96 lines
5.1 KiB
Markdown
96 lines
5.1 KiB
Markdown
<!---
|
|
Copyright 2021 The HuggingFace Team. All rights reserved.
|
|
|
|
Licensed under the Apache License, Version 2.0 (the "License");
|
|
you may not use this file except in compliance with the License.
|
|
You may obtain a copy of the License at
|
|
|
|
http://www.apache.org/licenses/LICENSE-2.0
|
|
|
|
Unless required by applicable law or agreed to in writing, software
|
|
distributed under the License is distributed on an "AS IS" BASIS,
|
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
|
See the License for the specific language governing permissions and
|
|
limitations under the License.
|
|
|
|
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
|
rendered properly in your Markdown viewer.
|
|
|
|
-->
|
|
|
|
# 성능 및 확장성 [[performance-and-scalability]]
|
|
|
|
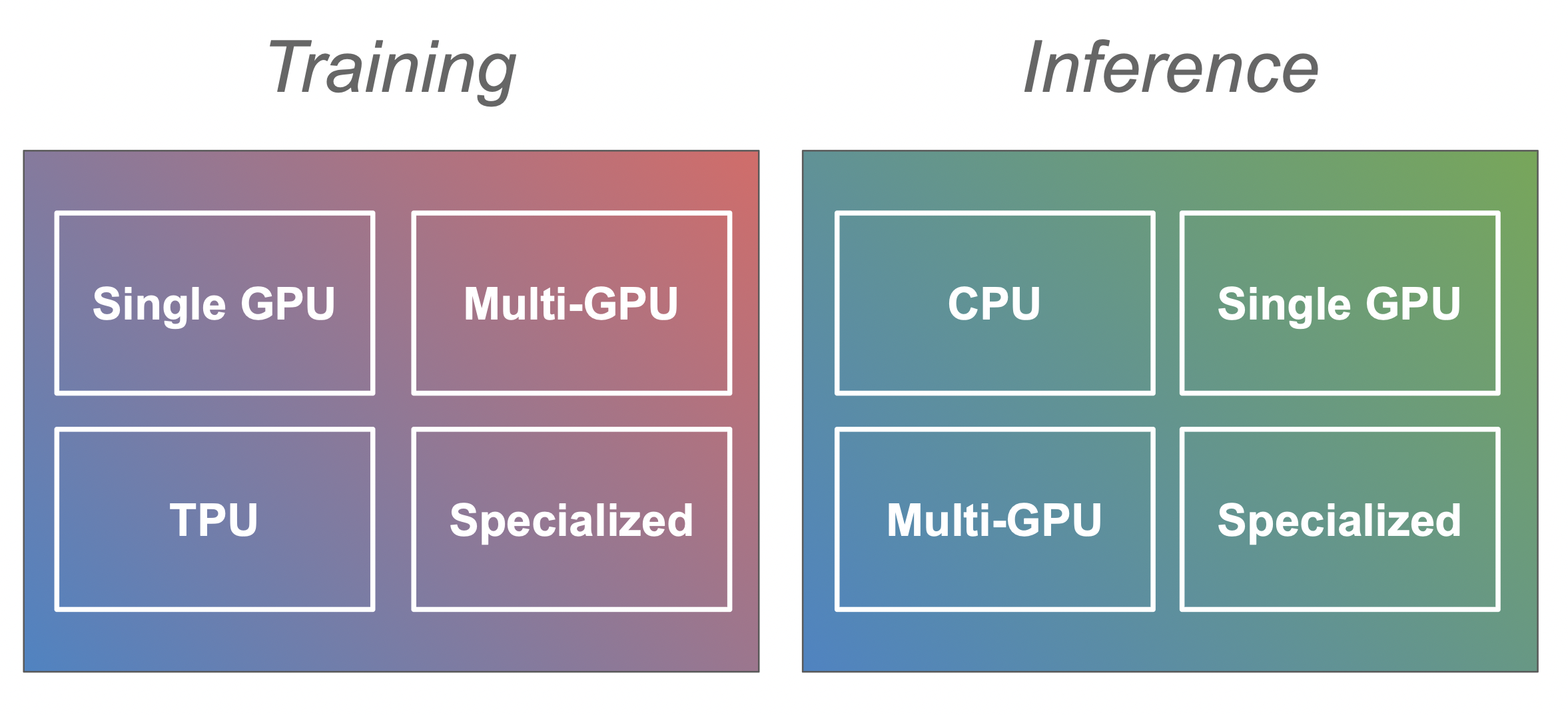
점점 더 큰 규모의 트랜스포머 모델을 훈련하고 프로덕션에 배포하는 데에는 다양한 어려움이 따릅니다. 훈련 중에는 모델이 사용 가능한 GPU 메모리보다 더 많은 메모리를 필요로 하거나 훈련 속도가 매우 느릴 수 있으며, 추론을 위해 배포할 때는 제품 환경에서 요구되는 처리량으로 인해 과부하가 발생할 수 있습니다. 이 문서는 이러한 문제를 극복하고 사용 사례에 가장 적합한 설정을 찾도록 도움을 주기 위해 설계되었습니다. 훈련과 추론으로 가이드를 분할했는데, 이는 각각 다른 문제와 해결 방법이 있기 때문입니다. 그리고 각 가이드에는 다양한 종류의 하드웨어 설정에 대한 별도의 가이드가 있습니다(예: 훈련을 위한 단일 GPU vs 다중 GPU 또는 추론을 위한 CPU vs GPU).
|
|
|
|
|
|
|
|
이 문서는 사용자의 상황에 유용할 수 있는 방법들에 대한 개요 및 시작점 역할을 합니다.
|
|
|
|
## 훈련 [[training]]
|
|
|
|
효율적인 트랜스포머 모델 훈련에는 GPU나 TPU와 같은 가속기가 필요합니다. 가장 일반적인 경우는 단일 GPU만 사용하는 경우지만, 다중 GPU 및 CPU 훈련에 대한 섹션도 있습니다(곧 더 많은 내용이 추가될 예정).
|
|
|
|
<Tip>
|
|
|
|
참고: 단일 GPU 섹션에서 소개된 대부분의 전략(예: 혼합 정밀도 훈련 또는 그라디언트 누적)은 일반적인 모델 훈련에도 적용되므로, 다중 GPU나 CPU 훈련과 같은 섹션을 살펴보기 전에 꼭 참고하시길 바랍니다.
|
|
|
|
</Tip>
|
|
|
|
### 단일 GPU [[single-gpu]]
|
|
|
|
단일 GPU에서 대규모 모델을 훈련하는 것은 어려울 수 있지만, 이를 가능하게 하는 여러 가지 도구와 방법이 있습니다. 이 섹션에서는 혼합 정밀도 훈련, 그라디언트 누적 및 체크포인팅, 효율적인 옵티마이저, 최적의 배치 크기를 결정하기 위한 전략 등에 대해 논의합니다.
|
|
|
|
[단일 GPU 훈련 섹션으로 이동](perf_train_gpu_one)
|
|
|
|
### 다중 GPU [[multigpu]]
|
|
|
|
단일 GPU에서 훈련하는 것이 너무 느리거나 대규모 모델에 적합하지 않은 경우도 있습니다. 다중 GPU 설정으로 전환하는 것은 논리적인 단계이지만, 여러 GPU에서 한 번에 훈련하려면 각 GPU마다 모델의 전체 사본을 둘지, 혹은 모델 자체도 여러 GPU에 분산하여 둘지 등 새로운 결정을 내려야 합니다. 이 섹션에서는 데이터, 텐서 및 파이프라인 병렬화에 대해 살펴봅니다.
|
|
|
|
[다중 GPU 훈련 섹션으로 이동](perf_train_gpu_many)
|
|
|
|
### CPU [[cpu]]
|
|
|
|
|
|
[CPU 훈련 섹션으로 이동](perf_train_cpu)
|
|
|
|
|
|
### TPU [[tpu]]
|
|
|
|
[_곧 제공될 예정_](perf_train_tpu)
|
|
|
|
### 특수한 하드웨어 [[specialized-hardware]]
|
|
|
|
[_곧 제공될 예정_](perf_train_special)
|
|
|
|
## 추론 [[inference]]
|
|
|
|
제품 및 서비스 환경에서 대규모 모델을 효율적으로 추론하는 것은 모델을 훈련하는 것만큼 어려울 수 있습니다. 이어지는 섹션에서는 CPU 및 단일/다중 GPU 설정에서 추론을 진행하는 단계를 살펴봅니다.
|
|
|
|
### CPU [[cpu]]
|
|
|
|
[CPU 추론 섹션으로 이동](perf_infer_cpu)
|
|
|
|
### 단일 GPU [[single-gpu]]
|
|
|
|
[단일 GPU 추론 섹션으로 이동](perf_infer_gpu_one)
|
|
|
|
### 다중 GPU [[multigpu]]
|
|
|
|
[다중 GPU 추론 섹션으로 이동](perf_infer_gpu_many)
|
|
|
|
### 특수한 하드웨어 [[specialized-hardware]]
|
|
|
|
[_곧 제공될 예정_](perf_infer_special)
|
|
|
|
## 하드웨어 [[hardware]]
|
|
|
|
하드웨어 섹션에서는 자신만의 딥러닝 장비를 구축할 때 유용한 팁과 요령을 살펴볼 수 있습니다.
|
|
|
|
[하드웨어 섹션으로 이동](perf_hardware)
|
|
|
|
|
|
## 기여하기 [[contribute]]
|
|
|
|
이 문서는 완성되지 않은 상태이며, 추가해야 할 내용이나 수정 사항이 많이 있습니다. 따라서 추가하거나 수정할 내용이 있으면 주저하지 말고 PR을 열어 주시거나, 자세한 내용을 논의하기 위해 Issue를 시작해 주시기 바랍니다.
|
|
|
|
A가 B보다 좋다고 하는 기여를 할 때는, 재현 가능한 벤치마크와/또는 해당 정보의 출처 링크를 포함해주세요(당신으로부터의 직접적인 정보가 아닌 경우). |