8.5 KiB
Subtítulos de Imágenes
Los subtítulos de imágenes es la tarea de predecir un subtítulo para una imagen dada. Las aplicaciones comunes en el mundo real incluyen ayudar a personas con discapacidad visual que les puede ayudar a navegar a través de diferentes situaciones. Por lo tanto, los subtítulos de imágenes ayuda a mejorar la accesibilidad del contenido para las personas describiéndoles imágenes.
Esta guía te mostrará cómo:
- Ajustar un modelo de subtítulos de imágenes.
- Usar el modelo ajustado para inferencia.
Antes de comenzar, asegúrate de tener todas las bibliotecas necesarias instaladas:
pip install transformers datasets evaluate -q
pip install jiwer -q
Te animamos a que inicies sesión en tu cuenta de Hugging Face para que puedas subir y compartir tu modelo con la comunidad. Cuando se te solicite, ingresa tu token para iniciar sesión:
from huggingface_hub import notebook_login
notebook_login()
Cargar el conjunto de datos de subtítulos BLIP de Pokémon
Utiliza la biblioteca 🤗 Dataset para cargar un conjunto de datos que consiste en pares {image-caption}. Para crear tu propio conjunto de datos de subtítulos de imágenes en PyTorch, puedes seguir este cuaderno.
from datasets import load_dataset
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})
El conjunto de datos tiene dos características, image y text.
Muchos conjuntos de datos de subtítulos de imágenes contienen múltiples subtítulos por imagen. En esos casos, una estrategia común es muestrear aleatoriamente un subtítulo entre los disponibles durante el entrenamiento.
Divide el conjunto de entrenamiento del conjunto de datos en un conjunto de entrenamiento y de prueba con el método [~datasets.Dataset.train_test_split]:
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
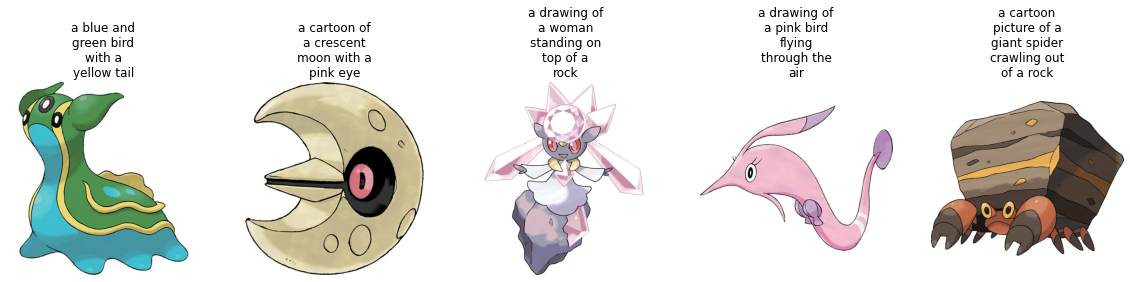
Vamos a visualizar un par de muestras del conjunto de entrenamiento.
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
Preprocesar el conjunto de datos
Dado que el conjunto de datos tiene dos modalidades (imagen y texto), el proceso de preprocesamiento preprocesará las imágenes y los subtítulos.
Para hacerlo, carga la clase de procesador asociada con el modelo que estás a punto de ajustar.
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
El procesador preprocesará internamente la imagen (lo que incluye el cambio de tamaño y la escala de píxeles) y tokenizará el subtítulo.
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
Con el conjunto de datos listo, ahora puedes configurar el modelo para el ajuste fino.
Cargar un modelo base
Carga "microsoft/git-base" en un objeto AutoModelForCausalLM.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
Evaluar
Los modelos de subtítulos de imágenes se evalúan típicamente con el Rouge Score o Tasa de Error de Palabra (Word Error Rate, por sus siglas en inglés). Para esta guía, utilizarás la Tasa de Error de Palabra (WER).
Usamos la biblioteca 🤗 Evaluate para hacerlo. Para conocer las limitaciones potenciales y otros problemas del WER, consulta esta guía.
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}
¡Entrenar!
Ahora, estás listo para comenzar a ajustar el modelo. Utilizarás el 🤗 [Trainer] para esto.
Primero, define los argumentos de entrenamiento usando [TrainingArguments].
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
eval_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)
Luego pásalos junto con los conjuntos de datos y el modelo al 🤗 Trainer.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
Para comenzar el entrenamiento, simplemente llama a [~Trainer.train] en el objeto [Trainer].
trainer.train()
Deberías ver cómo disminuye suavemente la pérdida de entrenamiento a medida que avanza el entrenamiento.
Una vez completado el entrenamiento, comparte tu modelo en el Hub con el método [~Trainer.push_to_hub] para que todos puedan usar tu modelo:
trainer.push_to_hub()
Inferencia
Toma una imagen de muestra de test_ds para probar el modelo.
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image

Prepara la imagen para el modelo.
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
Llama a [generate] y decodifica las predicciones.
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
a drawing of a pink and blue pokemon
¡Parece que el modelo ajustado generó un subtítulo bastante bueno!