562 lines
22 KiB
Plaintext
562 lines
22 KiB
Plaintext
{
|
|
"cells": [
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"## Introduction\n",
|
|
"The transformers library is an open-source, community-based repository to train, use and share models based on \n",
|
|
"the Transformer architecture [(Vaswani & al., 2017)](https://arxiv.org/abs/1706.03762) such as Bert [(Devlin & al., 2018)](https://arxiv.org/abs/1810.04805),\n",
|
|
"Roberta [(Liu & al., 2019)](https://arxiv.org/abs/1907.11692), GPT2 [(Radford & al., 2019)](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),\n",
|
|
"XLNet [(Yang & al., 2019)](https://arxiv.org/abs/1906.08237), etc. \n",
|
|
"\n",
|
|
"Along with the models, the library contains multiple variations of each of them for a large variety of \n",
|
|
"downstream-tasks like **Named Entity Recognition (NER)**, **Sentiment Analysis**, \n",
|
|
"**Language Modeling**, **Question Answering** and so on.\n",
|
|
"\n",
|
|
"## Before Transformer\n",
|
|
"\n",
|
|
"Back to 2017, most of the people using Neural Networks when working on Natural Language Processing were relying on \n",
|
|
"sequential processing of the input through [Recurrent Neural Network (RNN)](https://en.wikipedia.org/wiki/Recurrent_neural_network).\n",
|
|
"\n",
|
|
"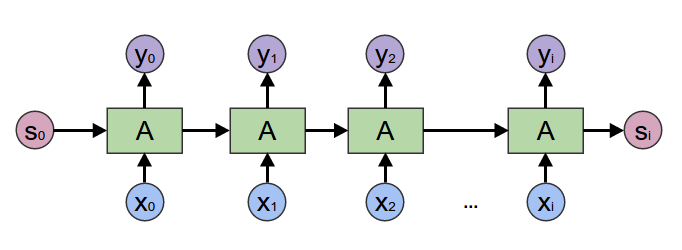 \n",
|
|
"\n",
|
|
"RNNs were performing well on large variety of tasks involving sequential dependency over the input sequence. \n",
|
|
"However, this sequentially-dependent process had issues modeling very long range dependencies and \n",
|
|
"was not well suited for the kind of hardware we're currently leveraging due to bad parallelization capabilities. \n",
|
|
"\n",
|
|
"Some extensions were provided by the academic community, such as Bidirectional RNN ([Schuster & Paliwal., 1997](https://www.researchgate.net/publication/3316656_Bidirectional_recurrent_neural_networks), [Graves & al., 2005](https://mediatum.ub.tum.de/doc/1290195/file.pdf)), \n",
|
|
"which can be seen as a concatenation of two sequential process, one going forward, the other one going backward over the sequence input.\n",
|
|
"\n",
|
|
"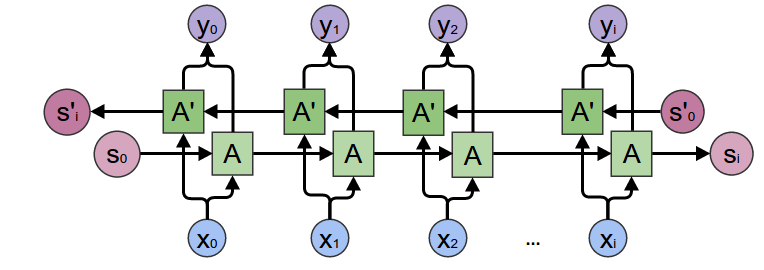\n",
|
|
"\n",
|
|
"\n",
|
|
"And also, the Attention mechanism, which introduced a good improvement over \"raw\" RNNs by giving \n",
|
|
"a learned, weighted-importance to each element in the sequence, allowing the model to focus on important elements.\n",
|
|
"\n",
|
|
" \n",
|
|
"\n",
|
|
"## Then comes the Transformer \n",
|
|
"\n",
|
|
"The Transformers era originally started from the work of [(Vaswani & al., 2017)](https://arxiv.org/abs/1706.03762) who\n",
|
|
"demonstrated its superiority over [Recurrent Neural Network (RNN)](https://en.wikipedia.org/wiki/Recurrent_neural_network)\n",
|
|
"on translation tasks but it quickly extended to almost all the tasks RNNs were State-of-the-Art at that time.\n",
|
|
"\n",
|
|
"One advantage of Transformer over its RNN counterpart was its non sequential attention model. Remember, the RNNs had to\n",
|
|
"iterate over each element of the input sequence one-by-one and carry an \"updatable-state\" between each hop. With Transformer, the model is able to look at every position in the sequence, at the same time, in one operation.\n",
|
|
"\n",
|
|
"For a deep-dive into the Transformer architecture, [The Annotated Transformer](https://nlp.seas.harvard.edu/2018/04/03/attention.html#encoder-and-decoder-stacks) \n",
|
|
"will drive you along all the details of the paper.\n",
|
|
"\n",
|
|
"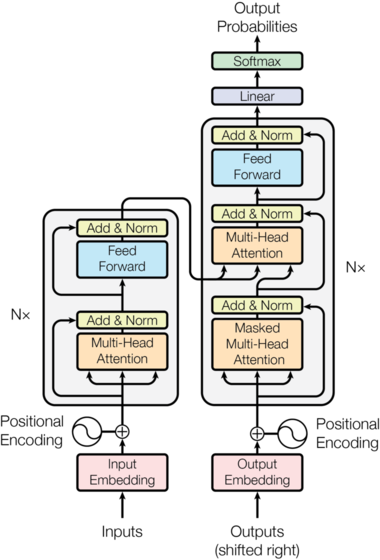"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"## Getting started with transformers\n",
|
|
"\n",
|
|
"For the rest of this notebook, we will use the [BERT (Devlin & al., 2018)](https://arxiv.org/abs/1810.04805) architecture, as it's the most simple and there are plenty of content about it\n",
|
|
"over the internet, it will be easy to dig more over this architecture if you want to.\n",
|
|
"\n",
|
|
"The transformers library allows you to benefits from large, pretrained language models without requiring a huge and costly computational\n",
|
|
"infrastructure. Most of the State-of-the-Art models are provided directly by their author and made available in the library \n",
|
|
"in PyTorch and TensorFlow in a transparent and interchangeable way. "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": null,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% code\n"
|
|
},
|
|
"scrolled": true
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"!pip install transformers\n",
|
|
"!pip install tensorflow==2.1.0"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 2,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% code\n"
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"data": {
|
|
"text/plain": [
|
|
"<torch.autograd.grad_mode.set_grad_enabled at 0x7f10b441e890>"
|
|
]
|
|
},
|
|
"execution_count": 2,
|
|
"metadata": {},
|
|
"output_type": "execute_result"
|
|
}
|
|
],
|
|
"source": [
|
|
"import torch\n",
|
|
"from transformers import AutoModel, AutoTokenizer, BertTokenizer\n",
|
|
"\n",
|
|
"torch.set_grad_enabled(False)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 3,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% code\n"
|
|
}
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"# Store the model we want to use\n",
|
|
"MODEL_NAME = \"bert-base-cased\"\n",
|
|
"\n",
|
|
"# We need to create the model and tokenizer\n",
|
|
"model = AutoModel.from_pretrained(MODEL_NAME)\n",
|
|
"tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"With only the above two lines of code, you're ready to use a BERT pre-trained model. \n",
|
|
"The tokenizers will allow us to map a raw textual input to a sequence of integers representing our textual input\n",
|
|
"in a way the model can manipulate."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 4,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% code\n"
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Tokens: ['This', 'is', 'an', 'input', 'example']\n",
|
|
"Tokens id: [1188, 1110, 1126, 7758, 1859]\n",
|
|
"Tokens PyTorch: tensor([[ 101, 1188, 1110, 1126, 7758, 1859, 102]])\n",
|
|
"Token wise output: torch.Size([1, 7, 768]), Pooled output: torch.Size([1, 768])\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Tokens comes from a process that splits the input into sub-entities with interesting linguistic properties. \n",
|
|
"tokens = tokenizer.tokenize(\"This is an input example\")\n",
|
|
"print(\"Tokens: {}\".format(tokens))\n",
|
|
"\n",
|
|
"# This is not sufficient for the model, as it requires integers as input, \n",
|
|
"# not a problem, let's convert tokens to ids.\n",
|
|
"tokens_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
|
|
"print(\"Tokens id: {}\".format(tokens_ids))\n",
|
|
"\n",
|
|
"# Add the required special tokens\n",
|
|
"tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)\n",
|
|
"\n",
|
|
"# We need to convert to a Deep Learning framework specific format, let's use PyTorch for now.\n",
|
|
"tokens_pt = torch.tensor([tokens_ids])\n",
|
|
"print(\"Tokens PyTorch: {}\".format(tokens_pt))\n",
|
|
"\n",
|
|
"# Now we're ready to go through BERT with out input\n",
|
|
"outputs, pooled = model(tokens_pt)\n",
|
|
"print(\"Token wise output: {}, Pooled output: {}\".format(outputs.shape, pooled.shape))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"As you can see, BERT outputs two tensors:\n",
|
|
" - One with the generated representation for every token in the input `(1, NB_TOKENS, REPRESENTATION_SIZE)`\n",
|
|
" - One with an aggregated representation for the whole input `(1, REPRESENTATION_SIZE)`\n",
|
|
" \n",
|
|
"The first, token-based, representation can be leveraged if your task requires to keep the sequence representation and you\n",
|
|
"want to operate at a token-level. This is particularly useful for Named Entity Recognition and Question-Answering.\n",
|
|
"\n",
|
|
"The second, aggregated, representation is especially useful if you need to extract the overall context of the sequence and don't\n",
|
|
"require a fine-grained token-level. This is the case for Sentiment-Analysis of the sequence or Information Retrieval."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"The code you saw in the previous section introduced all the steps required to do simple model invocation.\n",
|
|
"For more day-to-day usage, transformers provides you higher-level methods which will makes your NLP journey easier.\n",
|
|
"Let's improve our previous example"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 5,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false,
|
|
"name": "#%% code\n"
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"input_ids:\n",
|
|
"\ttensor([[ 101, 1188, 1110, 1126, 7758, 1859, 102]])\n",
|
|
"token_type_ids:\n",
|
|
"\ttensor([[0, 0, 0, 0, 0, 0, 0]])\n",
|
|
"attention_mask:\n",
|
|
"\ttensor([[1, 1, 1, 1, 1, 1, 1]])\n",
|
|
"Difference with previous code: (0.0, 0.0)\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# tokens = tokenizer.tokenize(\"This is an input example\")\n",
|
|
"# tokens_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
|
|
"# tokens_pt = torch.tensor([tokens_ids])\n",
|
|
"\n",
|
|
"# This code can be factored into one-line as follow\n",
|
|
"tokens_pt2 = tokenizer(\"This is an input example\", return_tensors=\"pt\")\n",
|
|
"\n",
|
|
"for key, value in tokens_pt2.items():\n",
|
|
" print(\"{}:\\n\\t{}\".format(key, value))\n",
|
|
"\n",
|
|
"outputs2, pooled2 = model(**tokens_pt2)\n",
|
|
"print(\"Difference with previous code: ({}, {})\".format((outputs2 - outputs).sum(), (pooled2 - pooled).sum()))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"As you can see above, calling the tokenizer provides a convenient way to generate all the required parameters\n",
|
|
"that will go through the model. \n",
|
|
"\n",
|
|
"Moreover, you might have noticed it generated some additional tensors: \n",
|
|
"\n",
|
|
"- token_type_ids: This tensor will map every tokens to their corresponding segment (see below).\n",
|
|
"- attention_mask: This tensor is used to \"mask\" padded values in a batch of sequence with different lengths (see below)."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 6,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Single segment token (str): ['[CLS]', 'This', 'is', 'a', 'sample', 'input', '[SEP]']\n",
|
|
"Single segment token (int): [101, 1188, 1110, 170, 6876, 7758, 102]\n",
|
|
"Single segment type : [0, 0, 0, 0, 0, 0, 0]\n",
|
|
"\n",
|
|
"Multi segment token (str): ['[CLS]', 'This', 'is', 'segment', 'A', '[SEP]', 'This', 'is', 'segment', 'B', '[SEP]']\n",
|
|
"Multi segment token (int): [101, 1188, 1110, 6441, 138, 102, 1188, 1110, 6441, 139, 102]\n",
|
|
"Multi segment type : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Single segment input\n",
|
|
"single_seg_input = tokenizer(\"This is a sample input\")\n",
|
|
"\n",
|
|
"# Multiple segment input\n",
|
|
"multi_seg_input = tokenizer(\"This is segment A\", \"This is segment B\")\n",
|
|
"\n",
|
|
"print(\"Single segment token (str): {}\".format(tokenizer.convert_ids_to_tokens(single_seg_input['input_ids'])))\n",
|
|
"print(\"Single segment token (int): {}\".format(single_seg_input['input_ids']))\n",
|
|
"print(\"Single segment type : {}\".format(single_seg_input['token_type_ids']))\n",
|
|
"\n",
|
|
"# Segments are concatened in the input to the model, with \n",
|
|
"print()\n",
|
|
"print(\"Multi segment token (str): {}\".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))\n",
|
|
"print(\"Multi segment token (int): {}\".format(multi_seg_input['input_ids']))\n",
|
|
"print(\"Multi segment type : {}\".format(multi_seg_input['token_type_ids']))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 7,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Tokens (int) : [101, 1188, 1110, 170, 6876, 102, 0, 0]\n",
|
|
"Tokens (str) : ['[CLS]', 'This', 'is', 'a', 'sample', '[SEP]', '[PAD]', '[PAD]']\n",
|
|
"Tokens (attn_mask): [1, 1, 1, 1, 1, 1, 0, 0]\n",
|
|
"\n",
|
|
"Tokens (int) : [101, 1188, 1110, 1330, 2039, 6876, 3087, 102]\n",
|
|
"Tokens (str) : ['[CLS]', 'This', 'is', 'another', 'longer', 'sample', 'text', '[SEP]']\n",
|
|
"Tokens (attn_mask): [1, 1, 1, 1, 1, 1, 1, 1]\n",
|
|
"\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Padding highlight\n",
|
|
"tokens = tokenizer(\n",
|
|
" [\"This is a sample\", \"This is another longer sample text\"], \n",
|
|
" padding=True # First sentence will have some PADDED tokens to match second sequence length\n",
|
|
")\n",
|
|
"\n",
|
|
"for i in range(2):\n",
|
|
" print(\"Tokens (int) : {}\".format(tokens['input_ids'][i]))\n",
|
|
" print(\"Tokens (str) : {}\".format([tokenizer.convert_ids_to_tokens(s) for s in tokens['input_ids'][i]]))\n",
|
|
" print(\"Tokens (attn_mask): {}\".format(tokens['attention_mask'][i]))\n",
|
|
" print()"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Frameworks interoperability\n",
|
|
"\n",
|
|
"One of the most powerfull feature of transformers is its ability to seamlessly move from PyTorch to Tensorflow\n",
|
|
"without pain for the user.\n",
|
|
"\n",
|
|
"We provide some convenient methods to load TensorFlow pretrained weight insinde a PyTorch model and opposite."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 8,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [],
|
|
"source": [
|
|
"from transformers import TFBertModel, BertModel\n",
|
|
"\n",
|
|
"# Let's load a BERT model for TensorFlow and PyTorch\n",
|
|
"model_tf = TFBertModel.from_pretrained('bert-base-cased')\n",
|
|
"model_pt = BertModel.from_pretrained('bert-base-cased')"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 9,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"output differences: 1.6236e-05\n",
|
|
"pooled differences: -1.3039e-08\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# transformers generates a ready to use dictionary with all the required parameters for the specific framework.\n",
|
|
"input_tf = tokenizer(\"This is a sample input\", return_tensors=\"tf\")\n",
|
|
"input_pt = tokenizer(\"This is a sample input\", return_tensors=\"pt\")\n",
|
|
"\n",
|
|
"# Let's compare the outputs\n",
|
|
"output_tf, output_pt = model_tf(input_tf), model_pt(**input_pt)\n",
|
|
"\n",
|
|
"# Models outputs 2 values (The value for each tokens, the pooled representation of the input sentence)\n",
|
|
"# Here we compare the output differences between PyTorch and TensorFlow.\n",
|
|
"for name, o_tf, o_pt in zip([\"output\", \"pooled\"], output_tf, output_pt):\n",
|
|
" print(\"{} differences: {:.5}\".format(name, (o_tf.numpy() - o_pt.numpy()).sum()))"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {
|
|
"pycharm": {
|
|
"name": "#%% md\n"
|
|
}
|
|
},
|
|
"source": [
|
|
"## Want it lighter? Faster? Let's talk distillation! \n",
|
|
"\n",
|
|
"One of the main concerns when using these Transformer based models is the computational power they require. All over this notebook we are using BERT model as it can be run on common machines but that's not the case for all of the models.\n",
|
|
"\n",
|
|
"For example, Google released a few months ago **T5** an Encoder/Decoder architecture based on Transformer and available in `transformers` with no more than 11 billions parameters. Microsoft also recently entered the game with **Turing-NLG** using 17 billions parameters. This kind of model requires tens of gigabytes to store the weights and a tremendous compute infrastructure to run such models which makes it impracticable for the common man !\n",
|
|
"\n",
|
|
"\n",
|
|
"\n",
|
|
"With the goal of making Transformer-based NLP accessible to everyone we @huggingface developed models that take advantage of a training process called **Distillation** which allows us to drastically reduce the resources needed to run such models with almost zero drop in performances.\n",
|
|
"\n",
|
|
"Going over the whole Distillation process is out of the scope of this notebook, but if you want more information on the subject you may refer to [this Medium article written by my colleague Victor SANH, author of DistilBERT paper](https://medium.com/huggingface/distilbert-8cf3380435b5), you might also want to directly have a look at the paper [(Sanh & al., 2019)](https://arxiv.org/abs/1910.01108)\n",
|
|
"\n",
|
|
"Of course, in `transformers` we have distilled some models and made them available directly in the library ! "
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 10,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"CPU times: user 232 ms, sys: 0 ns, total: 232 ms\n",
|
|
"Wall time: 21.1 ms\n",
|
|
"CPU times: user 511 ms, sys: 0 ns, total: 511 ms\n",
|
|
"Wall time: 43.9 ms\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"from transformers import DistilBertModel\n",
|
|
"\n",
|
|
"bert_distil = DistilBertModel.from_pretrained('distilbert-base-cased')\n",
|
|
"input_pt = tokenizer(\n",
|
|
" 'This is a sample input to demonstrate performance of distiled models especially inference time', \n",
|
|
" return_tensors=\"pt\"\n",
|
|
")\n",
|
|
"\n",
|
|
"\n",
|
|
"%time _ = bert_distil(input_pt['input_ids'])\n",
|
|
"%time _ = model_pt(input_pt['input_ids'])"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"## Community provided models\n",
|
|
"\n",
|
|
"Last but not least, earlier in this notebook we introduced Hugging Face `transformers` as a repository for the NLP community to exchange pretrained models. We wanted to highlight this features and all the possibilities it offers for the end-user.\n",
|
|
"\n",
|
|
"To leverage community pretrained models, just provide the organisation name and name of the model to `from_pretrained` and it will do all the magic for you ! \n",
|
|
"\n",
|
|
"\n",
|
|
"We currently have more 50 models provided by the community and more are added every day, don't hesitate to give it a try !"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"execution_count": 11,
|
|
"metadata": {
|
|
"pycharm": {
|
|
"is_executing": false
|
|
}
|
|
},
|
|
"outputs": [
|
|
{
|
|
"name": "stdout",
|
|
"output_type": "stream",
|
|
"text": [
|
|
"Tokens (int) : [102, 12272, 9355, 5746, 30881, 215, 261, 5945, 4118, 212, 2414, 153, 1942, 232, 3532, 566, 103]\n",
|
|
"Tokens (str) : ['[CLS]', 'Hug', '##ging', 'Fac', '##e', 'ist', 'eine', 'französische', 'Firma', 'mit', 'Sitz', 'in', 'New', '-', 'York', '.', '[SEP]']\n",
|
|
"Tokens (attn_mask): [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]\n",
|
|
"\n",
|
|
"Token wise output: torch.Size([1, 7, 768]), Pooled output: torch.Size([1, 768])\n"
|
|
]
|
|
}
|
|
],
|
|
"source": [
|
|
"# Let's load German BERT from the Bavarian State Library\n",
|
|
"de_bert = BertModel.from_pretrained(\"dbmdz/bert-base-german-cased\")\n",
|
|
"de_tokenizer = BertTokenizer.from_pretrained(\"dbmdz/bert-base-german-cased\")\n",
|
|
"\n",
|
|
"de_input = de_tokenizer(\n",
|
|
" \"Hugging Face ist eine französische Firma mit Sitz in New-York.\",\n",
|
|
" return_tensors=\"pt\"\n",
|
|
")\n",
|
|
"print(\"Tokens (int) : {}\".format(de_input['input_ids'].tolist()[0]))\n",
|
|
"print(\"Tokens (str) : {}\".format([de_tokenizer.convert_ids_to_tokens(s) for s in de_input['input_ids'].tolist()[0]]))\n",
|
|
"print(\"Tokens (attn_mask): {}\".format(de_input['attention_mask'].tolist()[0]))\n",
|
|
"print()\n",
|
|
"\n",
|
|
"output_de, pooled_de = de_bert(**de_input)\n",
|
|
"\n",
|
|
"print(\"Token wise output: {}, Pooled output: {}\".format(outputs.shape, pooled.shape))"
|
|
]
|
|
}
|
|
],
|
|
"metadata": {
|
|
"kernelspec": {
|
|
"display_name": "Python 3",
|
|
"language": "python",
|
|
"name": "python3"
|
|
},
|
|
"language_info": {
|
|
"codemirror_mode": {
|
|
"name": "ipython",
|
|
"version": 3
|
|
},
|
|
"file_extension": ".py",
|
|
"mimetype": "text/x-python",
|
|
"name": "python",
|
|
"nbconvert_exporter": "python",
|
|
"pygments_lexer": "ipython3",
|
|
"version": "3.7.4"
|
|
},
|
|
"pycharm": {
|
|
"stem_cell": {
|
|
"cell_type": "raw",
|
|
"metadata": {
|
|
"collapsed": false
|
|
},
|
|
"source": []
|
|
}
|
|
}
|
|
},
|
|
"nbformat": 4,
|
|
"nbformat_minor": 4
|
|
} |