diff --git a/README.md b/README.md
index 12b1b3314e..a2823ba6a4 100644
--- a/README.md
+++ b/README.md
@@ -262,6 +262,7 @@ Current number of checkpoints:  for a high-level summary of each them):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/README_es.md b/README_es.md
index af0f556d73..c768acaf4f 100644
--- a/README_es.md
+++ b/README_es.md
@@ -262,6 +262,7 @@ Número actual de puntos de control:  para un resumen de alto nivel de cada uno de ellas.):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/README_ja.md b/README_ja.md
index ddef823e58..3b47573f48 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -297,6 +297,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
🤗Transformersは現在、以下のアーキテクチャを提供しています(それぞれのハイレベルな要約は[こちら](https://huggingface.co/docs/transformers/model_summary)を参照してください):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/README_ko.md b/README_ko.md
index 5e660e1a2e..49bf203a4a 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -212,6 +212,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
🤗 Transformers는 다음 모델들을 제공합니다 (각 모델의 요약은 [여기](https://huggingface.co/docs/transformers/model_summary)서 확인하세요):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 78f19c374e..88bb1f45c8 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -236,6 +236,7 @@ conda install -c huggingface transformers
🤗 Transformers 目前支持如下的架构(模型概述请阅[这里](https://huggingface.co/docs/transformers/model_summary)):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (来自 Google Research and the Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (来自 MIT) 伴随论文 [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) 由 Yuan Gong, Yu-An Chung, James Glass 发布。
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (来自 Facebook) 伴随论文 [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) 由 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer 发布。
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (来自 École polytechnique) 伴随论文 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) 由 Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis 发布。
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (来自 VinAI Research) 伴随论文 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) 由 Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 9bc7c5a86c..ba55109e11 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -248,6 +248,7 @@ conda install -c huggingface transformers
🤗 Transformers 目前支援以下的架構(模型概覽請參閱[這裡](https://huggingface.co/docs/transformers/model_summary)):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/main/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 6d371c8dc2..79bb634e8d 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -447,6 +447,8 @@
title: Vision models
- isExpanded: false
sections:
+ - local: model_doc/audio-spectrogram-transformer
+ title: Audio Spectrogram Transformer
- local: model_doc/hubert
title: Hubert
- local: model_doc/mctct
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index d357b8eb62..790ce8f4d1 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -50,6 +50,7 @@ The documentation is organized into five sections:
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
@@ -216,150 +217,151 @@ Flax), PyTorch, and/or TensorFlow.
-| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
-|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
-| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
-| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
-| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
-| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
-| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
-| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
-| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
-| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
-| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
-| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
-| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
-| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
-| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
-| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
-| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
-| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
-| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
-| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
-| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
-| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
-| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
-| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
-| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
-| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
-| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
-| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
-| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
-| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
-| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
-| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
-| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
-| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
-| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
-| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
-| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
-| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
-| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
-| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
-| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
-| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
-| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
-| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
-| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
-| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
-| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
-| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
-| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
-| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
-| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
-| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
-| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
-| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
-| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
-| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
-| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
-| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
-| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
-| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
-| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
-| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
-| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
-| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
-| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
-| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
-| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
-| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
-| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
-| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
-| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
-| RegNet | ❌ | ❌ | ✅ | ✅ | ❌ |
-| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-| ResNet | ❌ | ❌ | ✅ | ✅ | ❌ |
-| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
-| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
-| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
-| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
-| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
-| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
-| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
-| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
-| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
-| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
-| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
-| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
-| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
-| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
-| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
-| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
-| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
-| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
-| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
-| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
-| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
-| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
-| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
-| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
-| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
-| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
-| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
-| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
-| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
-| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
-| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
-| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
-| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
-| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
-| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
-| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
-| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
+| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
+| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ❌ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ✅ | ❌ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
+| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
-
+
\ No newline at end of file
diff --git a/docs/source/en/model_doc/audio-spectrogram-transformer.mdx b/docs/source/en/model_doc/audio-spectrogram-transformer.mdx
new file mode 100644
index 0000000000..d6093198fc
--- /dev/null
+++ b/docs/source/en/model_doc/audio-spectrogram-transformer.mdx
@@ -0,0 +1,60 @@
+
+
+# Audio Spectrogram Transformer
+
+## Overview
+
+The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+The Audio Spectrogram Transformer applies a [Vision Transformer](vit) to audio, by turning audio into an image (spectrogram). The model obtains state-of-the-art results
+for audio classification.
+
+The abstract from the paper is the following:
+
+*In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.*
+
+Tips:
+
+- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
+sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
+mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
+the authors compute the stats for a downstream dataset.
+- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
+[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
+
+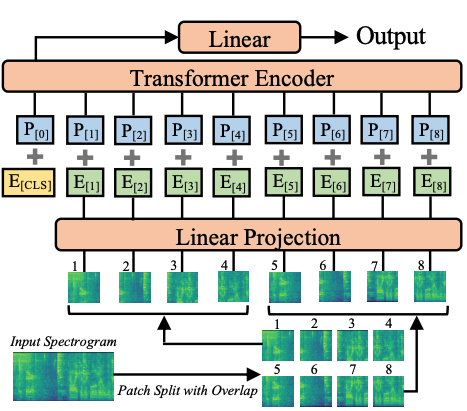 +
+ Audio pectrogram Transformer architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/YuanGongND/ast).
+
+
+## ASTConfig
+
+[[autodoc]] ASTConfig
+
+## ASTFeatureExtractor
+
+[[autodoc]] ASTFeatureExtractor
+ - __call__
+
+## ASTModel
+
+[[autodoc]] ASTModel
+ - forward
+
+## ASTForAudioClassification
+
+[[autodoc]] ASTForAudioClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 8afaa1e233..9c5f33bea5 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -122,6 +122,10 @@ _import_structure = {
"models": [],
# Models
"models.albert": ["ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "AlbertConfig"],
+ "models.audio_spectrogram_transformer": [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ASTConfig",
+ ],
"models.auto": [
"ALL_PRETRAINED_CONFIG_ARCHIVE_MAP",
"CONFIG_MAPPING",
@@ -673,6 +677,7 @@ except OptionalDependencyNotAvailable:
name for name in dir(dummy_speech_objects) if not name.startswith("_")
]
else:
+ _import_structure["models.audio_spectrogram_transformer"].append("ASTFeatureExtractor")
_import_structure["models.mctct"].append("MCTCTFeatureExtractor")
_import_structure["models.speech_to_text"].append("Speech2TextFeatureExtractor")
@@ -892,6 +897,14 @@ else:
"load_tf_weights_in_albert",
]
)
+ _import_structure["models.audio_spectrogram_transformer"].extend(
+ [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ASTModel",
+ "ASTPreTrainedModel",
+ "ASTForAudioClassification",
+ ]
+ )
_import_structure["models.auto"].extend(
[
"MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
@@ -3301,6 +3314,10 @@ if TYPE_CHECKING:
load_tf2_weights_in_pytorch_model,
)
from .models.albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig
+ from .models.audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ASTConfig,
+ )
from .models.auto import (
ALL_PRETRAINED_CONFIG_ARCHIVE_MAP,
CONFIG_MAPPING,
@@ -3798,6 +3815,7 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
from .utils.dummy_speech_objects import *
else:
+ from .models.audio_spectrogram_transformer import ASTFeatureExtractor
from .models.mctct import MCTCTFeatureExtractor
from .models.speech_to_text import Speech2TextFeatureExtractor
@@ -3954,6 +3972,12 @@ if TYPE_CHECKING:
AlbertPreTrainedModel,
load_tf_weights_in_albert,
)
+ from .models.audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ASTForAudioClassification,
+ ASTModel,
+ ASTPreTrainedModel,
+ )
from .models.auto import (
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_XVECTOR_MAPPING,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index ded3a4745b..d49d6699e0 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -18,6 +18,7 @@
from . import (
albert,
+ audio_spectrogram_transformer,
auto,
bart,
barthez,
diff --git a/src/transformers/models/audio_spectrogram_transformer/__init__.py b/src/transformers/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000..37fab5996a
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/__init__.py
@@ -0,0 +1,82 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_speech_available, is_torch_available
+
+
+_import_structure = {
+ "configuration_audio_spectrogram_transformer": [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ASTConfig",
+ ]
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_audio_spectrogram_transformer"] = [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ASTForAudioClassification",
+ "ASTModel",
+ "ASTPreTrainedModel",
+ ]
+
+try:
+ if not is_speech_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_audio_spectrogram_transformer"] = ["ASTFeatureExtractor"]
+
+if TYPE_CHECKING:
+ from .configuration_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ASTConfig,
+ )
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ASTForAudioClassification,
+ ASTModel,
+ ASTPreTrainedModel,
+ )
+
+ try:
+ if not is_speech_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_audio_spectrogram_transformer import ASTFeatureExtractor
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..19f85189ad
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
@@ -0,0 +1,126 @@
+# coding=utf-8
+# Copyright 2022 Google AI and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Audio Spectogram Transformer (AST) model configuration"""
+
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "MIT/ast-finetuned-audioset-10-10-0.4593": (
+ "https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593/resolve/main/config.json"
+ ),
+}
+
+
+class ASTConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ASTModel`]. It is used to instantiate an AST
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the AST
+ [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ patch_size (`int`, *optional*, defaults to `16`):
+ The size (resolution) of each patch.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ frequency_stride (`int`, *optional*, defaults to 10):
+ Frequency stride to use when patchifying the spectrograms.
+ time_stride (`int`, *optional*, defaults to 10):
+ Temporal stride to use when patchifying the spectrograms.
+ max_length (`int`, *optional*, defaults to 1024):
+ Temporal dimension of the spectrograms.
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Frequency dimension of the spectrograms (number of Mel-frequency bins).
+
+ Example:
+
+ ```python
+ >>> from transformers import ASTConfig, ASTModel
+
+ >>> # Initializing a AST MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> configuration = ASTConfig()
+
+ >>> # Initializing a model (with random weights) from the MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> model = ASTModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "audio-spectrogram-transformer"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ patch_size=16,
+ qkv_bias=True,
+ frequency_stride=10,
+ time_stride=10,
+ max_length=1024,
+ num_mel_bins=128,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.patch_size = patch_size
+ self.qkv_bias = qkv_bias
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
diff --git a/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py b/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
new file mode 100644
index 0000000000..f339bbc6c2
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
@@ -0,0 +1,279 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Audio Spectrogram Transformer checkpoints from the original repository. URL: https://github.com/YuanGongND/ast"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+import torchaudio
+from datasets import load_dataset
+
+from huggingface_hub import hf_hub_download
+from transformers import ASTConfig, ASTFeatureExtractor, ASTForAudioClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_audio_spectrogram_transformer_config(model_name):
+ config = ASTConfig()
+
+ if "10-10" in model_name:
+ pass
+ elif "speech-commands" in model_name:
+ config.max_length = 128
+ elif "12-12" in model_name:
+ config.time_stride = 12
+ config.frequency_stride = 12
+ elif "14-14" in model_name:
+ config.time_stride = 14
+ config.frequency_stride = 14
+ elif "16-16" in model_name:
+ config.time_stride = 16
+ config.frequency_stride = 16
+ else:
+ raise ValueError("Model not supported")
+
+ repo_id = "huggingface/label-files"
+ if "speech-commands" in model_name:
+ config.num_labels = 35
+ filename = "speech-commands-v2-id2label.json"
+ else:
+ config.num_labels = 527
+ filename = "audioset-id2label.json"
+
+ id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+def rename_key(name):
+ if "module.v" in name:
+ name = name.replace("module.v", "audio_spectrogram_transformer")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "embeddings.cls_token")
+ if "dist_token" in name:
+ name = name.replace("dist_token", "embeddings.distillation_token")
+ if "pos_embed" in name:
+ name = name.replace("pos_embed", "embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ # transformer blocks
+ if "blocks" in name:
+ name = name.replace("blocks", "encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ # final layernorm
+ if "audio_spectrogram_transformer.norm" in name:
+ name = name.replace("audio_spectrogram_transformer.norm", "audio_spectrogram_transformer.layernorm")
+ # classifier head
+ if "module.mlp_head.0" in name:
+ name = name.replace("module.mlp_head.0", "classifier.layernorm")
+ if "module.mlp_head.1" in name:
+ name = name.replace("module.mlp_head.1", "classifier.dense")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[3])
+ dim = config.hidden_size
+ if "weight" in key:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.weight"
+ ] = val[:dim, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.weight"
+ ] = val[dim : dim * 2, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.weight"
+ ] = val[-dim:, :]
+ else:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.bias"
+ ] = val[:dim]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.bias"
+ ] = val[dim : dim * 2]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.bias"
+ ] = val[-dim:]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+def remove_keys(state_dict):
+ ignore_keys = [
+ "module.v.head.weight",
+ "module.v.head.bias",
+ "module.v.head_dist.weight",
+ "module.v.head_dist.bias",
+ ]
+ for k in ignore_keys:
+ state_dict.pop(k, None)
+
+
+@torch.no_grad()
+def convert_audio_spectrogram_transformer_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our Audio Spectrogram Transformer structure.
+ """
+ config = get_audio_spectrogram_transformer_config(model_name)
+
+ model_name_to_url = {
+ "ast-finetuned-audioset-10-10-0.4593": (
+ "https://www.dropbox.com/s/ca0b1v2nlxzyeb4/audioset_10_10_0.4593.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.450": (
+ "https://www.dropbox.com/s/1tv0hovue1bxupk/audioset_10_10_0.4495.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448": (
+ "https://www.dropbox.com/s/6u5sikl4b9wo4u5/audioset_10_10_0.4483.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448-v2": (
+ "https://www.dropbox.com/s/kt6i0v9fvfm1mbq/audioset_10_10_0.4475.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-12-12-0.447": (
+ "https://www.dropbox.com/s/snfhx3tizr4nuc8/audioset_12_12_0.4467.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-14-14-0.443": (
+ "https://www.dropbox.com/s/z18s6pemtnxm4k7/audioset_14_14_0.4431.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-16-16-0.442": (
+ "https://www.dropbox.com/s/mdsa4t1xmcimia6/audioset_16_16_0.4422.pth?dl=1"
+ ),
+ "ast-finetuned-speech-commands-v2": (
+ "https://www.dropbox.com/s/q0tbqpwv44pquwy/speechcommands_10_10_0.9812.pth?dl=1"
+ ),
+ }
+
+ # load original state_dict
+ checkpoint_url = model_name_to_url[model_name]
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")
+ # remove some keys
+ remove_keys(state_dict)
+ # rename some keys
+ new_state_dict = convert_state_dict(state_dict, config)
+
+ # load 🤗 model
+ model = ASTForAudioClassification(config)
+ model.eval()
+
+ model.load_state_dict(new_state_dict)
+
+ # verify outputs on dummy input
+ # source: https://github.com/YuanGongND/ast/blob/79e873b8a54d0a3b330dd522584ff2b9926cd581/src/run.py#L62
+ mean = -4.2677393 if "speech-commands" not in model_name else -6.845978
+ std = 4.5689974 if "speech-commands" not in model_name else 5.5654526
+ max_length = 1024 if "speech-commands" not in model_name else 128
+ feature_extractor = ASTFeatureExtractor(mean=mean, std=std, max_length=max_length)
+
+ if "speech-commands" in model_name:
+ dataset = load_dataset("speech_commands", "v0.02", split="validation")
+ waveform = dataset[0]["audio"]["array"]
+ else:
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint",
+ filename="sample_audio.flac",
+ repo_type="dataset",
+ )
+
+ waveform, _ = torchaudio.load(filepath)
+ waveform = waveform.squeeze().numpy()
+
+ inputs = feature_extractor(waveform, sampling_rate=16000, return_tensors="pt")
+
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ if model_name == "ast-finetuned-audioset-10-10-0.4593":
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602])
+ elif model_name == "ast-finetuned-audioset-10-10-0.450":
+ expected_slice = torch.tensor([-1.1986, -7.0903, -8.2718])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448":
+ expected_slice = torch.tensor([-2.6128, -8.0080, -9.4344])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448-v2":
+ expected_slice = torch.tensor([-1.5080, -7.4534, -8.8917])
+ elif model_name == "ast-finetuned-audioset-12-12-0.447":
+ expected_slice = torch.tensor([-0.5050, -6.5833, -8.0843])
+ elif model_name == "ast-finetuned-audioset-14-14-0.443":
+ expected_slice = torch.tensor([-0.3826, -7.0336, -8.2413])
+ elif model_name == "ast-finetuned-audioset-16-16-0.442":
+ expected_slice = torch.tensor([-1.2113, -6.9101, -8.3470])
+ elif model_name == "ast-finetuned-speech-commands-v2":
+ expected_slice = torch.tensor([6.1589, -8.0566, -8.7984])
+ else:
+ raise ValueError("Unknown model name")
+ if not torch.allclose(logits[0, :3], expected_slice, atol=1e-4):
+ raise ValueError("Logits don't match")
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print("Pushing model and feature extractor to the hub...")
+ model.push_to_hub(f"MIT/{model_name}")
+ feature_extractor.push_to_hub(f"MIT/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="ast-finetuned-audioset-10-10-0.4593",
+ type=str,
+ help="Name of the Audio Spectrogram Transformer model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_audio_spectrogram_transformer_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..73041b7ae4
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,197 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Feature extractor class for Audio Spectrogram Transformer.
+"""
+
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+import torchaudio.compliance.kaldi as ta_kaldi
+
+from ...feature_extraction_sequence_utils import SequenceFeatureExtractor
+from ...feature_extraction_utils import BatchFeature
+from ...utils import TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class ASTFeatureExtractor(SequenceFeatureExtractor):
+ r"""
+ Constructs a Audio Spectrogram Transformer (AST) feature extractor.
+
+ This feature extractor inherits from [`~feature_extraction_sequence_utils.SequenceFeatureExtractor`] which contains
+ most of the main methods. Users should refer to this superclass for more information regarding those methods.
+
+ This class extracts mel-filter bank features from raw speech using TorchAudio, pads/truncates them to a fixed
+ length and normalizes them using a mean and standard deviation.
+
+ Args:
+ feature_size (`int`, *optional*, defaults to 1):
+ The feature dimension of the extracted features.
+ sampling_rate (`int`, *optional*, defaults to 16000):
+ The sampling rate at which the audio files should be digitalized expressed in Hertz per second (Hz).
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Number of Mel-frequency bins.
+ max_length (`int`, *optional*, defaults to 1024):
+ Maximum length to which to pad/truncate the extracted features.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the log-Mel features using `mean` and `std`.
+ mean (`float`, *optional*, defaults to -4.2677393):
+ The mean value used to normalize the log-Mel features. Uses the AudioSet mean by default.
+ std (`float`, *optional*, defaults to 4.5689974):
+ The standard deviation value used to normalize the log-Mel features. Uses the AudioSet standard deviation
+ by default.
+ return_attention_mask (`bool`, *optional*, defaults to `False`):
+ Whether or not [`~ASTFeatureExtractor.__call__`] should return `attention_mask`.
+ """
+
+ model_input_names = ["input_values", "attention_mask"]
+
+ def __init__(
+ self,
+ feature_size=1,
+ sampling_rate=16000,
+ num_mel_bins=128,
+ max_length=1024,
+ padding_value=0.0,
+ do_normalize=True,
+ mean=-4.2677393,
+ std=4.5689974,
+ return_attention_mask=False,
+ **kwargs
+ ):
+ super().__init__(feature_size=feature_size, sampling_rate=sampling_rate, padding_value=padding_value, **kwargs)
+ self.num_mel_bins = num_mel_bins
+ self.max_length = max_length
+ self.do_normalize = do_normalize
+ self.mean = mean
+ self.std = std
+ self.return_attention_mask = return_attention_mask
+
+ def _extract_fbank_features(
+ self,
+ waveform: np.ndarray,
+ max_length: int,
+ ) -> np.ndarray:
+ """
+ Get mel-filter bank features using TorchAudio. Note that TorchAudio requires 16-bit signed integers as inputs
+ and hence the waveform should not be normalized before feature extraction.
+ """
+ # waveform = waveform * (2**15) # Kaldi compliance: 16-bit signed integers
+ waveform = torch.from_numpy(waveform).unsqueeze(0)
+ fbank = ta_kaldi.fbank(
+ waveform,
+ htk_compat=True,
+ sample_frequency=self.sampling_rate,
+ use_energy=False,
+ window_type="hanning",
+ num_mel_bins=self.num_mel_bins,
+ dither=0.0,
+ frame_shift=10,
+ )
+
+ n_frames = fbank.shape[0]
+ difference = max_length - n_frames
+
+ # pad or truncate, depending on difference
+ if difference > 0:
+ pad_module = torch.nn.ZeroPad2d((0, 0, 0, difference))
+ fbank = pad_module(fbank)
+ elif difference < 0:
+ fbank = fbank[0:max_length, :]
+
+ fbank = fbank.numpy()
+
+ return fbank
+
+ def normalize(self, input_values: np.ndarray) -> np.ndarray:
+ return (input_values - (self.mean)) / (self.std * 2)
+
+ def __call__(
+ self,
+ raw_speech: Union[np.ndarray, List[float], List[np.ndarray], List[List[float]]],
+ sampling_rate: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to featurize and prepare for the model one or several sequence(s).
+
+ Args:
+ raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
+ The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
+ values, a list of numpy arrays or a list of list of float values.
+ sampling_rate (`int`, *optional*):
+ The sampling rate at which the `raw_speech` input was sampled. It is strongly recommended to pass
+ `sampling_rate` at the forward call to prevent silent errors.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+ """
+
+ if sampling_rate is not None:
+ if sampling_rate != self.sampling_rate:
+ raise ValueError(
+ f"The model corresponding to this feature extractor: {self} was trained using a sampling rate of"
+ f" {self.sampling_rate}. Please make sure that the provided `raw_speech` input was sampled with"
+ f" {self.sampling_rate} and not {sampling_rate}."
+ )
+ else:
+ logger.warning(
+ "It is strongly recommended to pass the `sampling_rate` argument to this function. "
+ "Failing to do so can result in silent errors that might be hard to debug."
+ )
+
+ is_batched = bool(
+ isinstance(raw_speech, (list, tuple))
+ and (isinstance(raw_speech[0], np.ndarray) or isinstance(raw_speech[0], (tuple, list)))
+ )
+
+ if is_batched:
+ raw_speech = [np.asarray(speech, dtype=np.float32) for speech in raw_speech]
+ elif not is_batched and not isinstance(raw_speech, np.ndarray):
+ raw_speech = np.asarray(raw_speech, dtype=np.float32)
+ elif isinstance(raw_speech, np.ndarray) and raw_speech.dtype is np.dtype(np.float64):
+ raw_speech = raw_speech.astype(np.float32)
+
+ # always return batch
+ if not is_batched:
+ raw_speech = [raw_speech]
+
+ # extract fbank features and pad/truncate to max_length
+ features = [self._extract_fbank_features(waveform, max_length=self.max_length) for waveform in raw_speech]
+
+ # convert into BatchFeature
+ padded_inputs = BatchFeature({"input_values": features})
+
+ # make sure list is in array format
+ input_values = padded_inputs.get("input_values")
+ if isinstance(input_values[0], list):
+ padded_inputs["input_values"] = [np.asarray(feature, dtype=np.float32) for feature in input_values]
+
+ # normalization
+ if self.do_normalize:
+ padded_inputs["input_values"] = [self.normalize(feature) for feature in input_values]
+
+ if return_tensors is not None:
+ padded_inputs = padded_inputs.convert_to_tensors(return_tensors)
+
+ return padded_inputs
diff --git a/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..6daec258b6
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,629 @@
+# coding=utf-8
+# Copyright 2022 MIT and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Audio Spectrogram Transformer (AST) model."""
+
+import math
+from typing import Dict, List, Optional, Set, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_audio_spectrogram_transformer import ASTConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ASTConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "ASTFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_EXPECTED_OUTPUT_SHAPE = [1, 1214, 768]
+
+# Audio classification docstring
+_SEQ_CLASS_CHECKPOINT = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_SEQ_CLASS_EXPECTED_OUTPUT = "'Speech'"
+_SEQ_CLASS_EXPECTED_LOSS = 0.17
+
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "MIT/ast-finetuned-audioset-10-10-0.4593",
+ # See all Audio Spectrogram Transformer models at https://huggingface.co/models?filter=ast
+]
+
+
+class ASTEmbeddings(nn.Module):
+ """
+ Construct the CLS token, position and patch embeddings.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.distillation_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.patch_embeddings = ASTPatchEmbeddings(config)
+
+ frequency_out_dimension, time_out_dimension = self.get_shape(config)
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 2, config.hidden_size))
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.config = config
+
+ def get_shape(self, config):
+ # see Karpathy's cs231n blog on how to calculate the output dimensions
+ # https://cs231n.github.io/convolutional-networks/#conv
+ frequency_out_dimension = (config.num_mel_bins - config.patch_size) // config.frequency_stride + 1
+ time_out_dimension = (config.max_length - config.patch_size) // config.time_stride + 1
+
+ return frequency_out_dimension, time_out_dimension
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ batch_size = input_values.shape[0]
+ embeddings = self.patch_embeddings(input_values)
+
+ cls_tokens = self.cls_token.expand(batch_size, -1, -1)
+ distillation_tokens = self.distillation_token.expand(batch_size, -1, -1)
+ embeddings = torch.cat((cls_tokens, distillation_tokens, embeddings), dim=1)
+ embeddings = embeddings + self.position_embeddings
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class ASTPatchEmbeddings(nn.Module):
+ """
+ This class turns `input_values` into the initial `hidden_states` (patch embeddings) of shape `(batch_size,
+ seq_length, hidden_size)` to be consumed by a Transformer.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ patch_size = config.patch_size
+ frequency_stride = config.frequency_stride
+ time_stride = config.time_stride
+
+ self.projection = nn.Conv2d(
+ 1, config.hidden_size, kernel_size=(patch_size, patch_size), stride=(frequency_stride, time_stride)
+ )
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ input_values = input_values.unsqueeze(1)
+ input_values = input_values.transpose(2, 3)
+ embeddings = self.projection(input_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViT->AST
+class ASTSelfAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->AST
+class ASTSelfOutput(nn.Module):
+ """
+ The residual connection is defined in ASTLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->AST
+class ASTAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.attention = ASTSelfAttention(config)
+ self.output = ASTSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->AST
+class ASTIntermediate(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->AST
+class ASTOutput(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->AST
+class ASTLayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = ASTAttention(config)
+ self.intermediate = ASTIntermediate(config)
+ self.output = ASTOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in AST, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in AST, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->AST
+class ASTEncoder(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([ASTLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class ASTPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ASTConfig
+ base_model_prefix = "audio_spectrogram_transformer"
+ main_input_name = "input_values"
+ supports_gradient_checkpointing = True
+
+ # Copied from transformers.models.vit.modeling_vit.ViTPreTrainedModel._init_weights
+ def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
+ # `trunc_normal_cpu` not implemented in `half` issues
+ module.weight.data = nn.init.trunc_normal_(
+ module.weight.data.to(torch.float32), mean=0.0, std=self.config.initializer_range
+ ).to(module.weight.dtype)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ # Copied from transformers.models.vit.modeling_vit.ViTPreTrainedModel._set_gradient_checkpointing with ViT->AST
+ def _set_gradient_checkpointing(self, module: ASTEncoder, value: bool = False) -> None:
+ if isinstance(module, ASTEncoder):
+ module.gradient_checkpointing = value
+
+
+AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ASTConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`ASTFeatureExtractor`]. See
+ [`ASTFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare AST Model transformer outputting raw hidden-states without any specific head on top.",
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTModel(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = ASTEmbeddings(config)
+ self.encoder = ASTEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> ASTPatchEmbeddings:
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_values is None:
+ raise ValueError("You have to specify input_values")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(input_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ pooled_output = (sequence_output[:, 0] + sequence_output[:, 1]) / 2
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class ASTMLPHead(nn.Module):
+ def __init__(self, config: ASTConfig):
+ super().__init__()
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dense = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
+
+ def forward(self, hidden_state):
+ hidden_state = self.layernorm(hidden_state)
+ hidden_state = self.dense(hidden_state)
+ return hidden_state
+
+
+@add_start_docstrings(
+ """
+ Audio Spectrogram Transformer model with an audio classification head on top (a linear layer on top of the pooled
+ output) e.g. for datasets like AudioSet, Speech Commands v2.
+ """,
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTForAudioClassification(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.audio_spectrogram_transformer = ASTModel(config)
+
+ # Classifier head
+ self.classifier = ASTMLPHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_SEQ_CLASS_CHECKPOINT,
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_SEQ_CLASS_EXPECTED_OUTPUT,
+ expected_loss=_SEQ_CLASS_EXPECTED_LOSS,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the audio classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.audio_spectrogram_transformer(
+ input_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index ac542bd14b..0ff1dd5671 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
("albert", "AlbertConfig"),
+ ("audio-spectrogram-transformer", "ASTConfig"),
("bart", "BartConfig"),
("beit", "BeitConfig"),
("bert", "BertConfig"),
@@ -179,6 +180,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here)
("albert", "ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("audio-spectrogram-transformer", "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("bart", "BART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("beit", "BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("bert", "BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -313,6 +315,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
("albert", "ALBERT"),
+ ("audio-spectrogram-transformer", "Audio Spectrogram Transformer"),
("bart", "BART"),
("barthez", "BARThez"),
("bartpho", "BARTpho"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 4042994228..3deb1d8384 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -37,6 +37,7 @@ logger = logging.get_logger(__name__)
FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
[
+ ("audio-spectrogram-transformer", "ASTFeatureExtractor"),
("beit", "BeitFeatureExtractor"),
("clip", "CLIPFeatureExtractor"),
("clipseg", "ViTFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 433e4f6338..7f9d11ce0d 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -29,6 +29,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
("albert", "AlbertModel"),
+ ("audio-spectrogram-transformer", "ASTModel"),
("bart", "BartModel"),
("beit", "BeitModel"),
("bert", "BertModel"),
@@ -784,6 +785,7 @@ MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
# Model for Audio Classification mapping
+ ("audio-spectrogram-transformer", "ASTForAudioClassification"),
("data2vec-audio", "Data2VecAudioForSequenceClassification"),
("hubert", "HubertForSequenceClassification"),
("sew", "SEWForSequenceClassification"),
diff --git a/src/transformers/utils/doc.py b/src/transformers/utils/doc.py
index a5610a32ba..360d98a460 100644
--- a/src/transformers/utils/doc.py
+++ b/src/transformers/utils/doc.py
@@ -1087,7 +1087,7 @@ def add_code_sample_docstrings(
expected_loss=expected_loss,
)
- if "SequenceClassification" in model_class and modality == "audio":
+ if ["SequenceClassification" in model_class or "AudioClassification" in model_class] and modality == "audio":
code_sample = sample_docstrings["AudioClassification"]
elif "SequenceClassification" in model_class:
code_sample = sample_docstrings["SequenceClassification"]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 8d9d1c9338..09ee78c849 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -350,6 +350,30 @@ def load_tf_weights_in_albert(*args, **kwargs):
requires_backends(load_tf_weights_in_albert, ["torch"])
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class ASTForAudioClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ASTModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ASTPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = None
diff --git a/src/transformers/utils/dummy_speech_objects.py b/src/transformers/utils/dummy_speech_objects.py
index ae5589292a..d1929dd285 100644
--- a/src/transformers/utils/dummy_speech_objects.py
+++ b/src/transformers/utils/dummy_speech_objects.py
@@ -3,6 +3,13 @@
from ..utils import DummyObject, requires_backends
+class ASTFeatureExtractor(metaclass=DummyObject):
+ _backends = ["speech"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["speech"])
+
+
class MCTCTFeatureExtractor(metaclass=DummyObject):
_backends = ["speech"]
diff --git a/tests/models/audio_spectrogram_transformer/__init__.py b/tests/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py b/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..cf6bb1d27f
--- /dev/null
+++ b/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,166 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import itertools
+import random
+import unittest
+
+import numpy as np
+
+from transformers import ASTFeatureExtractor
+from transformers.testing_utils import require_torch, require_torchaudio
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+global_rng = random.Random()
+
+if is_torch_available():
+ import torch
+
+
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+class ASTFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=1,
+ padding_value=0.0,
+ sampling_rate=16000,
+ return_attention_mask=True,
+ do_normalize=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.feature_size = feature_size
+ self.padding_value = padding_value
+ self.sampling_rate = sampling_rate
+ self.return_attention_mask = return_attention_mask
+ self.do_normalize = do_normalize
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "padding_value": self.padding_value,
+ "sampling_rate": self.sampling_rate,
+ "return_attention_mask": self.return_attention_mask,
+ "do_normalize": self.do_normalize,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = floats_list((self.batch_size, self.max_seq_length))
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ _flatten(floats_list((x, self.feature_size)))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+
+ return speech_inputs
+
+
+@require_torch
+@require_torchaudio
+class ASTFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+
+ feature_extraction_class = ASTFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = ASTFeatureExtractionTester(self)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # Test not batched input
+ encoded_sequences_1 = feat_extract(speech_inputs[0], return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs[0], return_tensors="np").input_values
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feat_extract(speech_inputs, padding=True, return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs, padding=True, return_tensors="np").input_values
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ @require_torch
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_values.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_values.dtype == torch.float32)
+
+ def _load_datasamples(self, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ @require_torch
+ def test_integration(self):
+ # fmt: off
+ EXPECTED_INPUT_VALUES = torch.tensor(
+ [-0.9894, -1.2776, -0.9066, -1.2776, -0.9349, -1.2609, -1.0386, -1.2776,
+ -1.1561, -1.2776, -1.2052, -1.2723, -1.2190, -1.2132, -1.2776, -1.1133,
+ -1.1953, -1.1343, -1.1584, -1.2203, -1.1770, -1.2474, -1.2381, -1.1936,
+ -0.9270, -0.8317, -0.8049, -0.7706, -0.7565, -0.7869]
+ )
+ # fmt: on
+
+ input_speech = self._load_datasamples(1)
+ feaure_extractor = ASTFeatureExtractor()
+ input_values = feaure_extractor(input_speech, return_tensors="pt").input_values
+ self.assertTrue(torch.allclose(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, atol=1e-4))
diff --git a/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..90d748ebea
--- /dev/null
+++ b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,247 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Audio Spectrogram Transformer (AST) model. """
+
+import inspect
+import unittest
+
+from huggingface_hub import hf_hub_download
+from transformers import ASTConfig
+from transformers.testing_utils import require_torch, require_torchaudio, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_torchaudio_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import ASTForAudioClassification, ASTModel
+ from transformers.models.audio_spectrogram_transformer.modeling_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ )
+
+
+if is_torchaudio_available():
+ import torchaudio
+
+ from transformers import ASTFeatureExtractor
+
+
+class ASTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ patch_size=2,
+ max_length=24,
+ num_mel_bins=16,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ scope=None,
+ frequency_stride=2,
+ time_stride=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.patch_size = patch_size
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+
+ # in AST, the seq length equals the number of patches + 2 (we add 2 for the [CLS] and distillation tokens)
+ frequency_out_dimension = (self.num_mel_bins - self.patch_size) // self.frequency_stride + 1
+ time_out_dimension = (self.max_length - self.patch_size) // self.time_stride + 1
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.seq_length = num_patches + 2
+
+ def prepare_config_and_inputs(self):
+ input_values = floats_tensor([self.batch_size, self.max_length, self.num_mel_bins])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, input_values, labels
+
+ def get_config(self):
+ return ASTConfig(
+ patch_size=self.patch_size,
+ max_length=self.max_length,
+ num_mel_bins=self.num_mel_bins,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ frequency_stride=self.frequency_stride,
+ time_stride=self.time_stride,
+ )
+
+ def create_and_check_model(self, config, input_values, labels):
+ model = ASTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_values,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_values": input_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ASTModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as AST does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ASTModel,
+ ASTForAudioClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ASTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ASTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="AST does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["input_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = ASTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on some audio from AudioSet
+def prepare_audio():
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint", filename="sample_audio.flac", repo_type="dataset"
+ )
+
+ audio, sampling_rate = torchaudio.load(filepath)
+
+ return audio, sampling_rate
+
+
+@require_torch
+@require_torchaudio
+class ASTModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return (
+ ASTFeatureExtractor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
+ if is_torchaudio_available()
+ else None
+ )
+
+ @slow
+ def test_inference_audio_classification(self):
+
+ feature_extractor = self.default_feature_extractor
+ model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ audio, sampling_rate = prepare_audio()
+ audio = audio.squeeze().numpy()
+ inputs = feature_extractor(audio, sampling_rate=sampling_rate, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 527))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
diff --git a/tests/pipelines/test_pipelines_common.py b/tests/pipelines/test_pipelines_common.py
index 492a63a4cc..5593da273b 100644
--- a/tests/pipelines/test_pipelines_common.py
+++ b/tests/pipelines/test_pipelines_common.py
@@ -155,6 +155,12 @@ def get_tiny_feature_extractor_from_checkpoint(checkpoint, tiny_config, feature_
if hasattr(tiny_config, "image_size") and feature_extractor:
feature_extractor = feature_extractor.__class__(size=tiny_config.image_size, crop_size=tiny_config.image_size)
+ # Audio Spectogram Transformer specific.
+ if feature_extractor.__class__.__name__ == "ASTFeatureExtractor":
+ feature_extractor = feature_extractor.__class__(
+ max_length=tiny_config.max_length, num_mel_bins=tiny_config.num_mel_bins
+ )
+
# Speech2TextModel specific.
if hasattr(tiny_config, "input_feat_per_channel") and feature_extractor:
feature_extractor = feature_extractor.__class__(
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index ac1772d853..2caba10588 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -91,6 +91,7 @@ if is_torch_available():
from test_module.custom_modeling import CustomModel, NoSuperInitModel
from transformers import (
BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_XVECTOR_MAPPING,
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
@@ -223,6 +224,7 @@ class ModelTesterMixin:
*get_values(MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING),
*get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
+ *get_values(MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 7616841929..f245fad7f8 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -18,6 +18,7 @@ src/transformers/generation/utils.py
src/transformers/models/albert/configuration_albert.py
src/transformers/models/albert/modeling_albert.py
src/transformers/models/albert/modeling_tf_albert.py
+src/transformers/models/audio_spectogram_transformer/modeling_audio_spectogram_transformer.py
src/transformers/models/bart/configuration_bart.py
src/transformers/models/bart/modeling_bart.py
src/transformers/models/beit/configuration_beit.py
+
+ Audio pectrogram Transformer architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/YuanGongND/ast).
+
+
+## ASTConfig
+
+[[autodoc]] ASTConfig
+
+## ASTFeatureExtractor
+
+[[autodoc]] ASTFeatureExtractor
+ - __call__
+
+## ASTModel
+
+[[autodoc]] ASTModel
+ - forward
+
+## ASTForAudioClassification
+
+[[autodoc]] ASTForAudioClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 8afaa1e233..9c5f33bea5 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -122,6 +122,10 @@ _import_structure = {
"models": [],
# Models
"models.albert": ["ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP", "AlbertConfig"],
+ "models.audio_spectrogram_transformer": [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ASTConfig",
+ ],
"models.auto": [
"ALL_PRETRAINED_CONFIG_ARCHIVE_MAP",
"CONFIG_MAPPING",
@@ -673,6 +677,7 @@ except OptionalDependencyNotAvailable:
name for name in dir(dummy_speech_objects) if not name.startswith("_")
]
else:
+ _import_structure["models.audio_spectrogram_transformer"].append("ASTFeatureExtractor")
_import_structure["models.mctct"].append("MCTCTFeatureExtractor")
_import_structure["models.speech_to_text"].append("Speech2TextFeatureExtractor")
@@ -892,6 +897,14 @@ else:
"load_tf_weights_in_albert",
]
)
+ _import_structure["models.audio_spectrogram_transformer"].extend(
+ [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ASTModel",
+ "ASTPreTrainedModel",
+ "ASTForAudioClassification",
+ ]
+ )
_import_structure["models.auto"].extend(
[
"MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
@@ -3301,6 +3314,10 @@ if TYPE_CHECKING:
load_tf2_weights_in_pytorch_model,
)
from .models.albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig
+ from .models.audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ASTConfig,
+ )
from .models.auto import (
ALL_PRETRAINED_CONFIG_ARCHIVE_MAP,
CONFIG_MAPPING,
@@ -3798,6 +3815,7 @@ if TYPE_CHECKING:
except OptionalDependencyNotAvailable:
from .utils.dummy_speech_objects import *
else:
+ from .models.audio_spectrogram_transformer import ASTFeatureExtractor
from .models.mctct import MCTCTFeatureExtractor
from .models.speech_to_text import Speech2TextFeatureExtractor
@@ -3954,6 +3972,12 @@ if TYPE_CHECKING:
AlbertPreTrainedModel,
load_tf_weights_in_albert,
)
+ from .models.audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ASTForAudioClassification,
+ ASTModel,
+ ASTPreTrainedModel,
+ )
from .models.auto import (
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_XVECTOR_MAPPING,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index ded3a4745b..d49d6699e0 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -18,6 +18,7 @@
from . import (
albert,
+ audio_spectrogram_transformer,
auto,
bart,
barthez,
diff --git a/src/transformers/models/audio_spectrogram_transformer/__init__.py b/src/transformers/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000..37fab5996a
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/__init__.py
@@ -0,0 +1,82 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_speech_available, is_torch_available
+
+
+_import_structure = {
+ "configuration_audio_spectrogram_transformer": [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "ASTConfig",
+ ]
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_audio_spectrogram_transformer"] = [
+ "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "ASTForAudioClassification",
+ "ASTModel",
+ "ASTPreTrainedModel",
+ ]
+
+try:
+ if not is_speech_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_audio_spectrogram_transformer"] = ["ASTFeatureExtractor"]
+
+if TYPE_CHECKING:
+ from .configuration_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ ASTConfig,
+ )
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ ASTForAudioClassification,
+ ASTModel,
+ ASTPreTrainedModel,
+ )
+
+ try:
+ if not is_speech_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_audio_spectrogram_transformer import ASTFeatureExtractor
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..19f85189ad
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
@@ -0,0 +1,126 @@
+# coding=utf-8
+# Copyright 2022 Google AI and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Audio Spectogram Transformer (AST) model configuration"""
+
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "MIT/ast-finetuned-audioset-10-10-0.4593": (
+ "https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593/resolve/main/config.json"
+ ),
+}
+
+
+class ASTConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ASTModel`]. It is used to instantiate an AST
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the AST
+ [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ patch_size (`int`, *optional*, defaults to `16`):
+ The size (resolution) of each patch.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ frequency_stride (`int`, *optional*, defaults to 10):
+ Frequency stride to use when patchifying the spectrograms.
+ time_stride (`int`, *optional*, defaults to 10):
+ Temporal stride to use when patchifying the spectrograms.
+ max_length (`int`, *optional*, defaults to 1024):
+ Temporal dimension of the spectrograms.
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Frequency dimension of the spectrograms (number of Mel-frequency bins).
+
+ Example:
+
+ ```python
+ >>> from transformers import ASTConfig, ASTModel
+
+ >>> # Initializing a AST MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> configuration = ASTConfig()
+
+ >>> # Initializing a model (with random weights) from the MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> model = ASTModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "audio-spectrogram-transformer"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ patch_size=16,
+ qkv_bias=True,
+ frequency_stride=10,
+ time_stride=10,
+ max_length=1024,
+ num_mel_bins=128,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.patch_size = patch_size
+ self.qkv_bias = qkv_bias
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
diff --git a/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py b/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
new file mode 100644
index 0000000000..f339bbc6c2
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
@@ -0,0 +1,279 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Audio Spectrogram Transformer checkpoints from the original repository. URL: https://github.com/YuanGongND/ast"""
+
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+import torchaudio
+from datasets import load_dataset
+
+from huggingface_hub import hf_hub_download
+from transformers import ASTConfig, ASTFeatureExtractor, ASTForAudioClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_audio_spectrogram_transformer_config(model_name):
+ config = ASTConfig()
+
+ if "10-10" in model_name:
+ pass
+ elif "speech-commands" in model_name:
+ config.max_length = 128
+ elif "12-12" in model_name:
+ config.time_stride = 12
+ config.frequency_stride = 12
+ elif "14-14" in model_name:
+ config.time_stride = 14
+ config.frequency_stride = 14
+ elif "16-16" in model_name:
+ config.time_stride = 16
+ config.frequency_stride = 16
+ else:
+ raise ValueError("Model not supported")
+
+ repo_id = "huggingface/label-files"
+ if "speech-commands" in model_name:
+ config.num_labels = 35
+ filename = "speech-commands-v2-id2label.json"
+ else:
+ config.num_labels = 527
+ filename = "audioset-id2label.json"
+
+ id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+def rename_key(name):
+ if "module.v" in name:
+ name = name.replace("module.v", "audio_spectrogram_transformer")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "embeddings.cls_token")
+ if "dist_token" in name:
+ name = name.replace("dist_token", "embeddings.distillation_token")
+ if "pos_embed" in name:
+ name = name.replace("pos_embed", "embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ # transformer blocks
+ if "blocks" in name:
+ name = name.replace("blocks", "encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ # final layernorm
+ if "audio_spectrogram_transformer.norm" in name:
+ name = name.replace("audio_spectrogram_transformer.norm", "audio_spectrogram_transformer.layernorm")
+ # classifier head
+ if "module.mlp_head.0" in name:
+ name = name.replace("module.mlp_head.0", "classifier.layernorm")
+ if "module.mlp_head.1" in name:
+ name = name.replace("module.mlp_head.1", "classifier.dense")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[3])
+ dim = config.hidden_size
+ if "weight" in key:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.weight"
+ ] = val[:dim, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.weight"
+ ] = val[dim : dim * 2, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.weight"
+ ] = val[-dim:, :]
+ else:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.bias"
+ ] = val[:dim]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.bias"
+ ] = val[dim : dim * 2]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.bias"
+ ] = val[-dim:]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+def remove_keys(state_dict):
+ ignore_keys = [
+ "module.v.head.weight",
+ "module.v.head.bias",
+ "module.v.head_dist.weight",
+ "module.v.head_dist.bias",
+ ]
+ for k in ignore_keys:
+ state_dict.pop(k, None)
+
+
+@torch.no_grad()
+def convert_audio_spectrogram_transformer_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our Audio Spectrogram Transformer structure.
+ """
+ config = get_audio_spectrogram_transformer_config(model_name)
+
+ model_name_to_url = {
+ "ast-finetuned-audioset-10-10-0.4593": (
+ "https://www.dropbox.com/s/ca0b1v2nlxzyeb4/audioset_10_10_0.4593.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.450": (
+ "https://www.dropbox.com/s/1tv0hovue1bxupk/audioset_10_10_0.4495.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448": (
+ "https://www.dropbox.com/s/6u5sikl4b9wo4u5/audioset_10_10_0.4483.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448-v2": (
+ "https://www.dropbox.com/s/kt6i0v9fvfm1mbq/audioset_10_10_0.4475.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-12-12-0.447": (
+ "https://www.dropbox.com/s/snfhx3tizr4nuc8/audioset_12_12_0.4467.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-14-14-0.443": (
+ "https://www.dropbox.com/s/z18s6pemtnxm4k7/audioset_14_14_0.4431.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-16-16-0.442": (
+ "https://www.dropbox.com/s/mdsa4t1xmcimia6/audioset_16_16_0.4422.pth?dl=1"
+ ),
+ "ast-finetuned-speech-commands-v2": (
+ "https://www.dropbox.com/s/q0tbqpwv44pquwy/speechcommands_10_10_0.9812.pth?dl=1"
+ ),
+ }
+
+ # load original state_dict
+ checkpoint_url = model_name_to_url[model_name]
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")
+ # remove some keys
+ remove_keys(state_dict)
+ # rename some keys
+ new_state_dict = convert_state_dict(state_dict, config)
+
+ # load 🤗 model
+ model = ASTForAudioClassification(config)
+ model.eval()
+
+ model.load_state_dict(new_state_dict)
+
+ # verify outputs on dummy input
+ # source: https://github.com/YuanGongND/ast/blob/79e873b8a54d0a3b330dd522584ff2b9926cd581/src/run.py#L62
+ mean = -4.2677393 if "speech-commands" not in model_name else -6.845978
+ std = 4.5689974 if "speech-commands" not in model_name else 5.5654526
+ max_length = 1024 if "speech-commands" not in model_name else 128
+ feature_extractor = ASTFeatureExtractor(mean=mean, std=std, max_length=max_length)
+
+ if "speech-commands" in model_name:
+ dataset = load_dataset("speech_commands", "v0.02", split="validation")
+ waveform = dataset[0]["audio"]["array"]
+ else:
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint",
+ filename="sample_audio.flac",
+ repo_type="dataset",
+ )
+
+ waveform, _ = torchaudio.load(filepath)
+ waveform = waveform.squeeze().numpy()
+
+ inputs = feature_extractor(waveform, sampling_rate=16000, return_tensors="pt")
+
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ if model_name == "ast-finetuned-audioset-10-10-0.4593":
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602])
+ elif model_name == "ast-finetuned-audioset-10-10-0.450":
+ expected_slice = torch.tensor([-1.1986, -7.0903, -8.2718])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448":
+ expected_slice = torch.tensor([-2.6128, -8.0080, -9.4344])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448-v2":
+ expected_slice = torch.tensor([-1.5080, -7.4534, -8.8917])
+ elif model_name == "ast-finetuned-audioset-12-12-0.447":
+ expected_slice = torch.tensor([-0.5050, -6.5833, -8.0843])
+ elif model_name == "ast-finetuned-audioset-14-14-0.443":
+ expected_slice = torch.tensor([-0.3826, -7.0336, -8.2413])
+ elif model_name == "ast-finetuned-audioset-16-16-0.442":
+ expected_slice = torch.tensor([-1.2113, -6.9101, -8.3470])
+ elif model_name == "ast-finetuned-speech-commands-v2":
+ expected_slice = torch.tensor([6.1589, -8.0566, -8.7984])
+ else:
+ raise ValueError("Unknown model name")
+ if not torch.allclose(logits[0, :3], expected_slice, atol=1e-4):
+ raise ValueError("Logits don't match")
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print("Pushing model and feature extractor to the hub...")
+ model.push_to_hub(f"MIT/{model_name}")
+ feature_extractor.push_to_hub(f"MIT/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="ast-finetuned-audioset-10-10-0.4593",
+ type=str,
+ help="Name of the Audio Spectrogram Transformer model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_audio_spectrogram_transformer_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..73041b7ae4
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,197 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Feature extractor class for Audio Spectrogram Transformer.
+"""
+
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+import torchaudio.compliance.kaldi as ta_kaldi
+
+from ...feature_extraction_sequence_utils import SequenceFeatureExtractor
+from ...feature_extraction_utils import BatchFeature
+from ...utils import TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class ASTFeatureExtractor(SequenceFeatureExtractor):
+ r"""
+ Constructs a Audio Spectrogram Transformer (AST) feature extractor.
+
+ This feature extractor inherits from [`~feature_extraction_sequence_utils.SequenceFeatureExtractor`] which contains
+ most of the main methods. Users should refer to this superclass for more information regarding those methods.
+
+ This class extracts mel-filter bank features from raw speech using TorchAudio, pads/truncates them to a fixed
+ length and normalizes them using a mean and standard deviation.
+
+ Args:
+ feature_size (`int`, *optional*, defaults to 1):
+ The feature dimension of the extracted features.
+ sampling_rate (`int`, *optional*, defaults to 16000):
+ The sampling rate at which the audio files should be digitalized expressed in Hertz per second (Hz).
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Number of Mel-frequency bins.
+ max_length (`int`, *optional*, defaults to 1024):
+ Maximum length to which to pad/truncate the extracted features.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the log-Mel features using `mean` and `std`.
+ mean (`float`, *optional*, defaults to -4.2677393):
+ The mean value used to normalize the log-Mel features. Uses the AudioSet mean by default.
+ std (`float`, *optional*, defaults to 4.5689974):
+ The standard deviation value used to normalize the log-Mel features. Uses the AudioSet standard deviation
+ by default.
+ return_attention_mask (`bool`, *optional*, defaults to `False`):
+ Whether or not [`~ASTFeatureExtractor.__call__`] should return `attention_mask`.
+ """
+
+ model_input_names = ["input_values", "attention_mask"]
+
+ def __init__(
+ self,
+ feature_size=1,
+ sampling_rate=16000,
+ num_mel_bins=128,
+ max_length=1024,
+ padding_value=0.0,
+ do_normalize=True,
+ mean=-4.2677393,
+ std=4.5689974,
+ return_attention_mask=False,
+ **kwargs
+ ):
+ super().__init__(feature_size=feature_size, sampling_rate=sampling_rate, padding_value=padding_value, **kwargs)
+ self.num_mel_bins = num_mel_bins
+ self.max_length = max_length
+ self.do_normalize = do_normalize
+ self.mean = mean
+ self.std = std
+ self.return_attention_mask = return_attention_mask
+
+ def _extract_fbank_features(
+ self,
+ waveform: np.ndarray,
+ max_length: int,
+ ) -> np.ndarray:
+ """
+ Get mel-filter bank features using TorchAudio. Note that TorchAudio requires 16-bit signed integers as inputs
+ and hence the waveform should not be normalized before feature extraction.
+ """
+ # waveform = waveform * (2**15) # Kaldi compliance: 16-bit signed integers
+ waveform = torch.from_numpy(waveform).unsqueeze(0)
+ fbank = ta_kaldi.fbank(
+ waveform,
+ htk_compat=True,
+ sample_frequency=self.sampling_rate,
+ use_energy=False,
+ window_type="hanning",
+ num_mel_bins=self.num_mel_bins,
+ dither=0.0,
+ frame_shift=10,
+ )
+
+ n_frames = fbank.shape[0]
+ difference = max_length - n_frames
+
+ # pad or truncate, depending on difference
+ if difference > 0:
+ pad_module = torch.nn.ZeroPad2d((0, 0, 0, difference))
+ fbank = pad_module(fbank)
+ elif difference < 0:
+ fbank = fbank[0:max_length, :]
+
+ fbank = fbank.numpy()
+
+ return fbank
+
+ def normalize(self, input_values: np.ndarray) -> np.ndarray:
+ return (input_values - (self.mean)) / (self.std * 2)
+
+ def __call__(
+ self,
+ raw_speech: Union[np.ndarray, List[float], List[np.ndarray], List[List[float]]],
+ sampling_rate: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to featurize and prepare for the model one or several sequence(s).
+
+ Args:
+ raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
+ The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
+ values, a list of numpy arrays or a list of list of float values.
+ sampling_rate (`int`, *optional*):
+ The sampling rate at which the `raw_speech` input was sampled. It is strongly recommended to pass
+ `sampling_rate` at the forward call to prevent silent errors.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+ """
+
+ if sampling_rate is not None:
+ if sampling_rate != self.sampling_rate:
+ raise ValueError(
+ f"The model corresponding to this feature extractor: {self} was trained using a sampling rate of"
+ f" {self.sampling_rate}. Please make sure that the provided `raw_speech` input was sampled with"
+ f" {self.sampling_rate} and not {sampling_rate}."
+ )
+ else:
+ logger.warning(
+ "It is strongly recommended to pass the `sampling_rate` argument to this function. "
+ "Failing to do so can result in silent errors that might be hard to debug."
+ )
+
+ is_batched = bool(
+ isinstance(raw_speech, (list, tuple))
+ and (isinstance(raw_speech[0], np.ndarray) or isinstance(raw_speech[0], (tuple, list)))
+ )
+
+ if is_batched:
+ raw_speech = [np.asarray(speech, dtype=np.float32) for speech in raw_speech]
+ elif not is_batched and not isinstance(raw_speech, np.ndarray):
+ raw_speech = np.asarray(raw_speech, dtype=np.float32)
+ elif isinstance(raw_speech, np.ndarray) and raw_speech.dtype is np.dtype(np.float64):
+ raw_speech = raw_speech.astype(np.float32)
+
+ # always return batch
+ if not is_batched:
+ raw_speech = [raw_speech]
+
+ # extract fbank features and pad/truncate to max_length
+ features = [self._extract_fbank_features(waveform, max_length=self.max_length) for waveform in raw_speech]
+
+ # convert into BatchFeature
+ padded_inputs = BatchFeature({"input_values": features})
+
+ # make sure list is in array format
+ input_values = padded_inputs.get("input_values")
+ if isinstance(input_values[0], list):
+ padded_inputs["input_values"] = [np.asarray(feature, dtype=np.float32) for feature in input_values]
+
+ # normalization
+ if self.do_normalize:
+ padded_inputs["input_values"] = [self.normalize(feature) for feature in input_values]
+
+ if return_tensors is not None:
+ padded_inputs = padded_inputs.convert_to_tensors(return_tensors)
+
+ return padded_inputs
diff --git a/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..6daec258b6
--- /dev/null
+++ b/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,629 @@
+# coding=utf-8
+# Copyright 2022 MIT and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Audio Spectrogram Transformer (AST) model."""
+
+import math
+from typing import Dict, List, Optional, Set, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_audio_spectrogram_transformer import ASTConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ASTConfig"
+_FEAT_EXTRACTOR_FOR_DOC = "ASTFeatureExtractor"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_EXPECTED_OUTPUT_SHAPE = [1, 1214, 768]
+
+# Audio classification docstring
+_SEQ_CLASS_CHECKPOINT = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_SEQ_CLASS_EXPECTED_OUTPUT = "'Speech'"
+_SEQ_CLASS_EXPECTED_LOSS = 0.17
+
+
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "MIT/ast-finetuned-audioset-10-10-0.4593",
+ # See all Audio Spectrogram Transformer models at https://huggingface.co/models?filter=ast
+]
+
+
+class ASTEmbeddings(nn.Module):
+ """
+ Construct the CLS token, position and patch embeddings.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.distillation_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.patch_embeddings = ASTPatchEmbeddings(config)
+
+ frequency_out_dimension, time_out_dimension = self.get_shape(config)
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 2, config.hidden_size))
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.config = config
+
+ def get_shape(self, config):
+ # see Karpathy's cs231n blog on how to calculate the output dimensions
+ # https://cs231n.github.io/convolutional-networks/#conv
+ frequency_out_dimension = (config.num_mel_bins - config.patch_size) // config.frequency_stride + 1
+ time_out_dimension = (config.max_length - config.patch_size) // config.time_stride + 1
+
+ return frequency_out_dimension, time_out_dimension
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ batch_size = input_values.shape[0]
+ embeddings = self.patch_embeddings(input_values)
+
+ cls_tokens = self.cls_token.expand(batch_size, -1, -1)
+ distillation_tokens = self.distillation_token.expand(batch_size, -1, -1)
+ embeddings = torch.cat((cls_tokens, distillation_tokens, embeddings), dim=1)
+ embeddings = embeddings + self.position_embeddings
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class ASTPatchEmbeddings(nn.Module):
+ """
+ This class turns `input_values` into the initial `hidden_states` (patch embeddings) of shape `(batch_size,
+ seq_length, hidden_size)` to be consumed by a Transformer.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ patch_size = config.patch_size
+ frequency_stride = config.frequency_stride
+ time_stride = config.time_stride
+
+ self.projection = nn.Conv2d(
+ 1, config.hidden_size, kernel_size=(patch_size, patch_size), stride=(frequency_stride, time_stride)
+ )
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ input_values = input_values.unsqueeze(1)
+ input_values = input_values.transpose(2, 3)
+ embeddings = self.projection(input_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViT->AST
+class ASTSelfAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->AST
+class ASTSelfOutput(nn.Module):
+ """
+ The residual connection is defined in ASTLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->AST
+class ASTAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.attention = ASTSelfAttention(config)
+ self.output = ASTSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->AST
+class ASTIntermediate(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->AST
+class ASTOutput(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->AST
+class ASTLayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = ASTAttention(config)
+ self.intermediate = ASTIntermediate(config)
+ self.output = ASTOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in AST, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in AST, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->AST
+class ASTEncoder(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([ASTLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class ASTPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ASTConfig
+ base_model_prefix = "audio_spectrogram_transformer"
+ main_input_name = "input_values"
+ supports_gradient_checkpointing = True
+
+ # Copied from transformers.models.vit.modeling_vit.ViTPreTrainedModel._init_weights
+ def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
+ # `trunc_normal_cpu` not implemented in `half` issues
+ module.weight.data = nn.init.trunc_normal_(
+ module.weight.data.to(torch.float32), mean=0.0, std=self.config.initializer_range
+ ).to(module.weight.dtype)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ # Copied from transformers.models.vit.modeling_vit.ViTPreTrainedModel._set_gradient_checkpointing with ViT->AST
+ def _set_gradient_checkpointing(self, module: ASTEncoder, value: bool = False) -> None:
+ if isinstance(module, ASTEncoder):
+ module.gradient_checkpointing = value
+
+
+AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ASTConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`ASTFeatureExtractor`]. See
+ [`ASTFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare AST Model transformer outputting raw hidden-states without any specific head on top.",
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTModel(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = ASTEmbeddings(config)
+ self.encoder = ASTEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> ASTPatchEmbeddings:
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_values is None:
+ raise ValueError("You have to specify input_values")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(input_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ pooled_output = (sequence_output[:, 0] + sequence_output[:, 1]) / 2
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class ASTMLPHead(nn.Module):
+ def __init__(self, config: ASTConfig):
+ super().__init__()
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dense = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
+
+ def forward(self, hidden_state):
+ hidden_state = self.layernorm(hidden_state)
+ hidden_state = self.dense(hidden_state)
+ return hidden_state
+
+
+@add_start_docstrings(
+ """
+ Audio Spectrogram Transformer model with an audio classification head on top (a linear layer on top of the pooled
+ output) e.g. for datasets like AudioSet, Speech Commands v2.
+ """,
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTForAudioClassification(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.audio_spectrogram_transformer = ASTModel(config)
+
+ # Classifier head
+ self.classifier = ASTMLPHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_FEAT_EXTRACTOR_FOR_DOC,
+ checkpoint=_SEQ_CLASS_CHECKPOINT,
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_SEQ_CLASS_EXPECTED_OUTPUT,
+ expected_loss=_SEQ_CLASS_EXPECTED_LOSS,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the audio classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.audio_spectrogram_transformer(
+ input_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index ac542bd14b..0ff1dd5671 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -30,6 +30,7 @@ CONFIG_MAPPING_NAMES = OrderedDict(
[
# Add configs here
("albert", "AlbertConfig"),
+ ("audio-spectrogram-transformer", "ASTConfig"),
("bart", "BartConfig"),
("beit", "BeitConfig"),
("bert", "BertConfig"),
@@ -179,6 +180,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
[
# Add archive maps here)
("albert", "ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("audio-spectrogram-transformer", "AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("bart", "BART_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("beit", "BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("bert", "BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -313,6 +315,7 @@ MODEL_NAMES_MAPPING = OrderedDict(
[
# Add full (and cased) model names here
("albert", "ALBERT"),
+ ("audio-spectrogram-transformer", "Audio Spectrogram Transformer"),
("bart", "BART"),
("barthez", "BARThez"),
("bartpho", "BARTpho"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 4042994228..3deb1d8384 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -37,6 +37,7 @@ logger = logging.get_logger(__name__)
FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
[
+ ("audio-spectrogram-transformer", "ASTFeatureExtractor"),
("beit", "BeitFeatureExtractor"),
("clip", "CLIPFeatureExtractor"),
("clipseg", "ViTFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 433e4f6338..7f9d11ce0d 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -29,6 +29,7 @@ MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
("albert", "AlbertModel"),
+ ("audio-spectrogram-transformer", "ASTModel"),
("bart", "BartModel"),
("beit", "BeitModel"),
("bert", "BertModel"),
@@ -784,6 +785,7 @@ MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
# Model for Audio Classification mapping
+ ("audio-spectrogram-transformer", "ASTForAudioClassification"),
("data2vec-audio", "Data2VecAudioForSequenceClassification"),
("hubert", "HubertForSequenceClassification"),
("sew", "SEWForSequenceClassification"),
diff --git a/src/transformers/utils/doc.py b/src/transformers/utils/doc.py
index a5610a32ba..360d98a460 100644
--- a/src/transformers/utils/doc.py
+++ b/src/transformers/utils/doc.py
@@ -1087,7 +1087,7 @@ def add_code_sample_docstrings(
expected_loss=expected_loss,
)
- if "SequenceClassification" in model_class and modality == "audio":
+ if ["SequenceClassification" in model_class or "AudioClassification" in model_class] and modality == "audio":
code_sample = sample_docstrings["AudioClassification"]
elif "SequenceClassification" in model_class:
code_sample = sample_docstrings["SequenceClassification"]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 8d9d1c9338..09ee78c849 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -350,6 +350,30 @@ def load_tf_weights_in_albert(*args, **kwargs):
requires_backends(load_tf_weights_in_albert, ["torch"])
+AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class ASTForAudioClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ASTModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ASTPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = None
diff --git a/src/transformers/utils/dummy_speech_objects.py b/src/transformers/utils/dummy_speech_objects.py
index ae5589292a..d1929dd285 100644
--- a/src/transformers/utils/dummy_speech_objects.py
+++ b/src/transformers/utils/dummy_speech_objects.py
@@ -3,6 +3,13 @@
from ..utils import DummyObject, requires_backends
+class ASTFeatureExtractor(metaclass=DummyObject):
+ _backends = ["speech"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["speech"])
+
+
class MCTCTFeatureExtractor(metaclass=DummyObject):
_backends = ["speech"]
diff --git a/tests/models/audio_spectrogram_transformer/__init__.py b/tests/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py b/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..cf6bb1d27f
--- /dev/null
+++ b/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,166 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import itertools
+import random
+import unittest
+
+import numpy as np
+
+from transformers import ASTFeatureExtractor
+from transformers.testing_utils import require_torch, require_torchaudio
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+global_rng = random.Random()
+
+if is_torch_available():
+ import torch
+
+
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+class ASTFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=1,
+ padding_value=0.0,
+ sampling_rate=16000,
+ return_attention_mask=True,
+ do_normalize=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.feature_size = feature_size
+ self.padding_value = padding_value
+ self.sampling_rate = sampling_rate
+ self.return_attention_mask = return_attention_mask
+ self.do_normalize = do_normalize
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "padding_value": self.padding_value,
+ "sampling_rate": self.sampling_rate,
+ "return_attention_mask": self.return_attention_mask,
+ "do_normalize": self.do_normalize,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = floats_list((self.batch_size, self.max_seq_length))
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ _flatten(floats_list((x, self.feature_size)))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+
+ return speech_inputs
+
+
+@require_torch
+@require_torchaudio
+class ASTFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+
+ feature_extraction_class = ASTFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = ASTFeatureExtractionTester(self)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # Test not batched input
+ encoded_sequences_1 = feat_extract(speech_inputs[0], return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs[0], return_tensors="np").input_values
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feat_extract(speech_inputs, padding=True, return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs, padding=True, return_tensors="np").input_values
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ @require_torch
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_values.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_values.dtype == torch.float32)
+
+ def _load_datasamples(self, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ @require_torch
+ def test_integration(self):
+ # fmt: off
+ EXPECTED_INPUT_VALUES = torch.tensor(
+ [-0.9894, -1.2776, -0.9066, -1.2776, -0.9349, -1.2609, -1.0386, -1.2776,
+ -1.1561, -1.2776, -1.2052, -1.2723, -1.2190, -1.2132, -1.2776, -1.1133,
+ -1.1953, -1.1343, -1.1584, -1.2203, -1.1770, -1.2474, -1.2381, -1.1936,
+ -0.9270, -0.8317, -0.8049, -0.7706, -0.7565, -0.7869]
+ )
+ # fmt: on
+
+ input_speech = self._load_datasamples(1)
+ feaure_extractor = ASTFeatureExtractor()
+ input_values = feaure_extractor(input_speech, return_tensors="pt").input_values
+ self.assertTrue(torch.allclose(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, atol=1e-4))
diff --git a/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000..90d748ebea
--- /dev/null
+++ b/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,247 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Audio Spectrogram Transformer (AST) model. """
+
+import inspect
+import unittest
+
+from huggingface_hub import hf_hub_download
+from transformers import ASTConfig
+from transformers.testing_utils import require_torch, require_torchaudio, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_torchaudio_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import ASTForAudioClassification, ASTModel
+ from transformers.models.audio_spectrogram_transformer.modeling_audio_spectrogram_transformer import (
+ AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
+ )
+
+
+if is_torchaudio_available():
+ import torchaudio
+
+ from transformers import ASTFeatureExtractor
+
+
+class ASTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ patch_size=2,
+ max_length=24,
+ num_mel_bins=16,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ scope=None,
+ frequency_stride=2,
+ time_stride=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.patch_size = patch_size
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+
+ # in AST, the seq length equals the number of patches + 2 (we add 2 for the [CLS] and distillation tokens)
+ frequency_out_dimension = (self.num_mel_bins - self.patch_size) // self.frequency_stride + 1
+ time_out_dimension = (self.max_length - self.patch_size) // self.time_stride + 1
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.seq_length = num_patches + 2
+
+ def prepare_config_and_inputs(self):
+ input_values = floats_tensor([self.batch_size, self.max_length, self.num_mel_bins])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, input_values, labels
+
+ def get_config(self):
+ return ASTConfig(
+ patch_size=self.patch_size,
+ max_length=self.max_length,
+ num_mel_bins=self.num_mel_bins,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ frequency_stride=self.frequency_stride,
+ time_stride=self.time_stride,
+ )
+
+ def create_and_check_model(self, config, input_values, labels):
+ model = ASTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_values,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_values": input_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ASTModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as AST does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ASTModel,
+ ASTForAudioClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ASTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ASTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="AST does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["input_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in AUDIO_SPECTROGRAM_TRANSFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = ASTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on some audio from AudioSet
+def prepare_audio():
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint", filename="sample_audio.flac", repo_type="dataset"
+ )
+
+ audio, sampling_rate = torchaudio.load(filepath)
+
+ return audio, sampling_rate
+
+
+@require_torch
+@require_torchaudio
+class ASTModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return (
+ ASTFeatureExtractor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
+ if is_torchaudio_available()
+ else None
+ )
+
+ @slow
+ def test_inference_audio_classification(self):
+
+ feature_extractor = self.default_feature_extractor
+ model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ audio, sampling_rate = prepare_audio()
+ audio = audio.squeeze().numpy()
+ inputs = feature_extractor(audio, sampling_rate=sampling_rate, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 527))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
diff --git a/tests/pipelines/test_pipelines_common.py b/tests/pipelines/test_pipelines_common.py
index 492a63a4cc..5593da273b 100644
--- a/tests/pipelines/test_pipelines_common.py
+++ b/tests/pipelines/test_pipelines_common.py
@@ -155,6 +155,12 @@ def get_tiny_feature_extractor_from_checkpoint(checkpoint, tiny_config, feature_
if hasattr(tiny_config, "image_size") and feature_extractor:
feature_extractor = feature_extractor.__class__(size=tiny_config.image_size, crop_size=tiny_config.image_size)
+ # Audio Spectogram Transformer specific.
+ if feature_extractor.__class__.__name__ == "ASTFeatureExtractor":
+ feature_extractor = feature_extractor.__class__(
+ max_length=tiny_config.max_length, num_mel_bins=tiny_config.num_mel_bins
+ )
+
# Speech2TextModel specific.
if hasattr(tiny_config, "input_feat_per_channel") and feature_extractor:
feature_extractor = feature_extractor.__class__(
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index ac1772d853..2caba10588 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -91,6 +91,7 @@ if is_torch_available():
from test_module.custom_modeling import CustomModel, NoSuperInitModel
from transformers import (
BERT_PRETRAINED_MODEL_ARCHIVE_LIST,
+ MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_XVECTOR_MAPPING,
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
@@ -223,6 +224,7 @@ class ModelTesterMixin:
*get_values(MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING),
*get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
+ *get_values(MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
diff --git a/utils/documentation_tests.txt b/utils/documentation_tests.txt
index 7616841929..f245fad7f8 100644
--- a/utils/documentation_tests.txt
+++ b/utils/documentation_tests.txt
@@ -18,6 +18,7 @@ src/transformers/generation/utils.py
src/transformers/models/albert/configuration_albert.py
src/transformers/models/albert/modeling_albert.py
src/transformers/models/albert/modeling_tf_albert.py
+src/transformers/models/audio_spectogram_transformer/modeling_audio_spectogram_transformer.py
src/transformers/models/bart/configuration_bart.py
src/transformers/models/bart/modeling_bart.py
src/transformers/models/beit/configuration_beit.py