mirror of https://github.com/open-mmlab/mmpose
472 lines
16 KiB
Markdown
472 lines
16 KiB
Markdown
# 编解码器
|
||
|
||
在关键点检测任务中,根据算法的不同,需要利用标注信息,生成不同格式的训练目标,比如归一化的坐标值、一维向量、高斯热图等。同样的,对于模型输出的结果,也需要经过处理转换成标注信息格式。我们一般将标注信息到训练目标的处理过程称为编码,模型输出到标注信息的处理过程称为解码。
|
||
|
||
编码和解码是一对紧密相关的互逆处理过程。在 MMPose 早期版本中,编码和解码过程往往分散在不同模块里,使其不够直观和统一,增加了学习和维护成本。
|
||
|
||
MMPose 1.0 中引入了新模块 **编解码器(Codec)** ,将关键点数据的编码和解码过程进行集成,以增加代码的友好度和复用性。
|
||
|
||
编解码器在工作流程中所处的位置如下所示:
|
||
|
||
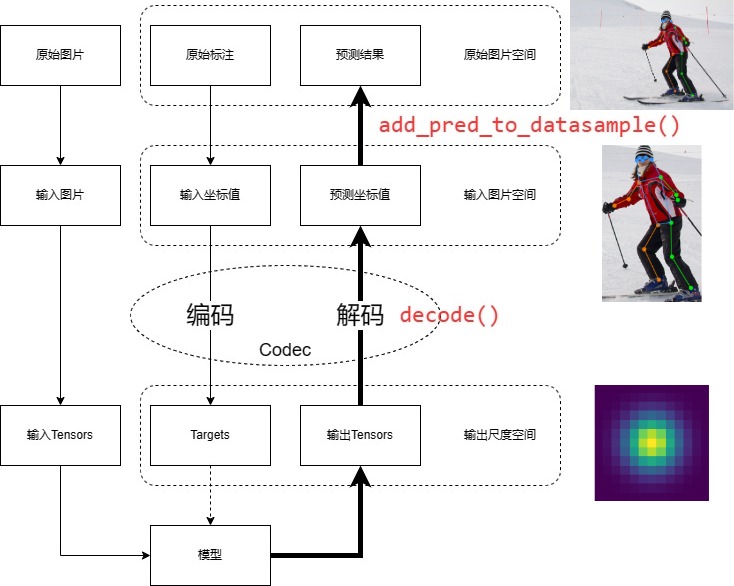
|
||
|
||
## 基本概念
|
||
|
||
一个编解码器主要包含两个部分:
|
||
|
||
- 编码器
|
||
- 解码器
|
||
|
||
### 编码器
|
||
|
||
编码器主要负责将处于输入图片尺度的坐标值,编码为模型训练所需要的目标格式,主要包括:
|
||
|
||
- 归一化的坐标值:用于 Regression-based 方法
|
||
- 一维向量:用于 SimCC-based 方法
|
||
- 高斯热图:用于 Heatmap-based 方法
|
||
|
||
以 Regression-based 方法的编码器为例:
|
||
|
||
```Python
|
||
def encode(self,
|
||
keypoints: np.ndarray,
|
||
keypoints_visible: Optional[np.ndarray] = None) -> dict:
|
||
"""Encoding keypoints from input image space to normalized space.
|
||
|
||
Args:
|
||
keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
|
||
keypoints_visible (np.ndarray): Keypoint visibilities in shape
|
||
(N, K)
|
||
|
||
Returns:
|
||
dict:
|
||
- keypoint_labels (np.ndarray): The normalized regression labels in
|
||
shape (N, K, D) where D is 2 for 2d coordinates
|
||
- keypoint_weights (np.ndarray): The target weights in shape
|
||
(N, K)
|
||
"""
|
||
if keypoints_visible is None:
|
||
keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
|
||
|
||
w, h = self.input_size
|
||
valid = ((keypoints >= 0) &
|
||
(keypoints <= [w - 1, h - 1])).all(axis=-1) & (
|
||
keypoints_visible > 0.5)
|
||
|
||
keypoint_labels = (keypoints / np.array([w, h])).astype(np.float32)
|
||
keypoint_weights = np.where(valid, 1., 0.).astype(np.float32)
|
||
|
||
encoded = dict(
|
||
keypoint_labels=keypoint_labels, keypoint_weights=keypoint_weights)
|
||
|
||
return encoded
|
||
```
|
||
|
||
编码后的数据会在 `PackPoseInputs` 中被转换为 Tensor 格式,并封装到 `data_sample.gt_instance_labels` 中供模型调用,默认包含以下的字段:
|
||
|
||
- `keypoint_labels`
|
||
- `keypoint_weights`
|
||
- `keypoints_visible_weights`
|
||
|
||
如要指定要打包的数据字段,可以在编解码器中定义 `label_mapping_table` 属性。例如,在 `VideoPoseLifting` 中:
|
||
|
||
```Python
|
||
label_mapping_table = dict(
|
||
trajectory_weights='trajectory_weights',
|
||
lifting_target_label='lifting_target_label',
|
||
lifting_target_weight='lifting_target_weight',
|
||
)
|
||
```
|
||
|
||
`data_sample.gt_instance_labels` 一般主要用于 loss 计算,下面以 `RegressionHead` 中的 `loss()` 为例:
|
||
|
||
```Python
|
||
def loss(self,
|
||
inputs: Tuple[Tensor],
|
||
batch_data_samples: OptSampleList,
|
||
train_cfg: ConfigType = {}) -> dict:
|
||
"""Calculate losses from a batch of inputs and data samples."""
|
||
|
||
pred_outputs = self.forward(inputs)
|
||
|
||
keypoint_labels = torch.cat(
|
||
[d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
|
||
keypoint_weights = torch.cat([
|
||
d.gt_instance_labels.keypoint_weights for d in batch_data_samples
|
||
])
|
||
|
||
# calculate losses
|
||
losses = dict()
|
||
loss = self.loss_module(pred_outputs, keypoint_labels,
|
||
keypoint_weights.unsqueeze(-1))
|
||
|
||
losses.update(loss_kpt=loss)
|
||
### 后续内容省略 ###
|
||
```
|
||
|
||
```{note}
|
||
解码器亦会定义封装在 `data_sample.gt_instances` 和 `data_sample.gt_fields` 中的字段。修改编码器中的 `instance_mapping_table` 和 `field_mapping_table` 的值将分别指定封装的字段,其中默认值定义在 [BaseKeypointCodec](https://github.com/open-mmlab/mmpose/blob/main/mmpose/codecs/base.py) 中。
|
||
```
|
||
|
||
### 解码器
|
||
|
||
解码器主要负责将模型的输出解码为输入图片尺度的坐标值,处理过程与编码器相反。
|
||
|
||
以 Regression-based 方法的解码器为例:
|
||
|
||
```Python
|
||
def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
|
||
"""Decode keypoint coordinates from normalized space to input image
|
||
space.
|
||
|
||
Args:
|
||
encoded (np.ndarray): Coordinates in shape (N, K, D)
|
||
|
||
Returns:
|
||
tuple:
|
||
- keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
|
||
- scores (np.ndarray): The keypoint scores in shape (N, K).
|
||
It usually represents the confidence of the keypoint prediction
|
||
|
||
"""
|
||
|
||
if encoded.shape[-1] == 2:
|
||
N, K, _ = encoded.shape
|
||
normalized_coords = encoded.copy()
|
||
scores = np.ones((N, K), dtype=np.float32)
|
||
elif encoded.shape[-1] == 4:
|
||
# split coords and sigma if outputs contain output_sigma
|
||
normalized_coords = encoded[..., :2].copy()
|
||
output_sigma = encoded[..., 2:4].copy()
|
||
scores = (1 - output_sigma).mean(axis=-1)
|
||
else:
|
||
raise ValueError(
|
||
'Keypoint dimension should be 2 or 4 (with sigma), '
|
||
f'but got {encoded.shape[-1]}')
|
||
|
||
w, h = self.input_size
|
||
keypoints = normalized_coords * np.array([w, h])
|
||
|
||
return keypoints, scores
|
||
```
|
||
|
||
默认情况下,`decode()` 方法只提供单个目标数据的解码过程,你也可以通过 `batch_decode()` 来实现批量解码提升执行效率。
|
||
|
||
## 常见用法
|
||
|
||
在 MMPose 配置文件中,主要有三处涉及编解码器:
|
||
|
||
- 定义编解码器
|
||
- 生成训练目标
|
||
- 模型头部
|
||
|
||
### 定义编解码器
|
||
|
||
以回归方法生成归一化的坐标值为例,在配置文件中,我们通过如下方式定义编解码器:
|
||
|
||
```Python
|
||
codec = dict(type='RegressionLabel', input_size=(192, 256))
|
||
```
|
||
|
||
### 生成训练目标
|
||
|
||
在数据处理阶段生成训练目标时,需要传入编解码器用于编码:
|
||
|
||
```Python
|
||
dict(type='GenerateTarget', encoder=codec)
|
||
```
|
||
|
||
### 模型头部
|
||
|
||
在 MMPose 中,我们在模型头部对模型的输出进行解码,需要传入编解码器用于解码:
|
||
|
||
```Python
|
||
head=dict(
|
||
type='RLEHead',
|
||
in_channels=2048,
|
||
num_joints=17,
|
||
loss=dict(type='RLELoss', use_target_weight=True),
|
||
decoder=codec
|
||
)
|
||
```
|
||
|
||
它们在配置文件中的具体位置如下:
|
||
|
||
```Python
|
||
|
||
# codec settings
|
||
codec = dict(type='RegressionLabel', input_size=(192, 256)) ## 定义 ##
|
||
|
||
# model settings
|
||
model = dict(
|
||
type='TopdownPoseEstimator',
|
||
data_preprocessor=dict(
|
||
type='PoseDataPreprocessor',
|
||
mean=[123.675, 116.28, 103.53],
|
||
std=[58.395, 57.12, 57.375],
|
||
bgr_to_rgb=True),
|
||
backbone=dict(
|
||
type='ResNet',
|
||
depth=50,
|
||
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
|
||
),
|
||
neck=dict(type='GlobalAveragePooling'),
|
||
head=dict(
|
||
type='RLEHead',
|
||
in_channels=2048,
|
||
num_joints=17,
|
||
loss=dict(type='RLELoss', use_target_weight=True),
|
||
decoder=codec), ## 模型头部 ##
|
||
test_cfg=dict(
|
||
flip_test=True,
|
||
shift_coords=True,
|
||
))
|
||
|
||
# base dataset settings
|
||
dataset_type = 'CocoDataset'
|
||
data_mode = 'topdown'
|
||
data_root = 'data/coco/'
|
||
|
||
backend_args = dict(backend='local')
|
||
|
||
# pipelines
|
||
train_pipeline = [
|
||
dict(type='LoadImage', backend_args=backend_args),
|
||
dict(type='GetBBoxCenterScale'),
|
||
dict(type='RandomFlip', direction='horizontal'),
|
||
dict(type='RandomHalfBody'),
|
||
dict(type='RandomBBoxTransform'),
|
||
dict(type='TopdownAffine', input_size=codec['input_size']),
|
||
dict(type='GenerateTarget', encoder=codec), ## 生成训练目标 ##
|
||
dict(type='PackPoseInputs')
|
||
]
|
||
test_pipeline = [
|
||
dict(type='LoadImage', backend_args=backend_args),
|
||
dict(type='GetBBoxCenterScale'),
|
||
dict(type='TopdownAffine', input_size=codec['input_size']),
|
||
dict(type='PackPoseInputs')
|
||
]
|
||
```
|
||
|
||
## 已支持编解码器列表
|
||
|
||
编解码器相关的代码位于 [$MMPOSE/mmpose/codecs/](https://github.com/open-mmlab/mmpose/tree/dev-1.x/mmpose/codecs)。目前 MMPose 已支持的编解码器如下所示:
|
||
|
||
- [RegressionLabel](#RegressionLabel)
|
||
- [IntegralRegressionLabel](#IntegralRegressionLabel)
|
||
- [MSRAHeatmap](#MSRAHeatmap)
|
||
- [UDPHeatmap](#UDPHeatmap)
|
||
- [MegviiHeatmap](#MegviiHeatmap)
|
||
- [SPR](#SPR)
|
||
- [SimCC](#SimCC)
|
||
- [DecoupledHeatmap](#DecoupledHeatmap)
|
||
- [ImagePoseLifting](#ImagePoseLifting)
|
||
- [VideoPoseLifting](#VideoPoseLifting)
|
||
- [MotionBERTLabel](#MotionBERTLabel)
|
||
|
||
### RegressionLabel
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/regression_label.py#L12)
|
||
|
||
RegressionLabel 编解码器主要用于 Regression-based 方法,适用于直接把坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为**归一化**的坐标值,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的归一化坐标值解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [DeepPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#deeppose-cvpr-2014)
|
||
- [RLE](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rle-iccv-2021)
|
||
|
||
### IntegralRegressionLabel
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/integral_regression_label.py)
|
||
|
||
IntegralRegressionLabel 编解码器主要用于 Integral Regression-based 方法,适用于把坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为**归一化**的坐标值,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的归一化坐标值解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#ipr-eccv-2018)
|
||
- [DSNT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dsnt-2018)
|
||
- [Debias IPR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#debias-ipr-iccv-2021)
|
||
|
||
### MSRAHeatmap
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/msra_heatmap.py)
|
||
|
||
MSRAHeatmap 编解码器主要用于 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [SimpleBaseline2D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline2d-eccv-2018)
|
||
- [CPM](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cpm-cvpr-2016)
|
||
- [HRNet](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#hrnet-cvpr-2019)
|
||
- [DARK](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#darkpose-cvpr-2020)
|
||
|
||
### UDPHeatmap
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/udp_heatmap.py)
|
||
|
||
UDPHeatmap 编解码器主要用于 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [UDP](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#udp-cvpr-2020)
|
||
|
||
### MegviiHeatmap
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/megvii_heatmap.py)
|
||
|
||
MegviiHeatmap 编解码器主要用于 Megvii 提出的 Heatmap-based 方法,适用于把高斯热图作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 2D 高斯分布解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [MSPN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#mspn-arxiv-2019)
|
||
- [RSN](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rsn-eccv-2020)
|
||
|
||
### SPR
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/spr.py)
|
||
|
||
SPR 编解码器主要用于 DEKR 方法,适用于同时使用中心 Heatmap 和偏移坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的中心关键点坐标值编码为 2D 离散高斯分布,以及相对于中心的偏移,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 2D 高斯分布与偏移进行组合,解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [DEKR](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#dekr-cvpr-2021)
|
||
|
||
### SimCC
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/simcc_label.py)
|
||
|
||
SimCC 编解码器主要用于 SimCC-based 方法,适用于两个 1D 离散分布表征的 x 和 y 坐标作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为水平和竖直方向 1D 离散分布,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 1D 离散分布解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [SimCC](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simcc-eccv-2022)
|
||
- [RTMPose](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#rtmpose-arxiv-2023)
|
||
|
||
### DecoupledHeatmap
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/decoupled_heatmap.py)
|
||
|
||
DecoupledHeatmap 编解码器主要用于 CID 方法,适用于把高斯热图作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的人体中心坐标值和关键点坐标值编码为 2D 离散高斯分布,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的人体中心与关键点 2D 高斯分布解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [CID](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#cid-cvpr-2022)
|
||
|
||
### ImagePoseLifting
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/image_pose_lifting.py)
|
||
|
||
ImagePoseLifting 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把单张图片的 2D 坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [SimpleBaseline3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#simplebaseline3d-iccv-2017)
|
||
|
||
### VideoPoseLifting
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/video_pose_lifting.py)
|
||
|
||
VideoPoseLifting 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把视频中一组 2D 坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [VideoPose3D](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo_papers/algorithms.html#videopose3d-cvpr-2019)
|
||
|
||
### MotionBERTLabel
|
||
|
||
[\[Github\]](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/codecs/motionbert_label.py)
|
||
|
||
MotionBERTLabel 编解码器主要用于 2D-to-3D pose lifting 方法,适用于把视频中一组 2D 坐标值作为训练目标的场景。
|
||
|
||
**输入:**
|
||
|
||
- 将**输入图片尺度**的坐标值编码为 3D 坐标空间归一化的坐标值,用于训练目标的生成。
|
||
|
||
**输出:**
|
||
|
||
- 将模型输出的 3D 坐标空间归一化的坐标值解码为**输入图片尺度**的坐标值。
|
||
|
||
常见的使用此编解码器的算法有:
|
||
|
||
- [MotionBERT](https://mmpose.readthedocs.io/zh_CN/dev-1.x/model_zoo/body_3d_keypoint.html#pose-lift-motionbert-on-h36m)
|