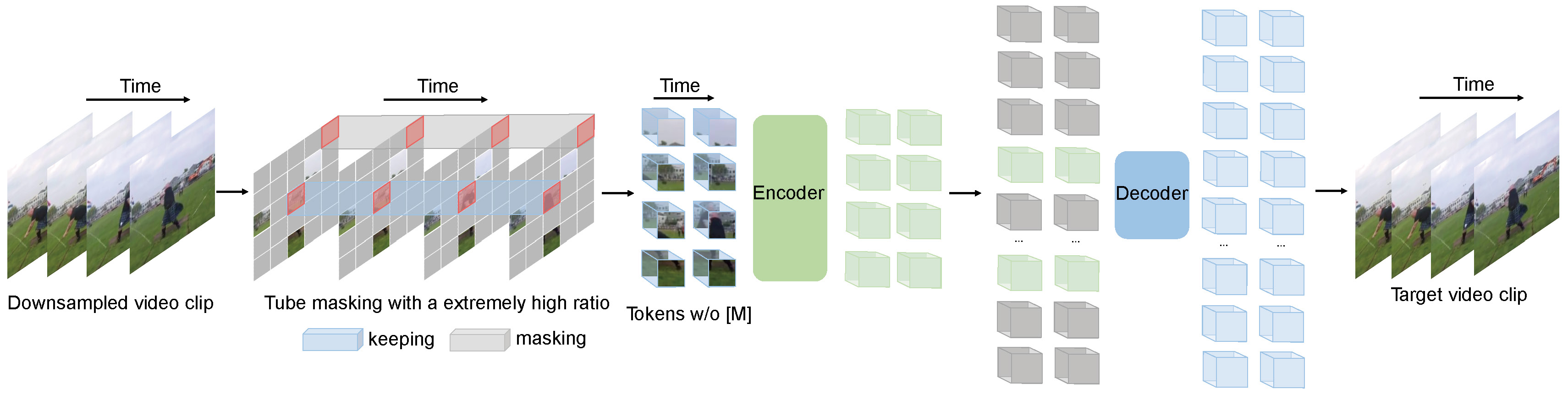
VideoMAE pre-training. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VideoMAE. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
Video classification
- A notebook that shows how to fine-tune a VideoMAE model on a custom dataset.
- Video classification task guide
- A 🤗 Space showing how to perform inference with a video classification model.
VideoMAEConfig
autodoc VideoMAEConfig
VideoMAEFeatureExtractor
autodoc VideoMAEFeatureExtractor - call
VideoMAEImageProcessor
autodoc VideoMAEImageProcessor - preprocess
VideoMAEModel
autodoc VideoMAEModel - forward
VideoMAEForPreTraining
VideoMAEForPreTraining includes the decoder on top for self-supervised pre-training.
autodoc transformers.VideoMAEForPreTraining - forward
VideoMAEForVideoClassification
autodoc transformers.VideoMAEForVideoClassification - forward