mirror of https://github.com/open-mmlab/mmpose
740 lines
33 KiB
Markdown
740 lines
33 KiB
Markdown
# A 20-minute Tour to MMPose
|
||
|
||
MMPose 1.0 is built upon a brand-new framework. For developers with basic knowledge of deep learning, this tutorial provides a overview of MMPose 1.0 framework design. Whether you are **a user of the previous version of MMPose**, or **a beginner of MMPose wishing to start with v1.0**, this tutorial will show you how to build a project based on MMPose 1.0.
|
||
|
||
```{note}
|
||
This tutorial covers what developers will concern when using MMPose 1.0:
|
||
|
||
- Overall code architecture
|
||
|
||
- How to manage modules with configs
|
||
|
||
- How to use my own custom datasets
|
||
|
||
- How to add new modules(backbone, head, loss function, etc.)
|
||
```
|
||
|
||
The content of this tutorial is organized as follows:
|
||
|
||
- [A 20 Minute Guide to MMPose Framework](#a-20-minute-guide-to-mmpose-framework)
|
||
- [Structure](#structure)
|
||
- [Overview](#overview)
|
||
- [Step1: Configs](#step1-configs)
|
||
- [Step2: Data](#step2-data)
|
||
- [Dataset Meta Information](#dataset-meta-information)
|
||
- [Dataset](#dataset)
|
||
- [Pipeline](#pipeline)
|
||
- [i. Augmentation](#i-augmentation)
|
||
- [ii. Transformation](#ii-transformation)
|
||
- [iii. Encoding](#iii-encoding)
|
||
- [iv. Packing](#iv-packing)
|
||
- [Step3: Model](#step3-model)
|
||
- [Data Preprocessor](#data-preprocessor)
|
||
- [Backbone](#backbone)
|
||
- [Neck](#neck)
|
||
- [Head](#head)
|
||
|
||
## Structure
|
||
|
||
The file structure of MMPose 1.0 is as follows:
|
||
|
||
```shell
|
||
mmpose
|
||
|----apis
|
||
|----structures
|
||
|----datasets
|
||
|----transforms
|
||
|----codecs
|
||
|----models
|
||
|----pose_estimators
|
||
|----data_preprocessors
|
||
|----backbones
|
||
|----necks
|
||
|----heads
|
||
|----losses
|
||
|----engine
|
||
|----hooks
|
||
|----evaluation
|
||
|----visualization
|
||
```
|
||
|
||
- **apis** provides high-level APIs for model inference
|
||
- **structures** provides data structures like bbox, keypoint and PoseDataSample
|
||
- **datasets** supports various datasets for pose estimation
|
||
- **transforms** contains a lot of useful data augmentation transforms
|
||
- **codecs** provides pose encoders and decoders: an encoder encodes poses (mostly keypoints) into learning targets (e.g. heatmaps), and a decoder decodes model outputs into pose predictions
|
||
- **models** provides all components of pose estimation models in a modular structure
|
||
- **pose_estimators** defines all pose estimation model classes
|
||
- **data_preprocessors** is for preprocessing the input data of the model
|
||
- **backbones** provides a collection of backbone networks
|
||
- **necks** contains various neck modules
|
||
- **heads** contains various prediction heads that perform pose estimation
|
||
- **losses** contains various loss functions
|
||
- **engine** provides runtime components related to pose estimation
|
||
- **hooks** provides various hooks of the runner
|
||
- **evaluation** provides metrics for evaluating model performance
|
||
- **visualization** is for visualizing skeletons, heatmaps and other information
|
||
|
||
## Overview
|
||
|
||

|
||
|
||
Generally speaking, there are **five parts** developers will use during project development:
|
||
|
||
- **General:** Environment, Hook, Checkpoint, Logger, etc.
|
||
|
||
- **Data:** Dataset, Dataloader, Data Augmentation, etc.
|
||
|
||
- **Training:** Optimizer, Learning Rate Scheduler, etc.
|
||
|
||
- **Model:** Backbone, Neck, Head, Loss function, etc.
|
||
|
||
- **Evaluation:** Metric, Evaluator, etc.
|
||
|
||
Among them, modules related to **General**, **Training** and **Evaluation** are often provided by the training framework [MMEngine](https://github.com/open-mmlab/mmengine), and developers only need to call APIs and adjust the parameters. Developers mainly focus on implementing the **Data** and **Model** parts.
|
||
|
||
## Step1: Configs
|
||
|
||
In MMPose, we use a Python file as config for the definition and parameter management of the whole project. Therefore, we strongly recommend the developers who use MMPose for the first time to refer to [Configs](./user_guides/configs.md).
|
||
|
||
Note that all new modules need to be registered using `Registry` and imported in `__init__.py` in the corresponding directory before we can create their instances from configs.
|
||
|
||
## Step2: Data
|
||
|
||
The organization of data in MMPose contains:
|
||
|
||
- Dataset Meta Information
|
||
- Dataset
|
||
- Pipeline
|
||
|
||
### Dataset Meta Information
|
||
|
||
The meta information of a pose dataset usually includes the definition of keypoints and skeleton, symmetrical characteristic, and keypoint properties (e.g. belonging to upper or lower body, weights and sigmas). These information is important in data preprocessing, model training and evaluation. In MMpose, the dataset meta information is stored in configs files under [$MMPOSE/configs/\_base\_/datasets](https://github.com/open-mmlab/mmpose/tree/main/configs/_base_/datasets).
|
||
|
||
To use a custom dataset in MMPose, you need to add a new config file of the dataset meta information. Take the MPII dataset ([$MMPOSE/configs/\_base\_/datasets/mpii.py](https://github.com/open-mmlab/mmpose/blob/main/configs/_base_/datasets/mpii.py)) as an example. Here is its dataset information:
|
||
|
||
```Python
|
||
dataset_info = dict(
|
||
dataset_name='mpii',
|
||
paper_info=dict(
|
||
author='Mykhaylo Andriluka and Leonid Pishchulin and '
|
||
'Peter Gehler and Schiele, Bernt',
|
||
title='2D Human Pose Estimation: New Benchmark and '
|
||
'State of the Art Analysis',
|
||
container='IEEE Conference on Computer Vision and '
|
||
'Pattern Recognition (CVPR)',
|
||
year='2014',
|
||
homepage='http://human-pose.mpi-inf.mpg.de/',
|
||
),
|
||
keypoint_info={
|
||
0:
|
||
dict(
|
||
name='right_ankle',
|
||
id=0,
|
||
color=[255, 128, 0],
|
||
type='lower',
|
||
swap='left_ankle'),
|
||
## omitted
|
||
},
|
||
skeleton_info={
|
||
0:
|
||
dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
|
||
## omitted
|
||
},
|
||
joint_weights=[
|
||
1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
|
||
],
|
||
# Adapted from COCO dataset.
|
||
sigmas=[
|
||
0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
|
||
0.062, 0.072, 0.179, 0.179, 0.072, 0.062
|
||
])
|
||
```
|
||
|
||
- `keypoint_info` contains the information about each keypoint.
|
||
1. `name`: the keypoint name. The keypoint name must be unique.
|
||
2. `id`: the keypoint id.
|
||
3. `color`: (\[B, G, R\]) is used for keypoint visualization.
|
||
4. `type`: 'upper' or 'lower', will be used in data augmentation [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L263).
|
||
5. `swap`: indicates the 'swap pair' (also known as 'flip pair'). When applying image horizontal flip, the left part will become the right part, used in data augmentation [RandomFlip](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py#L94). We need to flip the keypoints accordingly.
|
||
- `skeleton_info` contains information about the keypoint connectivity, which is used for visualization.
|
||
- `joint_weights` assigns different loss weights to different keypoints.
|
||
- `sigmas` is used to calculate the OKS score. You can read [keypoints-eval](https://cocodataset.org/#keypoints-eval) to learn more about it.
|
||
|
||
In the model config, the user needs to specify the metainfo path of the custom dataset (e.g. `$MMPOSE/configs/_base_/datasets/{your_dataset}.py`) as follows:
|
||
|
||
```python
|
||
# dataset and dataloader settings
|
||
dataset_type = 'MyCustomDataset' # or 'CocoDataset'
|
||
|
||
train_dataloader = dict(
|
||
batch_size=2,
|
||
dataset=dict(
|
||
type=dataset_type,
|
||
data_root='aaa',
|
||
# ann file is stored at {data_root}/{ann_file}
|
||
# e.g. aaa/annotations/train.json
|
||
ann_file='annotations/train.json',
|
||
# img is stored at {data_root}/{img}/
|
||
# e.g. aaa/train/c.jpg
|
||
data_prefix=dict(img='train'),
|
||
# specify the new dataset meta information config file
|
||
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
|
||
...),
|
||
)
|
||
|
||
val_dataloader = dict(
|
||
batch_size=2,
|
||
dataset=dict(
|
||
type=dataset_type,
|
||
data_root='aaa',
|
||
# ann file is stored at {data_root}/{ann_file}
|
||
# e.g. aaa/annotations/val.json
|
||
ann_file='annotations/val.json',
|
||
# img is stored at {data_root}/{img}/
|
||
# e.g. aaa/val/c.jpg
|
||
data_prefix=dict(img='val'),
|
||
# specify the new dataset meta information config file
|
||
metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
|
||
...),
|
||
)
|
||
|
||
test_dataloader = val_dataloader
|
||
```
|
||
|
||
More specifically speaking, if you organize your data as follows:
|
||
|
||
```shell
|
||
data
|
||
├── annotations
|
||
│ ├── train.json
|
||
│ ├── val.json
|
||
├── train
|
||
│ ├── images
|
||
│ │ ├── 000001.jpg
|
||
├── val
|
||
│ ├── images
|
||
│ │ ├── 000002.jpg
|
||
```
|
||
|
||
You need to set your config as follows:
|
||
|
||
```
|
||
dataset=dict(
|
||
...
|
||
data_root='data/',
|
||
ann_file='annotations/train.json',
|
||
data_prefix=dict(img='train/images/'),
|
||
...),
|
||
```
|
||
|
||
### Dataset
|
||
|
||
To use custom dataset in MMPose, we recommend converting the annotations into a supported format (e.g. COCO or MPII) and directly using our implementation of the corresponding dataset. If this is not applicable, you may need to implement your own dataset class.
|
||
|
||
More details about using custom datasets can be found in [Customize Datasets](./advanced_guides/customize_datasets.md).
|
||
|
||
```{note}
|
||
If you wish to inherit from the `BaseDataset` provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to this [documents](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) for details.
|
||
```
|
||
|
||
#### 2D Dataset
|
||
|
||
Most 2D keypoint datasets in MMPose **organize the annotations in a COCO-like style**. Thus we provide a base class [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) for these datasets. We recommend that users subclass [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 2D keypoint dataset.
|
||
|
||
```{note}
|
||
Please refer to [COCO](./dataset_zoo/2d_body_keypoint.md) for more details about the COCO data format.
|
||
```
|
||
|
||
The bbox format in MMPose is in `xyxy` instead of `xywh`, which is consistent with the format used in other OpenMMLab projects like [MMDetection](https://github.com/open-mmlab/mmdetection). We provide useful utils for bbox format conversion, such as `bbox_xyxy2xywh`, `bbox_xywh2xyxy`, `bbox_xyxy2cs`, etc., which are defined in [$MMPOSE/mmpose/structures/bbox/transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/structures/bbox/transforms.py).
|
||
|
||
Let's take the implementation of the CrowPose dataset ([$MMPOSE/mmpose/datasets/datasets/body/crowdpose_dataset.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/body/crowdpose_dataset.py)) in COCO format as an example.
|
||
|
||
```Python
|
||
@DATASETS.register_module()
|
||
class CrowdPoseDataset(BaseCocoStyleDataset):
|
||
"""CrowdPose dataset for pose estimation.
|
||
|
||
"CrowdPose: Efficient Crowded Scenes Pose Estimation and
|
||
A New Benchmark", CVPR'2019.
|
||
More details can be found in the `paper
|
||
<https://arxiv.org/abs/1812.00324>`__.
|
||
|
||
CrowdPose keypoints::
|
||
|
||
0: 'left_shoulder',
|
||
1: 'right_shoulder',
|
||
2: 'left_elbow',
|
||
3: 'right_elbow',
|
||
4: 'left_wrist',
|
||
5: 'right_wrist',
|
||
6: 'left_hip',
|
||
7: 'right_hip',
|
||
8: 'left_knee',
|
||
9: 'right_knee',
|
||
10: 'left_ankle',
|
||
11: 'right_ankle',
|
||
12: 'top_head',
|
||
13: 'neck'
|
||
|
||
Args:
|
||
ann_file (str): Annotation file path. Default: ''.
|
||
bbox_file (str, optional): Detection result file path. If
|
||
``bbox_file`` is set, detected bboxes loaded from this file will
|
||
be used instead of ground-truth bboxes. This setting is only for
|
||
evaluation, i.e., ignored when ``test_mode`` is ``False``.
|
||
Default: ``None``.
|
||
data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
|
||
``'bottomup'``. In ``'topdown'`` mode, each data sample contains
|
||
one instance; while in ``'bottomup'`` mode, each data sample
|
||
contains all instances in a image. Default: ``'topdown'``
|
||
metainfo (dict, optional): Meta information for dataset, such as class
|
||
information. Default: ``None``.
|
||
data_root (str, optional): The root directory for ``data_prefix`` and
|
||
``ann_file``. Default: ``None``.
|
||
data_prefix (dict, optional): Prefix for training data. Default:
|
||
``dict(img=None, ann=None)``.
|
||
filter_cfg (dict, optional): Config for filter data. Default: `None`.
|
||
indices (int or Sequence[int], optional): Support using first few
|
||
data in annotation file to facilitate training/testing on a smaller
|
||
dataset. Default: ``None`` which means using all ``data_infos``.
|
||
serialize_data (bool, optional): Whether to hold memory using
|
||
serialized objects, when enabled, data loader workers can use
|
||
shared RAM from master process instead of making a copy.
|
||
Default: ``True``.
|
||
pipeline (list, optional): Processing pipeline. Default: [].
|
||
test_mode (bool, optional): ``test_mode=True`` means in test phase.
|
||
Default: ``False``.
|
||
lazy_init (bool, optional): Whether to load annotation during
|
||
instantiation. In some cases, such as visualization, only the meta
|
||
information of the dataset is needed, which is not necessary to
|
||
load annotation file. ``Basedataset`` can skip load annotations to
|
||
save time by set ``lazy_init=False``. Default: ``False``.
|
||
max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
|
||
None img. The maximum extra number of cycles to get a valid
|
||
image. Default: 1000.
|
||
"""
|
||
|
||
METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')
|
||
```
|
||
|
||
For COCO-style datasets, we only need to inherit from [BaseCocoStyleDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_coco_style_dataset.py) and specify `METAINFO`, then the dataset class is ready to use.
|
||
|
||
#### 3D Dataset
|
||
|
||
we provide a base class [BaseMocapDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_mocap_dataset.py) for 3D datasets. We recommend that users subclass [BaseMocapDataset](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/datasets/base/base_mocap_dataset.py) and override the methods as needed (usually `__init__()` and `_load_annotations()`) to extend to a new custom 3D keypoint dataset.
|
||
|
||
### Pipeline
|
||
|
||
Data augmentations and transformations during pre-processing are organized as a pipeline. Here is an example of typical pipelines:
|
||
|
||
```Python
|
||
# pipelines
|
||
train_pipeline = [
|
||
dict(type='LoadImage'),
|
||
dict(type='GetBBoxCenterScale'),
|
||
dict(type='RandomFlip', direction='horizontal'),
|
||
dict(type='RandomHalfBody'),
|
||
dict(type='RandomBBoxTransform'),
|
||
dict(type='TopdownAffine', input_size=codec['input_size']),
|
||
dict(type='GenerateTarget', encoder=codec),
|
||
dict(type='PackPoseInputs')
|
||
]
|
||
test_pipeline = [
|
||
dict(type='LoadImage'),
|
||
dict(type='GetBBoxCenterScale'),
|
||
dict(type='TopdownAffine', input_size=codec['input_size']),
|
||
dict(type='PackPoseInputs')
|
||
]
|
||
```
|
||
|
||
In a keypoint detection task, data will be transformed among three scale spaces:
|
||
|
||
- **Original Image Space**: the space where the original images and annotations are stored. The sizes of different images are not necessarily the same
|
||
|
||
- **Input Image Space**: the image space used for model input. All **images** and **annotations** will be transformed into this space, such as `256x256`, `256x192`, etc.
|
||
|
||
- **Output Space**: the scale space where model outputs are located, such as `64x64(Heatmap)`,`1x1(Regression)`, etc. The supervision signal is also in this space during training
|
||
|
||
Here is a diagram to show the workflow of data transformation among the three scale spaces:
|
||
|
||
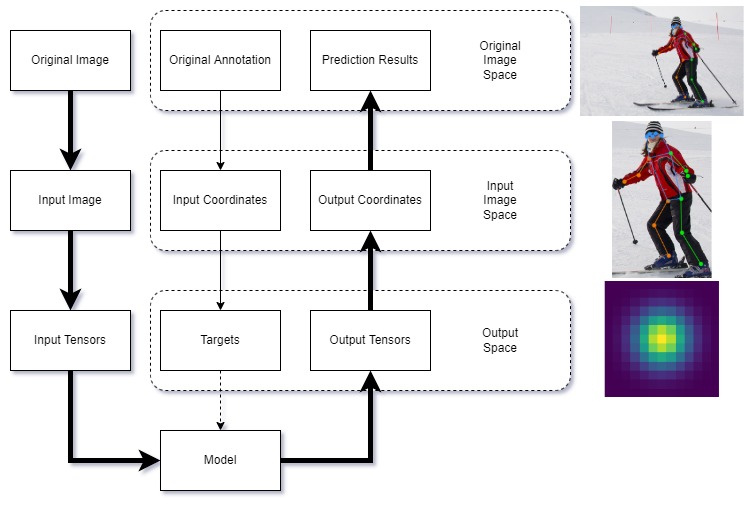
|
||
|
||
In MMPose, the modules used for data transformation are under [$MMPOSE/mmpose/datasets/transforms](https://github.com/open-mmlab/mmpose/tree/main/mmpose/datasets/transforms), and their workflow is shown as follows:
|
||
|
||

|
||
|
||
#### i. Augmentation
|
||
|
||
Commonly used transforms are defined in [$MMPOSE/mmpose/datasets/transforms/common_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/common_transforms.py), such as [RandomFlip](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L94), [RandomHalfBody](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L263), etc. For top-down methods, `Shift`, `Rotate`and `Resize` are implemented by [RandomBBoxTransform](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L433). For bottom-up methods, [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) is used.
|
||
|
||
Transforms for 3d pose data are defined in [$MMPOSE/mmpose/datasets/transforms/pose3d_transforms.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/pose3d_transforms.py)
|
||
|
||
```{note}
|
||
Most data transforms depend on `bbox_center` and `bbox_scale`, which can be obtained by [GetBBoxCenterScale](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L31).
|
||
```
|
||
|
||
#### ii. Transformation
|
||
|
||
For 2D image inputs, affine transformation is used to convert images and annotations from the original image space to the input space. This is done by [TopdownAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/topdown_transforms.py#L14) for top-down methods and [BottomupRandomAffine](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/bottomup_transforms.py#L134) for bottom-up methods.
|
||
|
||
For pose lifting tasks, transformation is merged into [Encoding](./guide_to_framework.md#iii-encoding).
|
||
|
||
#### iii. Encoding
|
||
|
||
In training phase, after the data is transformed from the original image space into the input space, it is necessary to use [GenerateTarget](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/datasets/transforms/common_transforms.py#L873) to obtain the training target(e.g. Gaussian Heatmaps). We name this process **Encoding**. Conversely, the process of getting the corresponding coordinates from Gaussian Heatmaps is called **Decoding**.
|
||
|
||
In MMPose, we collect Encoding and Decoding processes into a **Codec**, in which `encode()` and `decode()` are implemented.
|
||
|
||
Currently we support the following types of Targets.
|
||
|
||
- `heatmap`: Gaussian heatmaps
|
||
- `keypoint_label`: keypoint representation (e.g. normalized coordinates)
|
||
- `keypoint_xy_label`: axis-wise keypoint representation
|
||
- `heatmap+keypoint_label`: Gaussian heatmaps and keypoint representation
|
||
- `multiscale_heatmap`: multi-scale Gaussian heatmaps
|
||
- `lifting_target_label`: 3D lifting target keypoint representation
|
||
|
||
and the generated targets will be packed as follows.
|
||
|
||
- `heatmaps`: Gaussian heatmaps
|
||
- `keypoint_labels`: keypoint representation (e.g. normalized coordinates)
|
||
- `keypoint_x_labels`: keypoint x-axis representation
|
||
- `keypoint_y_labels`: keypoint y-axis representation
|
||
- `keypoint_weights`: keypoint visibility and weights
|
||
- `lifting_target_label`: 3D lifting target representation
|
||
- `lifting_target_weight`: 3D lifting target visibility and weights
|
||
|
||
Note that we unify the data format of top-down, pose-lifting and bottom-up methods, which means that a new dimension is added to represent different instances from the same image, in shape:
|
||
|
||
```Python
|
||
[batch_size, num_instances, num_keypoints, dim_coordinates]
|
||
```
|
||
|
||
- top-down and pose-lifting: `[B, 1, K, D]`
|
||
|
||
- bottom-up: `[B, N, K, D]`
|
||
|
||
The provided codecs are stored under [$MMPOSE/mmpose/codecs](https://github.com/open-mmlab/mmpose/tree/main/mmpose/codecs).
|
||
|
||
```{note}
|
||
If you wish to customize a new codec, you can refer to [Codec](./user_guides/codecs.md) for more details.
|
||
```
|
||
|
||
#### iv. Packing
|
||
|
||
After the data is transformed, you need to pack it using [PackPoseInputs](https://github.com/open-mmlab/mmpose/blob/main/mmpose/datasets/transforms/formatting.py).
|
||
|
||
This method converts the data stored in the dictionary `results` into standard data structures in MMPose, such as `InstanceData`, `PixelData`, [PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py), etc.
|
||
|
||
Specifically, we divide the data into `gt` (ground-truth) and `pred` (prediction), each of which has the following types:
|
||
|
||
- **instances**(numpy.array): instance-level raw annotations or predictions in the original scale space
|
||
- **instance_labels**(torch.tensor): instance-level training labels (e.g. normalized coordinates, keypoint visibility) in the output scale space
|
||
- **fields**(torch.tensor): pixel-level training labels or predictions (e.g. Gaussian Heatmaps) in the output scale space
|
||
|
||
The following is an example of the implementation of [PoseDataSample](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/structures/pose_data_sample.py) under the hood:
|
||
|
||
```Python
|
||
def get_pose_data_sample(self):
|
||
# meta
|
||
pose_meta = dict(
|
||
img_shape=(600, 900), # [h, w, c]
|
||
crop_size=(256, 192), # [h, w]
|
||
heatmap_size=(64, 48), # [h, w]
|
||
)
|
||
|
||
# gt_instances
|
||
gt_instances = InstanceData()
|
||
gt_instances.bboxes = np.random.rand(1, 4)
|
||
gt_instances.keypoints = np.random.rand(1, 17, 2)
|
||
|
||
# gt_instance_labels
|
||
gt_instance_labels = InstanceData()
|
||
gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
|
||
gt_instance_labels.keypoint_weights = torch.rand(1, 17)
|
||
|
||
# pred_instances
|
||
pred_instances = InstanceData()
|
||
pred_instances.keypoints = np.random.rand(1, 17, 2)
|
||
pred_instances.keypoint_scores = np.random.rand(1, 17)
|
||
|
||
# gt_fields
|
||
gt_fields = PixelData()
|
||
gt_fields.heatmaps = torch.rand(17, 64, 48)
|
||
|
||
# pred_fields
|
||
pred_fields = PixelData()
|
||
pred_fields.heatmaps = torch.rand(17, 64, 48)
|
||
data_sample = PoseDataSample(
|
||
gt_instances=gt_instances,
|
||
pred_instances=pred_instances,
|
||
gt_fields=gt_fields,
|
||
pred_fields=pred_fields,
|
||
metainfo=pose_meta)
|
||
|
||
return data_sample
|
||
```
|
||
|
||
## Step3: Model
|
||
|
||
In MMPose 1.0, the model consists of the following components:
|
||
|
||
- **Data Preprocessor**: perform data normalization and channel transposition
|
||
|
||
- **Backbone**: used for feature extraction
|
||
|
||
- **Neck**: GAP,FPN, etc. are optional
|
||
|
||
- **Head**: used to implement the core algorithm and loss function
|
||
|
||
We define a base class [BasePoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/base.py) for the model in [$MMPOSE/models/pose_estimators/base.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/pose_estimators/base.py). All models, e.g. [TopdownPoseEstimator](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/pose_estimators/topdown.py), should inherit from this base class and override the corresponding methods.
|
||
|
||
Three modes are provided in `forward()` of the estimator:
|
||
|
||
- `mode == 'loss'`: return the result of loss function for model training
|
||
|
||
- `mode == 'predict'`: return the prediction result in the input space, used for model inference
|
||
|
||
- `mode == 'tensor'`: return the model output in the output space, i.e. model forward propagation only, for model export
|
||
|
||
Developers should build the components by calling the corresponding registry. Taking the top-down model as an example:
|
||
|
||
```Python
|
||
@MODELS.register_module()
|
||
class TopdownPoseEstimator(BasePoseEstimator):
|
||
def __init__(self,
|
||
backbone: ConfigType,
|
||
neck: OptConfigType = None,
|
||
head: OptConfigType = None,
|
||
train_cfg: OptConfigType = None,
|
||
test_cfg: OptConfigType = None,
|
||
data_preprocessor: OptConfigType = None,
|
||
init_cfg: OptMultiConfig = None):
|
||
super().__init__(data_preprocessor, init_cfg)
|
||
|
||
self.backbone = MODELS.build(backbone)
|
||
|
||
if neck is not None:
|
||
self.neck = MODELS.build(neck)
|
||
|
||
if head is not None:
|
||
self.head = MODELS.build(head)
|
||
```
|
||
|
||
### Data Preprocessor
|
||
|
||
Starting from MMPose 1.0, we have added a new module to the model called data preprocessor, which performs data preprocessings like image normalization and channel transposition. It can benefit from the high computing power of devices like GPU, and improve the integrity in model export and deployment.
|
||
|
||
A typical `data_preprocessor` in the config is as follows:
|
||
|
||
```Python
|
||
data_preprocessor=dict(
|
||
type='PoseDataPreprocessor',
|
||
mean=[123.675, 116.28, 103.53],
|
||
std=[58.395, 57.12, 57.375],
|
||
bgr_to_rgb=True),
|
||
```
|
||
|
||
It will transpose the channel order of the input image from `bgr` to `rgb` and normalize the data according to `mean` and `std`.
|
||
|
||
### Backbone
|
||
|
||
MMPose provides some commonly used backbones under [$MMPOSE/mmpose/models/backbones](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/backbones).
|
||
|
||
In practice, developers often use pre-trained backbone weights for transfer learning, which can improve the performance of the model on small datasets.
|
||
|
||
In MMPose, you can use the pre-trained weights by setting `init_cfg` in config:
|
||
|
||
```Python
|
||
init_cfg=dict(
|
||
type='Pretrained',
|
||
checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
|
||
```
|
||
|
||
If you want to load a checkpoint to your backbone, you should specify the `prefix`:
|
||
|
||
```Python
|
||
init_cfg=dict(
|
||
type='Pretrained',
|
||
prefix='backbone.',
|
||
checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
|
||
```
|
||
|
||
`checkpoint` can be either a local path or a download link. Thus, if you wish to use a pre-trained model provided by Torchvision(e.g. ResNet50), you can simply use:
|
||
|
||
```Python
|
||
init_cfg=dict(
|
||
type='Pretrained',
|
||
checkpoint='torchvision://resnet50')
|
||
```
|
||
|
||
In addition to these commonly used backbones, you can easily use backbones from other repositories in the OpenMMLab family such as MMClassification, which all share the same config system and provide pre-trained weights.
|
||
|
||
It should be emphasized that if you add a new backbone, you need to register it by doing:
|
||
|
||
```Python
|
||
@MODELS.register_module()
|
||
class YourBackbone(BaseBackbone):
|
||
```
|
||
|
||
Besides, import it in [$MMPOSE/mmpose/models/backbones/\_\_init\_\_.py](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/backbones/__init__.py), and add it to `__all__`.
|
||
|
||
### Neck
|
||
|
||
Neck is usually a module between Backbone and Head, which is used in some algorithms. Here are some commonly used Neck:
|
||
|
||
- Global Average Pooling (GAP)
|
||
|
||
- Feature Pyramid Networks (FPN)
|
||
|
||
- Feature Map Processor (FMP)
|
||
|
||
The [FeatureMapProcessor](https://github.com/open-mmlab/mmpose/blob/dev-1.x/mmpose/models/necks/fmap_proc_neck.py) is a flexible PyTorch module designed to transform the feature outputs generated by backbones into a format suitable for heads. It achieves this by utilizing non-parametric operations such as selecting, concatenating, and rescaling. Below are some examples along with their corresponding configurations:
|
||
|
||
- Select operation
|
||
|
||
```python
|
||
neck=dict(type='FeatureMapProcessor', select_index=0)
|
||
```
|
||
|
||
<img src="https://user-images.githubusercontent.com/26127467/227108468-b44c9c13-9e51-403c-a035-b17b5268acc3.png" height="100px" alt><br>
|
||
|
||
- Concatenate operation
|
||
|
||
```python
|
||
neck=dict(type='FeatureMapProcessor', concat=True)
|
||
```
|
||
|
||
<img src="https://user-images.githubusercontent.com/26127467/227108705-4d197c71-4019-42cb-abdb-ba159111abb4.png" height="85px" alt><br>
|
||
|
||
Note that all feature maps will be resized to match the shape of the first feature map (index 0) prior to concatenation.
|
||
|
||
- rescale operation
|
||
|
||
```python
|
||
neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
|
||
```
|
||
|
||
<img src="https://user-images.githubusercontent.com/26127467/227109402-94106e4b-b941-4ce9-8201-c64920d82ed1.png" height="120px" alt><br>
|
||
|
||
### Head
|
||
|
||
Generally speaking, Head is often the core of an algorithm, which is used to make predictions and perform loss calculation.
|
||
|
||
Modules related to Head in MMPose are defined under [$MMPOSE/mmpose/models/heads](https://github.com/open-mmlab/mmpose/tree/main/mmpose/models/heads), and developers need to inherit the base class `BaseHead` when customizing Head and override the following methods:
|
||
|
||
- forward()
|
||
|
||
- predict()
|
||
|
||
- loss()
|
||
|
||
Specifically, `predict()` method needs to return pose predictions in the image space, which is obtained from the model output though the decoding function provided by the codec. We implement this process in [BaseHead.decode()](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/base_head.py).
|
||
|
||
On the other hand, we will perform test-time augmentation(TTA) in `predict()`.
|
||
|
||
A commonly used TTA is `flip_test`, namely, an image and its flipped version are sent into the model to inference, and the output of the flipped version will be flipped back, then average them to stabilize the prediction.
|
||
|
||
Here is an example of `predict()` in [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py):
|
||
|
||
```Python
|
||
def predict(self,
|
||
feats: Tuple[Tensor],
|
||
batch_data_samples: OptSampleList,
|
||
test_cfg: ConfigType = {}) -> Predictions:
|
||
"""Predict results from outputs."""
|
||
|
||
if test_cfg.get('flip_test', False):
|
||
# TTA: flip test -> feats = [orig, flipped]
|
||
assert isinstance(feats, list) and len(feats) == 2
|
||
flip_indices = batch_data_samples[0].metainfo['flip_indices']
|
||
input_size = batch_data_samples[0].metainfo['input_size']
|
||
_feats, _feats_flip = feats
|
||
_batch_coords = self.forward(_feats)
|
||
_batch_coords_flip = flip_coordinates(
|
||
self.forward(_feats_flip),
|
||
flip_indices=flip_indices,
|
||
shift_coords=test_cfg.get('shift_coords', True),
|
||
input_size=input_size)
|
||
batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
|
||
else:
|
||
batch_coords = self.forward(feats) # (B, K, D)
|
||
|
||
batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
|
||
preds = self.decode(batch_coords)
|
||
```
|
||
|
||
The `loss()` not only performs the calculation of loss functions, but also the calculation of training-time metrics such as pose accuracy. The results are carried by a dictionary `losses`:
|
||
|
||
```Python
|
||
# calculate accuracy
|
||
_, avg_acc, _ = keypoint_pck_accuracy(
|
||
pred=to_numpy(pred_coords),
|
||
gt=to_numpy(keypoint_labels),
|
||
mask=to_numpy(keypoint_weights) > 0,
|
||
thr=0.05,
|
||
norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
|
||
|
||
acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
|
||
losses.update(acc_pose=acc_pose)
|
||
```
|
||
|
||
The data of each batch is packaged into `batch_data_samples`. Taking the Regression-based method as an example, the normalized coordinates and keypoint weights can be obtained as follows:
|
||
|
||
```Python
|
||
keypoint_labels = torch.cat(
|
||
[d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
|
||
keypoint_weights = torch.cat([
|
||
d.gt_instance_labels.keypoint_weights for d in batch_data_samples
|
||
])
|
||
```
|
||
|
||
Here is the complete implementation of `loss()` in [RegressionHead](https://github.com/open-mmlab/mmpose/blob/main/mmpose/models/heads/regression_heads/regression_head.py):
|
||
|
||
```Python
|
||
def loss(self,
|
||
inputs: Tuple[Tensor],
|
||
batch_data_samples: OptSampleList,
|
||
train_cfg: ConfigType = {}) -> dict:
|
||
"""Calculate losses from a batch of inputs and data samples."""
|
||
|
||
pred_outputs = self.forward(inputs)
|
||
|
||
keypoint_labels = torch.cat(
|
||
[d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
|
||
keypoint_weights = torch.cat([
|
||
d.gt_instance_labels.keypoint_weights for d in batch_data_samples
|
||
])
|
||
|
||
# calculate losses
|
||
losses = dict()
|
||
loss = self.loss_module(pred_outputs, keypoint_labels,
|
||
keypoint_weights.unsqueeze(-1))
|
||
|
||
if isinstance(loss, dict):
|
||
losses.update(loss)
|
||
else:
|
||
losses.update(loss_kpt=loss)
|
||
|
||
# calculate accuracy
|
||
_, avg_acc, _ = keypoint_pck_accuracy(
|
||
pred=to_numpy(pred_outputs),
|
||
gt=to_numpy(keypoint_labels),
|
||
mask=to_numpy(keypoint_weights) > 0,
|
||
thr=0.05,
|
||
norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
|
||
acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
|
||
losses.update(acc_pose=acc_pose)
|
||
|
||
return losses
|
||
```
|
||
|
||
```{note}
|
||
If you wish to learn more about the implementation of Model, like:
|
||
- Head with Keypoints Visibility Prediction
|
||
- Pose Lifting Models
|
||
|
||
please refer to [Advanced Guides - Implement New Model](./advanced_guides/implement_new_models.md) for more details.
|
||
```
|