diff --git a/README.md b/README.md
index dd46c1dee6..a5d220c2ea 100644
--- a/README.md
+++ b/README.md
@@ -475,6 +475,7 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
diff --git a/README_es.md b/README_es.md
index 3cc52152e5..625a3f3ed0 100644
--- a/README_es.md
+++ b/README_es.md
@@ -450,6 +450,7 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
diff --git a/README_hd.md b/README_hd.md
index 20a62f5c05..87c45015db 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -424,6 +424,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI से) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. द्वाराअनुसंधान पत्र [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) के साथ जारी किया गया
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https ://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP से) साथ में पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स] (https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योआव आर्टज़ी द्वारा पोस्ट किया गया।
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI से) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. द्वाराअनुसंधान पत्र [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) के साथ जारी किया गया
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (फेसबुक से), साथ में पेपर [फेयरसेक S2T: फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग विद फेयरसेक](https: //arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया。
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (फेसबुक से) साथ में पेपर [लार्ज-स्केल सेल्फ- एंड सेमी-सुपरवाइज्ड लर्निंग फॉर स्पीच ट्रांसलेशन](https://arxiv.org/abs/2104.06678) चांगहान वांग, ऐनी वू, जुआन पिनो, एलेक्सी बेवस्की, माइकल औली, एलेक्सिस द्वारा Conneau द्वारा पोस्ट किया गया।
diff --git a/README_ja.md b/README_ja.md
index b70719a2cd..5a17f90525 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -484,6 +484,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI から) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. から公開された研究論文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (Microsoft Research から) Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei. から公開された研究論文 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205)
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
diff --git a/README_ko.md b/README_ko.md
index 48ced9d012..b92a06b772 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -399,6 +399,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI 에서 제공)은 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.의 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)논문과 함께 발표했습니다.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (Google AI 에서 제공)은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.의 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343)논문과 함께 발표했습니다.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (Microsoft Research 에서 제공)은 Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.의 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205)논문과 함께 발표했습니다.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook 에서) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino 의 [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) 논문과 함께 발표했습니다.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook 에서) Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 의 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 논문과 함께 발표했습니다.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index f537c779cd..43e2381a4a 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -423,6 +423,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (来自 Meta AI) 伴随论文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) 由 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick 发布。
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (来自 Google AI) 伴随论文 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) 由 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer 发布。
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (来自 Microsoft Research) 伴随论文 [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) 由 Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei 发布。
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (来自 Facebook), 伴随论文 [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) 由 Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino 发布。
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (来自 Facebook) 伴随论文 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 由 Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 2f35e28089..84005dec7d 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -435,6 +435,7 @@ conda install conda-forge::transformers
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SigLIP](https://huggingface.co/docs/transformers/main/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook) released with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 739353d4d3..86cffb9a7e 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -733,6 +733,8 @@
title: Pix2Struct
- local: model_doc/sam
title: Segment Anything
+ - local: model_doc/siglip
+ title: SigLIP
- local: model_doc/speech-encoder-decoder
title: Speech Encoder Decoder Models
- local: model_doc/tapas
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index bf87c991a9..52b5df6e59 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -250,6 +250,7 @@ Flax), PyTorch, and/or TensorFlow.
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/siglip.md b/docs/source/en/model_doc/siglip.md
new file mode 100644
index 0000000000..5cebbf9784
--- /dev/null
+++ b/docs/source/en/model_doc/siglip.md
@@ -0,0 +1,141 @@
+
+
+# SigLIP
+
+## Overview
+
+The SigLIP model was proposed in [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in [CLIP](clip) by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
+
+The abstract from the paper is the following:
+
+*We propose a simple pairwise Sigmoid loss for Language-Image Pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. Combined with Locked-image Tuning, with only four TPUv4 chips, we train a SigLiT model that achieves 84.5% ImageNet zero-shot accuracy in two days. The disentanglement of the batch size from the loss further allows us to study the impact of examples vs pairs and negative to positive ratio. Finally, we push the batch size to the extreme, up to one million, and find that the benefits of growing batch size quickly diminish, with a more reasonable batch size of 32k being sufficient.*
+
+## Usage tips
+
+- Usage of SigLIP is similar to [CLIP](clip). The main difference is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
+- Training is not yet supported. If you want to fine-tune SigLIP or train from scratch, refer to the loss function from [OpenCLIP](https://github.com/mlfoundations/open_clip/blob/73ad04ae7fb93ede1c02dc9040a828634cb1edf1/src/open_clip/loss.py#L307), which leverages various `torch.distributed` utilities.
+- When using the standalone [`SiglipTokenizer`], make sure to pass `padding="max_length"` as that's how the model was trained. The multimodal [`SiglipProcessor`] takes care of this behind the scenes.
+
+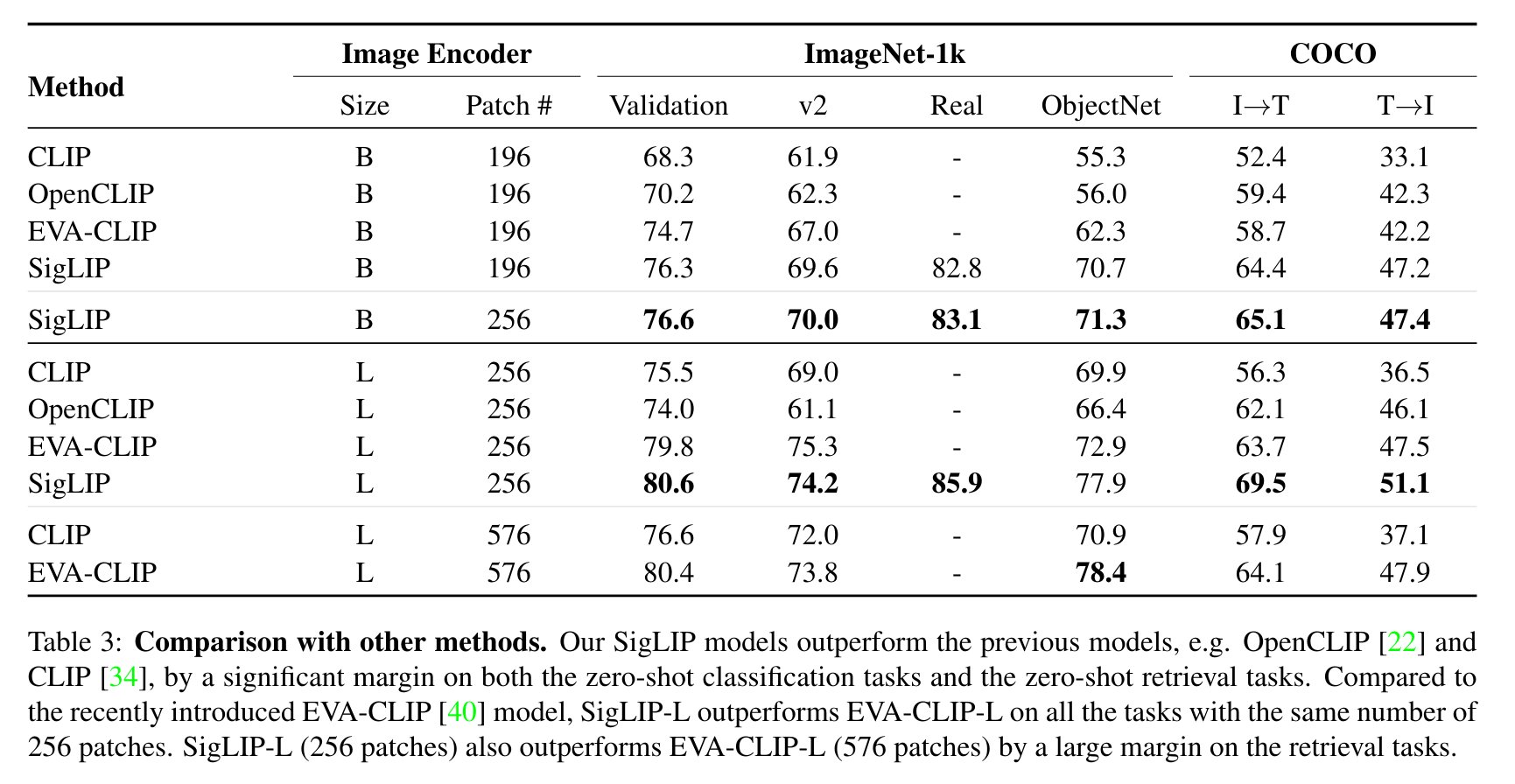 +
+ SigLIP evaluation results compared to CLIP. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
+
+## Usage example
+
+There are 2 main ways to use SigLIP: either using the pipeline API, which abstracts away all the complexity for you, or by using the `SiglipModel` class yourself.
+
+### Pipeline API
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### Using the model yourself
+
+If you want to do the pre- and postprocessing yourself, here's how to do that:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+31.9% that image 0 is 'a photo of 2 cats'
+```
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+ - from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+ - preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+ - forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index b3512b32ec..d721cc2bd2 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -762,6 +762,14 @@ _import_structure = {
"models.segformer": ["SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "SegformerConfig"],
"models.sew": ["SEW_PRETRAINED_CONFIG_ARCHIVE_MAP", "SEWConfig"],
"models.sew_d": ["SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP", "SEWDConfig"],
+ "models.siglip": [
+ "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "SiglipConfig",
+ "SiglipProcessor",
+ "SiglipTextConfig",
+ "SiglipTokenizer",
+ "SiglipVisionConfig",
+ ],
"models.speech_encoder_decoder": ["SpeechEncoderDecoderConfig"],
"models.speech_to_text": [
"SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1290,6 +1298,7 @@ else:
_import_structure["models.pvt"].extend(["PvtImageProcessor"])
_import_structure["models.sam"].extend(["SamImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.siglip"].append("SiglipImageProcessor")
_import_structure["models.swin2sr"].append("Swin2SRImageProcessor")
_import_structure["models.tvlt"].append("TvltImageProcessor")
_import_structure["models.tvp"].append("TvpImageProcessor")
@@ -3155,6 +3164,15 @@ else:
"SEWDPreTrainedModel",
]
)
+ _import_structure["models.siglip"].extend(
+ [
+ "SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "SiglipModel",
+ "SiglipPreTrainedModel",
+ "SiglipTextModel",
+ "SiglipVisionModel",
+ ]
+ )
_import_structure["models.speech_encoder_decoder"].extend(["SpeechEncoderDecoderModel"])
_import_structure["models.speech_to_text"].extend(
[
@@ -5441,6 +5459,14 @@ if TYPE_CHECKING:
)
from .models.sew import SEW_PRETRAINED_CONFIG_ARCHIVE_MAP, SEWConfig
from .models.sew_d import SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP, SEWDConfig
+ from .models.siglip import (
+ SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ SiglipConfig,
+ SiglipProcessor,
+ SiglipTextConfig,
+ SiglipTokenizer,
+ SiglipVisionConfig,
+ )
from .models.speech_encoder_decoder import SpeechEncoderDecoderConfig
from .models.speech_to_text import (
SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5966,6 +5992,7 @@ if TYPE_CHECKING:
from .models.pvt import PvtImageProcessor
from .models.sam import SamImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.siglip import SiglipImageProcessor
from .models.swin2sr import Swin2SRImageProcessor
from .models.tvlt import TvltImageProcessor
from .models.tvp import TvpImageProcessor
@@ -7508,6 +7535,13 @@ if TYPE_CHECKING:
SEWDModel,
SEWDPreTrainedModel,
)
+ from .models.siglip import (
+ SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ SiglipModel,
+ SiglipPreTrainedModel,
+ SiglipTextModel,
+ SiglipVisionModel,
+ )
from .models.speech_encoder_decoder import SpeechEncoderDecoderModel
from .models.speech_to_text import (
SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 428eed3713..2c20873c2e 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -193,6 +193,7 @@ from . import (
segformer,
sew,
sew_d,
+ siglip,
speech_encoder_decoder,
speech_to_text,
speech_to_text_2,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index f1296b9548..9eb3f1985c 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -200,6 +200,8 @@ CONFIG_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerConfig"),
("sew", "SEWConfig"),
("sew-d", "SEWDConfig"),
+ ("siglip", "SiglipConfig"),
+ ("siglip_vision_model", "SiglipVisionConfig"),
("speech-encoder-decoder", "SpeechEncoderDecoderConfig"),
("speech_to_text", "Speech2TextConfig"),
("speech_to_text_2", "Speech2Text2Config"),
@@ -419,6 +421,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
("segformer", "SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("sew", "SEW_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("sew-d", "SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("siglip", "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speech_to_text", "SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speech_to_text_2", "SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speecht5", "SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -664,6 +667,8 @@ MODEL_NAMES_MAPPING = OrderedDict(
("segformer", "SegFormer"),
("sew", "SEW"),
("sew-d", "SEW-D"),
+ ("siglip", "SigLIP"),
+ ("siglip_vision_model", "SiglipVisionModel"),
("speech-encoder-decoder", "Speech Encoder decoder"),
("speech_to_text", "Speech2Text"),
("speech_to_text_2", "Speech2Text2"),
@@ -755,6 +760,7 @@ SPECIAL_MODEL_TYPE_TO_MODULE_NAME = OrderedDict(
("maskformer-swin", "maskformer"),
("xclip", "x_clip"),
("clip_vision_model", "clip"),
+ ("siglip_vision_model", "siglip"),
]
)
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index 446c9adf1b..5180d2331a 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -97,6 +97,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("resnet", "ConvNextImageProcessor"),
("sam", "SamImageProcessor"),
("segformer", "SegformerImageProcessor"),
+ ("siglip", "SiglipImageProcessor"),
("swiftformer", "ViTImageProcessor"),
("swin", "ViTImageProcessor"),
("swin2sr", "Swin2SRImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 6657b8b1b6..7bf50a4518 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -193,6 +193,8 @@ MODEL_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerModel"),
("sew", "SEWModel"),
("sew-d", "SEWDModel"),
+ ("siglip", "SiglipModel"),
+ ("siglip_vision_model", "SiglipVisionModel"),
("speech_to_text", "Speech2TextModel"),
("speecht5", "SpeechT5Model"),
("splinter", "SplinterModel"),
@@ -1102,6 +1104,7 @@ MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("chinese_clip", "ChineseCLIPModel"),
("clip", "CLIPModel"),
("clipseg", "CLIPSegModel"),
+ ("siglip", "SiglipModel"),
]
)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index 93dc6ab605..eee8af931e 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -77,6 +77,7 @@ PROCESSOR_MAPPING_NAMES = OrderedDict(
("seamless_m4t", "SeamlessM4TProcessor"),
("sew", "Wav2Vec2Processor"),
("sew-d", "Wav2Vec2Processor"),
+ ("siglip", "SiglipProcessor"),
("speech_to_text", "Speech2TextProcessor"),
("speech_to_text_2", "Speech2Text2Processor"),
("speecht5", "SpeechT5Processor"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 5ff79fd822..2381d8153d 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -372,6 +372,7 @@ else:
"SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
),
),
+ ("siglip", ("SiglipTokenizer", None)),
("speech_to_text", ("Speech2TextTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text_2", ("Speech2Text2Tokenizer", None)),
("speecht5", ("SpeechT5Tokenizer" if is_sentencepiece_available() else None, None)),
diff --git a/src/transformers/models/siglip/__init__.py b/src/transformers/models/siglip/__init__.py
new file mode 100644
index 0000000000..d47b7c5f5d
--- /dev/null
+++ b/src/transformers/models/siglip/__init__.py
@@ -0,0 +1,94 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_torch_available,
+ is_vision_available,
+)
+
+
+_import_structure = {
+ "configuration_siglip": [
+ "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "SiglipConfig",
+ "SiglipTextConfig",
+ "SiglipVisionConfig",
+ ],
+ "processing_siglip": ["SiglipProcessor"],
+ "tokenization_siglip": ["SiglipTokenizer"],
+}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_siglip"] = ["SiglipImageProcessor"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_siglip"] = [
+ "SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "SiglipModel",
+ "SiglipPreTrainedModel",
+ "SiglipTextModel",
+ "SiglipVisionModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_siglip import (
+ SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ SiglipConfig,
+ SiglipTextConfig,
+ SiglipVisionConfig,
+ )
+ from .processing_siglip import SiglipProcessor
+ from .tokenization_siglip import SiglipTokenizer
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_siglip import SiglipImageProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_siglip import (
+ SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ SiglipModel,
+ SiglipPreTrainedModel,
+ SiglipTextModel,
+ SiglipVisionModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/siglip/configuration_siglip.py b/src/transformers/models/siglip/configuration_siglip.py
new file mode 100644
index 0000000000..990bad7ace
--- /dev/null
+++ b/src/transformers/models/siglip/configuration_siglip.py
@@ -0,0 +1,302 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Siglip model configuration"""
+
+import os
+from typing import Union
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/config.json",
+}
+
+
+class SiglipTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`SiglipTextModel`]. It is used to instantiate a
+ Siglip text encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the text encoder of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the Siglip text model. Defines the number of different tokens that can be represented by
+ the `inputs_ids` passed when calling [`SiglipModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ max_position_embeddings (`int`, *optional*, defaults to 64):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ pad_token_id (`int`, *optional*, defaults to 1):
+ The id of the padding token in the vocabulary.
+ bos_token_id (`int`, *optional*, defaults to 49406):
+ The id of the beginning-of-sequence token in the vocabulary.
+ eos_token_id (`int`, *optional*, defaults to 49407):
+ The id of the end-of-sequence token in the vocabulary.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipTextConfig, SiglipTextModel
+
+ >>> # Initializing a SiglipTextConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipTextConfig()
+
+ >>> # Initializing a SiglipTextModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "siglip_text_model"
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ max_position_embeddings=64,
+ hidden_act="gelu_pytorch_tanh",
+ layer_norm_eps=1e-6,
+ attention_dropout=0.0,
+ # This differs from `CLIPTokenizer`'s default and from openai/siglip
+ # See https://github.com/huggingface/transformers/pull/24773#issuecomment-1632287538
+ pad_token_id=1,
+ bos_token_id=49406,
+ eos_token_id=49407,
+ **kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.max_position_embeddings = max_position_embeddings
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.attention_dropout = attention_dropout
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+ cls._set_token_in_kwargs(kwargs)
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the text config dict if we are loading from SiglipConfig
+ if config_dict.get("model_type") == "siglip":
+ config_dict = config_dict["text_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class SiglipVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`SiglipVisionModel`]. It is used to instantiate a
+ Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_channels (`int`, *optional*, defaults to 3):
+ Number of channels in the input images.
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size (resolution) of each patch.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipVisionConfig, SiglipVisionModel
+
+ >>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipVisionConfig()
+
+ >>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "siglip_vision_model"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ num_channels=3,
+ image_size=224,
+ patch_size=16,
+ hidden_act="gelu_pytorch_tanh",
+ layer_norm_eps=1e-6,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.image_size = image_size
+ self.attention_dropout = attention_dropout
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+ cls._set_token_in_kwargs(kwargs)
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the vision config dict if we are loading from SiglipConfig
+ if config_dict.get("model_type") == "siglip":
+ config_dict = config_dict["vision_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class SiglipConfig(PretrainedConfig):
+ r"""
+ [`SiglipConfig`] is the configuration class to store the configuration of a [`SiglipModel`]. It is used to
+ instantiate a Siglip model according to the specified arguments, defining the text model and vision model configs.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`SiglipTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`SiglipVisionConfig`].
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipConfig, SiglipModel
+
+ >>> # Initializing a SiglipConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipConfig()
+
+ >>> # Initializing a SiglipModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a SiglipConfig from a SiglipTextConfig and a SiglipVisionConfig
+ >>> from transformers import SiglipTextConfig, SiglipVisionConfig
+
+ >>> # Initializing a SiglipText and SiglipVision configuration
+ >>> config_text = SiglipTextConfig()
+ >>> config_vision = SiglipVisionConfig()
+
+ >>> config = SiglipConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "siglip"
+
+ def __init__(self, text_config=None, vision_config=None, **kwargs):
+ super().__init__(**kwargs)
+
+ if text_config is None:
+ text_config = {}
+ logger.info("`text_config` is `None`. Initializing the `SiglipTextConfig` with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("`vision_config` is `None`. initializing the `SiglipVisionConfig` with default values.")
+
+ self.text_config = SiglipTextConfig(**text_config)
+ self.vision_config = SiglipVisionConfig(**vision_config)
+
+ self.initializer_factor = 1.0
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: SiglipTextConfig, vision_config: SiglipVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`SiglipConfig`] (or a derived class) from siglip text model configuration and siglip vision
+ model configuration.
+
+ Returns:
+ [`SiglipConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
diff --git a/src/transformers/models/siglip/convert_siglip_to_hf.py b/src/transformers/models/siglip/convert_siglip_to_hf.py
new file mode 100644
index 0000000000..6adacef84f
--- /dev/null
+++ b/src/transformers/models/siglip/convert_siglip_to_hf.py
@@ -0,0 +1,413 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert SigLIP checkpoints from the original repository.
+
+URL: https://github.com/google-research/big_vision/tree/main
+"""
+
+
+import argparse
+import collections
+from pathlib import Path
+
+import numpy as np
+import requests
+import torch
+from huggingface_hub import hf_hub_download
+from numpy import load
+from PIL import Image
+
+from transformers import SiglipConfig, SiglipImageProcessor, SiglipModel, SiglipProcessor, SiglipTokenizer
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+model_name_to_checkpoint = {
+ # base checkpoints
+ "siglip-base-patch16-224": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_224_63724782.npz",
+ "siglip-base-patch16-256": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_256_60500360.npz",
+ "siglip-base-patch16-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_384_68578854.npz",
+ "siglip-base-patch16-512": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_512_68580893.npz",
+ # large checkpoints
+ "siglip-large-patch16-256": "/Users/nielsrogge/Documents/SigLIP/webli_en_l16_256_60552751.npz",
+ "siglip-large-patch16-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_l16_384_63634585.npz",
+ # multilingual checkpoint
+ "siglip-base-patch16-256-i18n": "/Users/nielsrogge/Documents/SigLIP/webli_i18n_b16_256_66117334.npz",
+ # so400m checkpoints
+ "siglip-so400m-patch14-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_so400m_384_58765454.npz",
+}
+
+model_name_to_image_size = {
+ "siglip-base-patch16-224": 224,
+ "siglip-base-patch16-256": 256,
+ "siglip-base-patch16-384": 384,
+ "siglip-base-patch16-512": 512,
+ "siglip-large-patch16-256": 256,
+ "siglip-large-patch16-384": 384,
+ "siglip-base-patch16-256-i18n": 256,
+ "siglip-so400m-patch14-384": 384,
+}
+
+
+def get_siglip_config(model_name):
+ config = SiglipConfig()
+
+ vocab_size = 250000 if "i18n" in model_name else 32000
+ image_size = model_name_to_image_size[model_name]
+ patch_size = 16 if "patch16" in model_name else 14
+
+ # size of the architecture
+ config.vision_config.image_size = image_size
+ config.vision_config.patch_size = patch_size
+ config.text_config.vocab_size = vocab_size
+
+ if "base" in model_name:
+ pass
+ elif "large" in model_name:
+ config.text_config.hidden_size = 1024
+ config.text_config.intermediate_size = 4096
+ config.text_config.num_hidden_layers = 24
+ config.text_config.num_attention_heads = 16
+ config.vision_config.hidden_size = 1024
+ config.vision_config.intermediate_size = 4096
+ config.vision_config.num_hidden_layers = 24
+ config.vision_config.num_attention_heads = 16
+ elif "so400m" in model_name:
+ config.text_config.hidden_size = 1152
+ config.text_config.intermediate_size = 4304
+ config.text_config.num_hidden_layers = 27
+ config.text_config.num_attention_heads = 16
+ config.vision_config.hidden_size = 1152
+ config.vision_config.intermediate_size = 4304
+ config.vision_config.num_hidden_layers = 27
+ config.vision_config.num_attention_heads = 16
+ else:
+ raise ValueError("Model not supported")
+
+ return config
+
+
+def create_rename_keys(config):
+ rename_keys = []
+ # fmt: off
+
+ # vision encoder
+
+ rename_keys.append(("params/img/embedding/kernel", "vision_model.embeddings.patch_embedding.weight"))
+ rename_keys.append(("params/img/embedding/bias", "vision_model.embeddings.patch_embedding.bias"))
+ rename_keys.append(("params/img/pos_embedding", "vision_model.embeddings.position_embedding.weight"))
+
+ for i in range(config.vision_config.num_hidden_layers):
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_0/scale", f"vision_model.encoder.layers.{i}.layer_norm1.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_0/bias", f"vision_model.encoder.layers.{i}.layer_norm1.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_1/scale", f"vision_model.encoder.layers.{i}.layer_norm2.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_1/bias", f"vision_model.encoder.layers.{i}.layer_norm2.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_0/kernel", f"vision_model.encoder.layers.{i}.mlp.fc1.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_0/bias", f"vision_model.encoder.layers.{i}.mlp.fc1.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_1/kernel", f"vision_model.encoder.layers.{i}.mlp.fc2.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_1/bias", f"vision_model.encoder.layers.{i}.mlp.fc2.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/key/kernel", f"vision_model.encoder.layers.{i}.self_attn.k_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/key/bias", f"vision_model.encoder.layers.{i}.self_attn.k_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/value/kernel", f"vision_model.encoder.layers.{i}.self_attn.v_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/value/bias", f"vision_model.encoder.layers.{i}.self_attn.v_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/query/kernel", f"vision_model.encoder.layers.{i}.self_attn.q_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/query/bias", f"vision_model.encoder.layers.{i}.self_attn.q_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/out/kernel", f"vision_model.encoder.layers.{i}.self_attn.out_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/out/bias", f"vision_model.encoder.layers.{i}.self_attn.out_proj.bias"))
+
+ rename_keys.append(("params/img/Transformer/encoder_norm/scale", "vision_model.post_layernorm.weight"))
+ rename_keys.append(("params/img/Transformer/encoder_norm/bias", "vision_model.post_layernorm.bias"))
+
+ rename_keys.append(("params/img/MAPHead_0/probe", "vision_model.head.probe"))
+ rename_keys.append(("params/img/MAPHead_0/LayerNorm_0/scale", "vision_model.head.layernorm.weight"))
+ rename_keys.append(("params/img/MAPHead_0/LayerNorm_0/bias", "vision_model.head.layernorm.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_0/kernel", "vision_model.head.mlp.fc1.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_0/bias", "vision_model.head.mlp.fc1.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_1/kernel", "vision_model.head.mlp.fc2.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_1/bias", "vision_model.head.mlp.fc2.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MultiHeadDotProductAttention_0/out/kernel", "vision_model.head.attention.out_proj.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MultiHeadDotProductAttention_0/out/bias", "vision_model.head.attention.out_proj.bias"))
+
+ # text encoder
+
+ rename_keys.append(("params/txt/Embed_0/embedding", "text_model.embeddings.token_embedding.weight"))
+ rename_keys.append(("params/txt/pos_embedding", "text_model.embeddings.position_embedding.weight"))
+
+ for i in range(config.text_config.num_hidden_layers):
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_0/scale", f"text_model.encoder.layers.{i}.layer_norm1.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_0/bias", f"text_model.encoder.layers.{i}.layer_norm1.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_1/scale", f"text_model.encoder.layers.{i}.layer_norm2.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_1/bias", f"text_model.encoder.layers.{i}.layer_norm2.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_0/kernel", f"text_model.encoder.layers.{i}.mlp.fc1.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_0/bias", f"text_model.encoder.layers.{i}.mlp.fc1.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_1/kernel", f"text_model.encoder.layers.{i}.mlp.fc2.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_1/bias", f"text_model.encoder.layers.{i}.mlp.fc2.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/key/kernel", f"text_model.encoder.layers.{i}.self_attn.k_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/key/bias", f"text_model.encoder.layers.{i}.self_attn.k_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/value/kernel", f"text_model.encoder.layers.{i}.self_attn.v_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/value/bias", f"text_model.encoder.layers.{i}.self_attn.v_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/query/kernel", f"text_model.encoder.layers.{i}.self_attn.q_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/query/bias", f"text_model.encoder.layers.{i}.self_attn.q_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/out/kernel", f"text_model.encoder.layers.{i}.self_attn.out_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/out/bias", f"text_model.encoder.layers.{i}.self_attn.out_proj.bias"))
+
+ rename_keys.append(("params/txt/Encoder_0/encoder_norm/scale", "text_model.final_layer_norm.weight"))
+ rename_keys.append(("params/txt/Encoder_0/encoder_norm/bias", "text_model.final_layer_norm.bias"))
+ rename_keys.append(("params/txt/head/kernel", "text_model.head.weight"))
+ rename_keys.append(("params/txt/head/bias", "text_model.head.bias"))
+
+ # learned temperature and bias
+ rename_keys.append(("params/t", "logit_scale"))
+ rename_keys.append(("params/b", "logit_bias"))
+
+ # fmt: on
+ return rename_keys
+
+
+def rename_key(dct, old, new, config):
+ val = dct.pop(old)
+
+ if ("out_proj" in new or "v_proj" in new or "k_proj" in new or "q_proj" in new) and "vision" in new:
+ val = val.reshape(-1, config.vision_config.hidden_size)
+ if ("out_proj" in new or "v_proj" in new or "k_proj" in new or "q_proj" in new) and "text" in new:
+ val = val.reshape(-1, config.text_config.hidden_size)
+
+ if "patch_embedding.weight" in new:
+ val = val.transpose(3, 2, 0, 1)
+ elif new.endswith("weight") and "position_embedding" not in new and "token_embedding" not in new:
+ val = val.T
+
+ if "position_embedding" in new and "vision" in new:
+ val = val.reshape(-1, config.vision_config.hidden_size)
+ if "position_embedding" in new and "text" in new:
+ val = val.reshape(-1, config.text_config.hidden_size)
+
+ if new.endswith("bias"):
+ val = val.reshape(-1)
+
+ dct[new] = torch.from_numpy(val)
+
+
+def read_in_q_k_v_head(state_dict, config):
+ # read in individual input projection layers
+ key_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/key/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ key_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/key/bias").reshape(-1)
+ value_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/value/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ value_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/value/bias").reshape(-1)
+ query_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/query/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ query_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/query/bias").reshape(-1)
+
+ # next, add them to the state dict as a single matrix + vector
+ state_dict["vision_model.head.attention.in_proj_weight"] = torch.from_numpy(
+ np.concatenate([query_proj_weight, key_proj_weight, value_proj_weight], axis=0)
+ )
+ state_dict["vision_model.head.attention.in_proj_bias"] = torch.from_numpy(
+ np.concatenate([query_proj_bias, key_proj_bias, value_proj_bias], axis=0)
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+def flatten_nested_dict(params, parent_key="", sep="/"):
+ items = []
+
+ for k, v in params.items():
+ new_key = parent_key + sep + k if parent_key else k
+
+ if isinstance(v, collections.abc.MutableMapping):
+ items.extend(flatten_nested_dict(v, new_key, sep=sep).items())
+ else:
+ items.append((new_key, v))
+ return dict(items)
+
+
+@torch.no_grad()
+def convert_siglip_checkpoint(model_name, pytorch_dump_folder_path, verify_logits=True, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our SigLIP structure.
+ """
+
+ # define default SigLIP configuration
+ config = get_siglip_config(model_name)
+
+ # get checkpoint
+ checkpoint = model_name_to_checkpoint[model_name]
+
+ # get vocab file
+ if "i18n" in model_name:
+ vocab_file = "/Users/nielsrogge/Documents/SigLIP/multilingual_vocab/sentencepiece.model"
+ else:
+ vocab_file = "/Users/nielsrogge/Documents/SigLIP/english_vocab/sentencepiece.model"
+
+ # load original state dict
+ data = load(checkpoint)
+ state_dict = flatten_nested_dict(data)
+
+ # remove and rename some keys
+ rename_keys = create_rename_keys(config)
+ for src, dest in rename_keys:
+ rename_key(state_dict, src, dest, config)
+
+ # qkv matrices of attention pooling head need special treatment
+ read_in_q_k_v_head(state_dict, config)
+
+ # load HuggingFace model
+ model = SiglipModel(config).eval()
+ model.load_state_dict(state_dict)
+
+ # create processor
+ # important: make tokenizer not return attention_mask since original one doesn't require it
+ image_size = config.vision_config.image_size
+ size = {"height": image_size, "width": image_size}
+ image_processor = SiglipImageProcessor(size=size)
+ tokenizer = SiglipTokenizer(vocab_file=vocab_file, model_input_names=["input_ids"])
+ processor = SiglipProcessor(image_processor=image_processor, tokenizer=tokenizer)
+
+ # verify on dummy images and texts
+ url_1 = "https://cdn.openai.com/multimodal-neurons/assets/apple/apple-ipod.jpg"
+ image_1 = Image.open(requests.get(url_1, stream=True).raw).convert("RGB")
+ url_2 = "https://cdn.openai.com/multimodal-neurons/assets/apple/apple-blank.jpg"
+ image_2 = Image.open(requests.get(url_2, stream=True).raw).convert("RGB")
+ texts = ["an apple", "a picture of an apple"]
+
+ inputs = processor(images=[image_1, image_2], text=texts, return_tensors="pt", padding="max_length")
+
+ # verify input_ids against original ones
+ if image_size == 224:
+ filename = "siglip_pixel_values.pt"
+ elif image_size == 256:
+ filename = "siglip_pixel_values_256.pt"
+ elif image_size == 384:
+ filename = "siglip_pixel_values_384.pt"
+ elif image_size == 512:
+ filename = "siglip_pixel_values_512.pt"
+ else:
+ raise ValueError("Image size not supported")
+
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename=filename, repo_type="dataset")
+ original_pixel_values = torch.load(filepath)
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="siglip_input_ids.pt", repo_type="dataset")
+ original_input_ids = torch.load(filepath)
+
+ if "i18n" not in model_name:
+ assert inputs.input_ids.tolist() == original_input_ids.tolist()
+
+ print("Mean of original pixel values:", original_pixel_values.mean())
+ print("Mean of new pixel values:", inputs.pixel_values.mean())
+
+ # note: we're testing with original pixel values here since we don't have exact pixel values
+ with torch.no_grad():
+ outputs = model(input_ids=inputs.input_ids, pixel_values=original_pixel_values)
+
+ # with torch.no_grad():
+ # outputs = model(input_ids=inputs.input_ids, pixel_values=inputs.pixel_values)
+
+ print(outputs.logits_per_image[:3, :3])
+
+ probs = torch.sigmoid(outputs.logits_per_image) # these are the probabilities
+ print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+ print(f"{probs[0][1]:.1%} that image 0 is '{texts[1]}'")
+
+ if verify_logits:
+ if model_name == "siglip-base-patch16-224":
+ expected_slice = torch.tensor(
+ [[-2.9621, -2.1672], [-0.2713, 0.2910]],
+ )
+ elif model_name == "siglip-base-patch16-256":
+ expected_slice = torch.tensor(
+ [[-3.1146, -1.9894], [-0.7312, 0.6387]],
+ )
+ elif model_name == "siglip-base-patch16-384":
+ expected_slice = torch.tensor(
+ [[-2.8098, -2.1891], [-0.4242, 0.4102]],
+ )
+ elif model_name == "siglip-base-patch16-512":
+ expected_slice = torch.tensor(
+ [[-2.7899, -2.2668], [-0.4295, -0.0735]],
+ )
+ elif model_name == "siglip-large-patch16-256":
+ expected_slice = torch.tensor(
+ [[-1.5827, -0.5801], [-0.9153, 0.1363]],
+ )
+ elif model_name == "siglip-large-patch16-384":
+ expected_slice = torch.tensor(
+ [[-2.1523, -0.2899], [-0.2959, 0.7884]],
+ )
+ elif model_name == "siglip-so400m-patch14-384":
+ expected_slice = torch.tensor([[-1.2441, -0.6649], [-0.7060, 0.7374]])
+ elif model_name == "siglip-base-patch16-256-i18n":
+ expected_slice = torch.tensor(
+ [[-0.9064, 0.1073], [-0.0299, 0.5304]],
+ )
+
+ assert torch.allclose(outputs.logits_per_image[:3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving processor to {pytorch_dump_folder_path}")
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"nielsr/{model_name}")
+ processor.push_to_hub(f"nielsr/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="siglip-base-patch16-224",
+ type=str,
+ choices=model_name_to_checkpoint.keys(),
+ help="Name of the model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--verify_logits",
+ action="store_false",
+ help="Whether to verify logits against the original implementation.",
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_siglip_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.verify_logits, args.push_to_hub)
diff --git a/src/transformers/models/siglip/image_processing_siglip.py b/src/transformers/models/siglip/image_processing_siglip.py
new file mode 100644
index 0000000000..285b6e9e55
--- /dev/null
+++ b/src/transformers/models/siglip/image_processing_siglip.py
@@ -0,0 +1,225 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for SigLIP."""
+
+from typing import Dict, List, Optional, Union
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import (
+ resize,
+ to_channel_dimension_format,
+)
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+)
+from ...utils import TensorType, is_vision_available, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_vision_available():
+ import PIL
+
+
+class SiglipImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a SigLIP image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `size`. Can be overridden by
+ `do_resize` in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"height": 224, "width": 224}`):
+ Size of the image after resizing. Can be overridden by `size` in the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
+ Resampling filter to use if resizing the image. Can be overridden by `resample` in the `preprocess` method.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by `do_rescale` in
+ the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by `rescale_factor` in the `preprocess`
+ method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image by the specified mean and standard deviation. Can be overridden by
+ `do_normalize` in the `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `[0.5, 0.5, 0.5]`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `[0.5, 0.5, 0.5]`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ) -> None:
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 224, "width": 224}
+ image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> PIL.Image.Image:
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Size of the image after resizing.
+ resample (`int`, *optional*, defaults to `self.resample`):
+ Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`. Only
+ has an effect if `do_resize` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use for normalization. Only has an effect if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use for normalization. Only has an effect if `do_normalize` is set to
+ `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size, param_name="size", default_to_square=False)
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if do_resize and size is None:
+ raise ValueError("Size must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if do_resize:
+ height, width = size["height"], size["width"]
+ images = [
+ resize(image=image, size=(height, width), resample=resample, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_rescale:
+ images = [
+ self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_normalize:
+ images = [
+ self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) for image in images
+ ]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/siglip/modeling_siglip.py b/src/transformers/models/siglip/modeling_siglip.py
new file mode 100644
index 0000000000..b497b57fe2
--- /dev/null
+++ b/src/transformers/models/siglip/modeling_siglip.py
@@ -0,0 +1,1186 @@
+# coding=utf-8
+# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Siglip model."""
+
+
+import math
+import warnings
+from dataclasses import dataclass
+from typing import Any, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn.init import _calculate_fan_in_and_fan_out
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_siglip import SiglipConfig, SiglipTextConfig, SiglipVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
+
+SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "google/siglip-base-patch16-224",
+ # See all SigLIP models at https://huggingface.co/models?filter=siglip
+]
+
+
+def _trunc_normal_(tensor, mean, std, a, b):
+ # Cut & paste from PyTorch official master until it's in a few official releases - RW
+ # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
+ def norm_cdf(x):
+ # Computes standard normal cumulative distribution function
+ return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
+
+ if (mean < a - 2 * std) or (mean > b + 2 * std):
+ warnings.warn(
+ "mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
+ "The distribution of values may be incorrect.",
+ stacklevel=2,
+ )
+
+ # Values are generated by using a truncated uniform distribution and
+ # then using the inverse CDF for the normal distribution.
+ # Get upper and lower cdf values
+ l = norm_cdf((a - mean) / std)
+ u = norm_cdf((b - mean) / std)
+
+ # Uniformly fill tensor with values from [l, u], then translate to
+ # [2l-1, 2u-1].
+ tensor.uniform_(2 * l - 1, 2 * u - 1)
+
+ # Use inverse cdf transform for normal distribution to get truncated
+ # standard normal
+ tensor.erfinv_()
+
+ # Transform to proper mean, std
+ tensor.mul_(std * math.sqrt(2.0))
+ tensor.add_(mean)
+
+ # Clamp to ensure it's in the proper range
+ tensor.clamp_(min=a, max=b)
+
+
+def trunc_normal_tf_(
+ tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
+) -> torch.Tensor:
+ """Fills the input Tensor with values drawn from a truncated
+ normal distribution. The values are effectively drawn from the
+ normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
+ with values outside :math:`[a, b]` redrawn until they are within
+ the bounds. The method used for generating the random values works
+ best when :math:`a \\leq \text{mean} \\leq b`.
+
+ NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
+ bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
+ and the result is subsquently scaled and shifted by the mean and std args.
+
+ Args:
+ tensor: an n-dimensional `torch.Tensor`
+ mean: the mean of the normal distribution
+ std: the standard deviation of the normal distribution
+ a: the minimum cutoff value
+ b: the maximum cutoff value
+ """
+ with torch.no_grad():
+ _trunc_normal_(tensor, 0, 1.0, a, b)
+ tensor.mul_(std).add_(mean)
+
+
+def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
+ fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
+ if mode == "fan_in":
+ denom = fan_in
+ elif mode == "fan_out":
+ denom = fan_out
+ elif mode == "fan_avg":
+ denom = (fan_in + fan_out) / 2
+
+ variance = scale / denom
+
+ if distribution == "truncated_normal":
+ # constant is stddev of standard normal truncated to (-2, 2)
+ trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
+ elif distribution == "normal":
+ with torch.no_grad():
+ tensor.normal_(std=math.sqrt(variance))
+ elif distribution == "uniform":
+ bound = math.sqrt(3 * variance)
+ with torch.no_grad():
+ tensor.uniform_(-bound, bound)
+ else:
+ raise ValueError(f"invalid distribution {distribution}")
+
+
+def lecun_normal_(tensor):
+ variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
+
+
+def default_flax_embed_init(tensor):
+ variance_scaling_(tensor, mode="fan_in", distribution="normal")
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
+class SiglipVisionModelOutput(ModelOutput):
+ """
+ Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
+
+ Args:
+ image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The image embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ image_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPTextModelOutput with CLIP->Siglip
+class SiglipTextModelOutput(ModelOutput):
+ """
+ Base class for text model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The text embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ text_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->Siglip
+class SiglipOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`SiglipTextModel`].
+ image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The image embeddings obtained by applying the projection layer to the pooled output of [`SiglipVisionModel`].
+ text_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`SiglipTextModel`].
+ vision_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`SiglipVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: torch.FloatTensor = None
+ logits_per_text: torch.FloatTensor = None
+ text_embeds: torch.FloatTensor = None
+ image_embeds: torch.FloatTensor = None
+ text_model_output: BaseModelOutputWithPooling = None
+ vision_model_output: BaseModelOutputWithPooling = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+class SiglipVisionEmbeddings(nn.Module):
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=config.num_channels,
+ out_channels=self.embed_dim,
+ kernel_size=self.patch_size,
+ stride=self.patch_size,
+ padding="valid",
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
+
+ def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
+ patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
+ embeddings = patch_embeds.flatten(2).transpose(1, 2)
+
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->Siglip
+class SiglipTextEmbeddings(nn.Module):
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__()
+ embed_dim = config.hidden_size
+
+ self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
+ self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ ) -> torch.Tensor:
+ seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, :seq_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.token_embedding(input_ids)
+
+ position_embeddings = self.position_embedding(position_ids)
+ embeddings = inputs_embeds + position_embeddings
+
+ return embeddings
+
+
+class SiglipAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ # Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ batch_size, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ k_v_seq_len = key_states.shape[-2]
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
+
+ if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
+class SiglipMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->Siglip
+class SiglipEncoderLayer(nn.Module):
+ def __init__(self, config: SiglipConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = SiglipAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+ self.mlp = SiglipMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+
+ # Ignore copy
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`):
+ Input to the layer of shape `(batch, seq_len, embed_dim)`.
+ attention_mask (`torch.FloatTensor`):
+ Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class SiglipPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = SiglipConfig
+ base_model_prefix = "siglip"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, SiglipVisionEmbeddings):
+ width = (
+ self.config.vision_config.hidden_size
+ if isinstance(self.config, SiglipConfig)
+ else self.config.hidden_size
+ )
+ nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
+ elif isinstance(module, nn.Embedding):
+ default_flax_embed_init(module.weight)
+ elif isinstance(module, SiglipAttention):
+ nn.init.xavier_uniform_(module.q_proj.weight)
+ nn.init.xavier_uniform_(module.k_proj.weight)
+ nn.init.xavier_uniform_(module.v_proj.weight)
+ nn.init.xavier_uniform_(module.out_proj.weight)
+ nn.init.zeros_(module.q_proj.bias)
+ nn.init.zeros_(module.k_proj.bias)
+ nn.init.zeros_(module.v_proj.bias)
+ nn.init.zeros_(module.out_proj.bias)
+ elif isinstance(module, SiglipMLP):
+ nn.init.xavier_uniform_(module.fc1.weight)
+ nn.init.xavier_uniform_(module.fc2.weight)
+ nn.init.normal_(module.fc1.bias, std=1e-6)
+ nn.init.normal_(module.fc2.bias, std=1e-6)
+ elif isinstance(module, SiglipMultiheadAttentionPoolingHead):
+ nn.init.xavier_uniform_(module.probe.data)
+ nn.init.xavier_uniform_(module.attention.in_proj_weight.data)
+ nn.init.zeros_(module.attention.in_proj_bias.data)
+ elif isinstance(module, SiglipModel):
+ logit_scale_init = torch.log(torch.tensor(1.0))
+ module.logit_scale.data.fill_(logit_scale_init)
+ module.logit_bias.data.zero_()
+ elif isinstance(module, (nn.Linear, nn.Conv2d)):
+ lecun_normal_(module.weight)
+ if module.bias is not None:
+ nn.init.zeros_(module.bias)
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+SIGLIP_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`SiglipConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+SIGLIP_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+SIGLIP_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+SIGLIP_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->Siglip
+class SiglipEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`SiglipEncoderLayer`].
+
+ Args:
+ config: SiglipConfig
+ """
+
+ def __init__(self, config: SiglipConfig):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ # Ignore copy
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for encoder_layer in self.layers:
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ encoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ output_attentions,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class SiglipTextTransformer(nn.Module):
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+ self.embeddings = SiglipTextEmbeddings(config)
+ self.encoder = SiglipEncoder(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ self.head = nn.Linear(embed_dim, embed_dim)
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is None:
+ raise ValueError("You have to specify input_ids")
+
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+
+ hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
+
+ # note: SigLIP's text model does not use a causal mask, unlike the original CLIP model.
+ # expand attention_mask
+ if attention_mask is not None:
+ # [batch_size, seq_len] -> [batch_size, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.final_layer_norm(last_hidden_state)
+
+ # Assuming "sticky" EOS tokenization, last token is always EOS.
+ pooled_output = last_hidden_state[:, -1, :]
+ pooled_output = self.head(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """The text model from SigLIP without any head or projection on top.""",
+ SIGLIP_START_DOCSTRING,
+)
+class SiglipTextModel(SiglipPreTrainedModel):
+ config_class = SiglipTextConfig
+
+ _no_split_modules = ["SiglipTextEmbeddings", "SiglipEncoderLayer"]
+
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__(config)
+ self.text_model = SiglipTextTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.text_model.embeddings.token_embedding
+
+ def set_input_embeddings(self, value):
+ self.text_model.embeddings.token_embedding = value
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, SiglipTextModel
+
+ >>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> # important: make sure to set padding="max_length" as that's how the model was trained
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled (EOS token) states
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+class SiglipVisionTransformer(nn.Module):
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = SiglipVisionEmbeddings(config)
+ self.encoder = SiglipEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.head = SiglipMultiheadAttentionPoolingHead(config)
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
+ def forward(
+ self,
+ pixel_values,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ hidden_states = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.post_layernorm(last_hidden_state)
+
+ pooled_output = self.head(last_hidden_state)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class SiglipMultiheadAttentionPoolingHead(nn.Module):
+ """Multihead Attention Pooling."""
+
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+
+ self.probe = nn.Parameter(torch.randn(1, 1, config.hidden_size))
+ self.attention = torch.nn.MultiheadAttention(config.hidden_size, config.num_attention_heads, batch_first=True)
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.mlp = SiglipMLP(config)
+
+ def forward(self, hidden_state):
+ batch_size = hidden_state.shape[0]
+ probe = self.probe.repeat(batch_size, 1, 1)
+
+ hidden_state = self.attention(probe, hidden_state, hidden_state)[0]
+
+ residual = hidden_state
+ hidden_state = self.layernorm(hidden_state)
+ hidden_state = residual + self.mlp(hidden_state)
+
+ return hidden_state[:, 0]
+
+
+@add_start_docstrings(
+ """The vision model from SigLIP without any head or projection on top.""",
+ SIGLIP_START_DOCSTRING,
+)
+class SiglipVisionModel(SiglipPreTrainedModel):
+ config_class = SiglipVisionConfig
+ main_input_name = "pixel_values"
+
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__(config)
+
+ self.vision_model = SiglipVisionTransformer(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
+ def forward(
+ self,
+ pixel_values,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, SiglipVisionModel
+
+ >>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled features
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+@add_start_docstrings(SIGLIP_START_DOCSTRING)
+class SiglipModel(SiglipPreTrainedModel):
+ config_class = SiglipConfig
+
+ def __init__(self, config: SiglipConfig):
+ super().__init__(config)
+
+ if not isinstance(config.text_config, SiglipTextConfig):
+ raise ValueError(
+ "config.text_config is expected to be of type SiglipTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ if not isinstance(config.vision_config, SiglipVisionConfig):
+ raise ValueError(
+ "config.vision_config is expected to be of type SiglipVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.text_model = SiglipTextTransformer(text_config)
+ self.vision_model = SiglipVisionTransformer(vision_config)
+
+ self.logit_scale = nn.Parameter(torch.randn(1))
+ self.logit_bias = nn.Parameter(torch.randn(1))
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`SiglipTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> # important: make sure to set padding="max_length" as that's how the model was trained
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
+ >>> with torch.no_grad():
+ ... text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = text_outputs[1]
+
+ return pooled_output
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`SiglipVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use SiglipModel's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = vision_outputs[1]
+
+ return pooled_output
+
+ @add_start_docstrings_to_model_forward(SIGLIP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=SiglipOutput, config_class=SiglipConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SiglipOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+ >>> inputs = processor(text=texts, images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+
+ >>> logits_per_image = outputs.logits_per_image
+ >>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+ >>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+ 31.9% that image 0 is 'a photo of 2 cats'
+ ```"""
+ # Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ text_embeds = text_outputs[1]
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * self.logit_scale.exp() + self.logit_bias
+ logits_per_image = logits_per_text.t()
+
+ loss = None
+ if return_loss:
+ raise NotImplementedError("SigLIP loss to be implemented")
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return SiglipOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
diff --git a/src/transformers/models/siglip/processing_siglip.py b/src/transformers/models/siglip/processing_siglip.py
new file mode 100644
index 0000000000..ecb229d28a
--- /dev/null
+++ b/src/transformers/models/siglip/processing_siglip.py
@@ -0,0 +1,143 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for SigLIP.
+"""
+
+from typing import List, Optional, Union
+
+from ...feature_extraction_utils import BatchFeature
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType
+
+
+class SiglipProcessor(ProcessorMixin):
+ r"""
+ Constructs a Siglip processor which wraps a Siglip image processor and a Siglip tokenizer into a single processor.
+
+ [`SiglipProcessor`] offers all the functionalities of [`SiglipImageProcessor`] and [`SiglipTokenizer`]. See the
+ [`~SiglipProcessor.__call__`] and [`~SiglipProcessor.decode`] for more information.
+
+ Args:
+ image_processor ([`SiglipImageProcessor`]):
+ The image processor is a required input.
+ tokenizer ([`SiglipTokenizer`]):
+ The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "SiglipImageProcessor"
+ tokenizer_class = "SiglipTokenizer"
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ images: ImageInput = None,
+ padding: Union[bool, str, PaddingStrategy] = "max_length",
+ truncation: Union[bool, str, TruncationStrategy] = None,
+ max_length=None,
+ return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to SiglipTokenizer's [`~SiglipTokenizer.__call__`] if `text` is not `None` to encode
+ the text. To prepare the image(s), this method forwards the `images` argument to
+ SiglipImageProcessor's [`~SiglipImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
+ of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+ padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `max_length`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding
+ index) among:
+ - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
+ acceptable input length for the model if that argument is not provided.
+ - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
+ lengths).
+ max_length (`int`, *optional*):
+ Maximum length of the returned list and optionally padding length (see above).
+ truncation (`bool`, *optional*):
+ Activates truncation to cut input sequences longer than `max_length` to `max_length`.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+
+ if text is None and images is None:
+ raise ValueError("You have to specify either text or images. Both cannot be none.")
+
+ if text is not None:
+ encoding = self.tokenizer(
+ text, return_tensors=return_tensors, padding=padding, truncation=truncation, max_length=max_length
+ )
+
+ if images is not None:
+ image_features = self.image_processor(images, return_tensors=return_tensors)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchFeature(data=dict(**image_features), tensor_type=return_tensors)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to SiglipTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to SiglipTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.clip.processing_clip.CLIPProcessor.model_input_names with CLIP->Siglip, T5->Siglip
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
diff --git a/src/transformers/models/siglip/tokenization_siglip.py b/src/transformers/models/siglip/tokenization_siglip.py
new file mode 100644
index 0000000000..7c34ab6d0c
--- /dev/null
+++ b/src/transformers/models/siglip/tokenization_siglip.py
@@ -0,0 +1,389 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Tokenization class for SigLIP model."""
+
+import os
+import re
+import string
+import warnings
+from shutil import copyfile
+from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple
+
+import sentencepiece as spm
+
+from ...convert_slow_tokenizer import import_protobuf
+from ...tokenization_utils import PreTrainedTokenizer
+from ...tokenization_utils_base import AddedToken
+
+
+if TYPE_CHECKING:
+ from ...tokenization_utils_base import TextInput
+from ...utils import logging, requires_backends
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/spiece.model",
+ }
+}
+
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "google/siglip-base-patch16-224": 256,
+}
+
+SPIECE_UNDERLINE = "▁"
+
+
+class SiglipTokenizer(PreTrainedTokenizer):
+ """
+ Construct a Siglip tokenizer. Based on [SentencePiece](https://github.com/google/sentencepiece).
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ [SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
+ contains the vocabulary necessary to instantiate a tokenizer.
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ additional_special_tokens (`List[str]`, *optional*):
+ Additional special tokens used by the tokenizer.
+ sp_model_kwargs (`dict`, *optional*):
+ Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
+ SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
+ to set:
+
+ - `enable_sampling`: Enable subword regularization.
+ - `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
+
+ - `nbest_size = {0,1}`: No sampling is performed.
+ - `nbest_size > 1`: samples from the nbest_size results.
+ - `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
+ using forward-filtering-and-backward-sampling algorithm.
+
+ - `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
+ BPE-dropout.
+ model_max_length (`int`, *optional*, defaults to 64):
+ The maximum length (in number of tokens) for model inputs.
+ do_lower_case (`bool`, *optional*, defaults to `True`):
+ Whether or not to lowercase the input when tokenizing.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+
+ def __init__(
+ self,
+ vocab_file,
+ eos_token="",
+ unk_token="",
+ pad_token="",
+ additional_special_tokens=None,
+ sp_model_kwargs: Optional[Dict[str, Any]] = None,
+ model_max_length=64,
+ do_lower_case=True,
+ **kwargs,
+ ) -> None:
+ requires_backends(self, "protobuf")
+
+ pad_token = (
+ AddedToken(pad_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+ unk_token = (
+ AddedToken(unk_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ eos_token = (
+ AddedToken(eos_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+
+ self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
+
+ self.do_lower_case = do_lower_case
+ self.vocab_file = vocab_file
+
+ self.sp_model = self.get_spm_processor()
+ self.vocab_file = vocab_file
+
+ super().__init__(
+ eos_token=eos_token,
+ unk_token=unk_token,
+ pad_token=pad_token,
+ additional_special_tokens=additional_special_tokens,
+ sp_model_kwargs=self.sp_model_kwargs,
+ model_max_length=model_max_length,
+ do_lower_case=do_lower_case,
+ **kwargs,
+ )
+
+ def get_spm_processor(self):
+ tokenizer = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ with open(self.vocab_file, "rb") as f:
+ sp_model = f.read()
+ model_pb2 = import_protobuf()
+ model = model_pb2.ModelProto.FromString(sp_model)
+ normalizer_spec = model_pb2.NormalizerSpec()
+ normalizer_spec.add_dummy_prefix = False
+ model.normalizer_spec.MergeFrom(normalizer_spec)
+ sp_model = model.SerializeToString()
+ tokenizer.LoadFromSerializedProto(sp_model)
+ return tokenizer
+
+ @property
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.vocab_size
+ def vocab_size(self):
+ return self.sp_model.get_piece_size()
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.get_vocab
+ def get_vocab(self):
+ vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
+ vocab.update(self.added_tokens_encoder)
+ return vocab
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.get_special_tokens_mask
+ def get_special_tokens_mask(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
+ ) -> List[int]:
+ """
+ Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
+ special tokens using the tokenizer `prepare_for_model` method.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ already_has_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the token list is already formatted with special tokens for the model.
+
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
+ """
+ if already_has_special_tokens:
+ return super().get_special_tokens_mask(
+ token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
+ )
+
+ # normal case: some special tokens
+ if token_ids_1 is None:
+ return ([0] * len(token_ids_0)) + [1]
+ return ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._add_eos_if_not_present
+ def _add_eos_if_not_present(self, token_ids: List[int]) -> List[int]:
+ """Do not add eos again if user already added it."""
+ if len(token_ids) > 0 and token_ids[-1] == self.eos_token_id:
+ warnings.warn(
+ f"This sequence already has {self.eos_token}. In future versions this behavior may lead to duplicated"
+ " eos tokens being added."
+ )
+ return token_ids
+ else:
+ return token_ids + [self.eos_token_id]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.create_token_type_ids_from_sequences
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make
+ use of token type ids, therefore a list of zeros is returned.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of zeros.
+ """
+ eos = [self.eos_token_id]
+
+ if token_ids_1 is None:
+ return len(token_ids_0 + eos) * [0]
+ return len(token_ids_0 + eos + token_ids_1 + eos) * [0]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.build_inputs_with_special_tokens
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. A sequence has the following format:
+
+ - single sequence: `X `
+ - pair of sequences: `A B `
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ token_ids_0 = self._add_eos_if_not_present(token_ids_0)
+ if token_ids_1 is None:
+ return token_ids_0
+ else:
+ token_ids_1 = self._add_eos_if_not_present(token_ids_1)
+ return token_ids_0 + token_ids_1
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.__getstate__
+ def __getstate__(self):
+ state = self.__dict__.copy()
+ state["sp_model"] = None
+ return state
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.__setstate__
+ def __setstate__(self, d):
+ self.__dict__ = d
+
+ # for backward compatibility
+ if not hasattr(self, "sp_model_kwargs"):
+ self.sp_model_kwargs = {}
+
+ self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ self.sp_model.Load(self.vocab_file)
+
+ def remove_punctuation(self, text: str) -> str:
+ return text.translate(str.maketrans("", "", string.punctuation))
+
+ # source: https://github.com/google-research/big_vision/blob/3b8e5ab6ad4f96e32b32826f9e1b8fd277914f9c/big_vision/evaluators/proj/image_text/prompt_engineering.py#L94
+ def canonicalize_text(self, text, *, keep_punctuation_exact_string=None):
+ """Returns canonicalized `text` (puncuation removed).
+
+ Args:
+ text (`str`):
+ String to be canonicalized.
+ keep_punctuation_exact_string (`str`, *optional*):
+ If provided, then this exact string is kept. For example providing '{}' will keep any occurrences of '{}'
+ (but will still remove '{' and '}' that appear separately).
+ """
+ if keep_punctuation_exact_string:
+ text = keep_punctuation_exact_string.join(
+ self.remove_punctuation(part) for part in text.split(keep_punctuation_exact_string)
+ )
+ else:
+ text = self.remove_punctuation(text)
+ text = re.sub(r"\s+", " ", text)
+ text = text.strip()
+
+ return text
+
+ def tokenize(self, text: "TextInput", add_special_tokens=False, **kwargs) -> List[str]:
+ """
+ Converts a string to a list of tokens.
+ """
+ tokens = super().tokenize(SPIECE_UNDERLINE + text.replace(SPIECE_UNDERLINE, " "), **kwargs)
+
+ if len(tokens) > 1 and tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
+ tokens = tokens[1:]
+ return tokens
+
+ @property
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.unk_token_length
+ def unk_token_length(self):
+ return len(self.sp_model.encode(str(self.unk_token)))
+
+ def _tokenize(self, text, **kwargs):
+ """
+ Returns a tokenized string.
+
+ We de-activated the `add_dummy_prefix` option, thus the sentencepiece internals will always strip any
+ SPIECE_UNDERLINE.
+
+ For example: `self.sp_model.encode(f"{SPIECE_UNDERLINE}Hey", out_type = str)` will give `['H', 'e', 'y']` instead of `['▁He', 'y']`.
+
+ Thus we always encode `f"{unk_token}text"` and strip the `unk_token`. Here is an example with `unk_token = ""` and `unk_token_length = 4`.
+ `self.tokenizer.sp_model.encode(" Hey", out_type = str)[4:]`.
+ """
+ text = self.canonicalize_text(text, keep_punctuation_exact_string=None)
+ tokens = self.sp_model.encode(text, out_type=str)
+
+ # 1. Encode string + prefix ex: " Hey"
+ tokens = self.sp_model.encode(self.unk_token + text, out_type=str)
+ # 2. Remove self.unk_token from ['<','unk','>', '▁Hey']
+ return tokens[self.unk_token_length :] if len(tokens) >= self.unk_token_length else tokens
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._convert_token_to_id
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.sp_model.piece_to_id(token)
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._convert_id_to_token
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ token = self.sp_model.IdToPiece(index)
+ return token
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.convert_tokens_to_string
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ current_sub_tokens = []
+ # since we manually add the prefix space, we have to remove it
+ tokens[0] = tokens[0].lstrip(SPIECE_UNDERLINE)
+ out_string = ""
+ prev_is_special = False
+ for token in tokens:
+ # make sure that special tokens are not decoded using sentencepiece model
+ if token in self.all_special_tokens:
+ if not prev_is_special:
+ out_string += " "
+ out_string += self.sp_model.decode(current_sub_tokens) + token
+ prev_is_special = True
+ current_sub_tokens = []
+ else:
+ current_sub_tokens.append(token)
+ prev_is_special = False
+ out_string += self.sp_model.decode(current_sub_tokens)
+ return out_string.strip()
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ out_vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+
+ if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
+ copyfile(self.vocab_file, out_vocab_file)
+ elif not os.path.isfile(self.vocab_file):
+ with open(out_vocab_file, "wb") as fi:
+ content_spiece_model = self.sp_model.serialized_model_proto()
+ fi.write(content_spiece_model)
+
+ return (out_vocab_file,)
diff --git a/src/transformers/pipelines/zero_shot_image_classification.py b/src/transformers/pipelines/zero_shot_image_classification.py
index b16d191754..83bd9970e8 100644
--- a/src/transformers/pipelines/zero_shot_image_classification.py
+++ b/src/transformers/pipelines/zero_shot_image_classification.py
@@ -18,6 +18,8 @@ if is_vision_available():
from ..image_utils import load_image
if is_torch_available():
+ import torch
+
from ..models.auto.modeling_auto import MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES
if is_tf_available():
@@ -120,7 +122,8 @@ class ZeroShotImageClassificationPipeline(Pipeline):
inputs = self.image_processor(images=[image], return_tensors=self.framework)
inputs["candidate_labels"] = candidate_labels
sequences = [hypothesis_template.format(x) for x in candidate_labels]
- text_inputs = self.tokenizer(sequences, return_tensors=self.framework, padding=True)
+ padding = "max_length" if self.model.config.model_type == "siglip" else True
+ text_inputs = self.tokenizer(sequences, return_tensors=self.framework, padding=padding)
inputs["text_inputs"] = [text_inputs]
return inputs
@@ -144,7 +147,12 @@ class ZeroShotImageClassificationPipeline(Pipeline):
def postprocess(self, model_outputs):
candidate_labels = model_outputs.pop("candidate_labels")
logits = model_outputs["logits"][0]
- if self.framework == "pt":
+ if self.framework == "pt" and self.model.config.model_type == "siglip":
+ probs = torch.sigmoid(logits).squeeze(-1)
+ scores = probs.tolist()
+ if not isinstance(scores, list):
+ scores = [scores]
+ elif self.framework == "pt":
probs = logits.softmax(dim=-1).squeeze(-1)
scores = probs.tolist()
if not isinstance(scores, list):
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index dbd46b5797..4d89b2942f 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -7514,6 +7514,37 @@ class SEWDPreTrainedModel(metaclass=DummyObject):
requires_backends(self, ["torch"])
+SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class SiglipModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipTextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipVisionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class SpeechEncoderDecoderModel(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index f1a10ff571..89366aba50 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -471,6 +471,13 @@ class SegformerImageProcessor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class SiglipImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class Swin2SRImageProcessor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/siglip/__init__.py b/tests/models/siglip/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/siglip/test_image_processor_siglip.py b/tests/models/siglip/test_image_processor_siglip.py
new file mode 100644
index 0000000000..5f43d6f08a
--- /dev/null
+++ b/tests/models/siglip/test_image_processor_siglip.py
@@ -0,0 +1,125 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import SiglipImageProcessor
+
+
+class SiglipImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest with CLIP->Siglip
+class SiglipImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = SiglipImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.image_processor_tester = SiglipImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ # Ignore copy
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+
+ # Ignore copy
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(
+ self.image_processor_dict, size={"height": 84, "width": 84}
+ )
+ self.assertEqual(image_processor.size, {"height": 84, "width": 84})
+
+ @unittest.skip("not supported")
+ # Ignore copy
+ def test_call_numpy_4_channels(self):
+ pass
diff --git a/tests/models/siglip/test_modeling_siglip.py b/tests/models/siglip/test_modeling_siglip.py
new file mode 100644
index 0000000000..b6889c1573
--- /dev/null
+++ b/tests/models/siglip/test_modeling_siglip.py
@@ -0,0 +1,631 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Siglip model. """
+
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+import requests
+
+from transformers import SiglipConfig, SiglipTextConfig, SiglipVisionConfig
+from transformers.testing_utils import (
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import SiglipModel, SiglipTextModel, SiglipVisionModel
+ from transformers.models.siglip.modeling_siglip import SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import SiglipProcessor
+
+
+class SiglipVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPVisionModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return SiglipVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = SiglipVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPVisionModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as SIGLIP does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (SiglipVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = SiglipVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=SiglipVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="SIGLIP does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class SiglipTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return SiglipTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = SiglipTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (SiglipTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+ model_split_percents = [0.5, 0.8, 0.9]
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.setUp with CLIP->Siglip
+ def setUp(self):
+ self.model_tester = SiglipTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=SiglipTextConfig, hidden_size=37)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_config
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_model
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training
+ def test_training(self):
+ pass
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing_use_reentrant
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing_use_reentrant_false
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Siglip does not use inputs_embeds")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_inputs_embeds
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="SiglipTextModel has no base class and is not available in MODEL_MAPPING")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_save_load_fast_init_from_base
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="SiglipTextModel has no base class and is not available in MODEL_MAPPING")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_save_load_fast_init_to_base
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class SiglipModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = SiglipTextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = SiglipVisionModelTester(parent, **vision_kwargs)
+ self.is_training = is_training
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return SiglipConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(),
+ self.vision_model_tester.get_config(),
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = SiglipModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ "return_loss": False,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (SiglipModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": SiglipModel} if is_torch_available() else {}
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.setUp with CLIP->Siglip
+ def setUp(self):
+ self.model_tester = SiglipModelTester(self)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_hidden_states_output
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_inputs_embeds
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_retain_grad_hidden_states_attentions
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not have input/output embeddings")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model_common_attributes
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest._create_and_check_torchscript with CLIP->Siglip
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ return
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # Siglip needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_load_vision_text_config with CLIP->Siglip
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save SiglipConfig and check if we can load SiglipVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = SiglipVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save SiglipConfig and check if we can load SiglipTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = SiglipTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @slow
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model_from_pretrained with CLIPModel->SiglipModel, CLIP->SIGLIP
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+class SiglipModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "google/siglip-base-patch16-224"
+ model = SiglipModel.from_pretrained(model_name).to(torch_device)
+ processor = SiglipProcessor.from_pretrained(model_name)
+
+ image = prepare_img()
+ inputs = processor(
+ text=["a photo of 2 cats", "a photo of 2 dogs"], images=image, padding="max_length", return_tensors="pt"
+ ).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits_per_image = outputs.logits_per_image
+ logits_per_text = outputs.logits_per_text
+
+ # verify the logits
+ self.assertEqual(
+ logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+
+ expected_logits = torch.tensor([[-0.7567, -10.3354]], device=torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits_per_image, expected_logits, atol=1e-3))
+
+ # verify the probs
+ probs = torch.sigmoid(logits_per_image) # these are the probabilities
+ expected_probs = torch.tensor([[3.1937e-01, 3.2463e-05]], device=torch_device)
+ self.assertTrue(torch.allclose(probs, expected_probs, atol=1e-3))
diff --git a/tests/models/siglip/test_tokenization_siglip.py b/tests/models/siglip/test_tokenization_siglip.py
new file mode 100644
index 0000000000..586d6b0089
--- /dev/null
+++ b/tests/models/siglip/test_tokenization_siglip.py
@@ -0,0 +1,462 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import tempfile
+import unittest
+
+from transformers import SPIECE_UNDERLINE, AddedToken, BatchEncoding, SiglipTokenizer
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, slow
+from transformers.utils import cached_property, is_tf_available, is_torch_available
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+if is_torch_available():
+ FRAMEWORK = "pt"
+elif is_tf_available():
+ FRAMEWORK = "tf"
+else:
+ FRAMEWORK = "jax"
+
+
+@require_sentencepiece
+@require_tokenizers
+class SiglipTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = SiglipTokenizer
+ test_rust_tokenizer = False
+ test_sentencepiece = True
+ test_sentencepiece_ignore_case = True
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.setUp with T5->Siglip
+ def setUp(self):
+ super().setUp()
+
+ # We have a SentencePiece fixture for testing
+ tokenizer = SiglipTokenizer(SAMPLE_VOCAB)
+ tokenizer.save_pretrained(self.tmpdirname)
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_convert_token_and_id with T5->Siglip
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = "
+
+ SigLIP evaluation results compared to CLIP. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
+
+## Usage example
+
+There are 2 main ways to use SigLIP: either using the pipeline API, which abstracts away all the complexity for you, or by using the `SiglipModel` class yourself.
+
+### Pipeline API
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### Using the model yourself
+
+If you want to do the pre- and postprocessing yourself, here's how to do that:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+31.9% that image 0 is 'a photo of 2 cats'
+```
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+ - from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+ - preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+ - forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+ - forward
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index b3512b32ec..d721cc2bd2 100644
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -762,6 +762,14 @@ _import_structure = {
"models.segformer": ["SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP", "SegformerConfig"],
"models.sew": ["SEW_PRETRAINED_CONFIG_ARCHIVE_MAP", "SEWConfig"],
"models.sew_d": ["SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP", "SEWDConfig"],
+ "models.siglip": [
+ "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "SiglipConfig",
+ "SiglipProcessor",
+ "SiglipTextConfig",
+ "SiglipTokenizer",
+ "SiglipVisionConfig",
+ ],
"models.speech_encoder_decoder": ["SpeechEncoderDecoderConfig"],
"models.speech_to_text": [
"SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP",
@@ -1290,6 +1298,7 @@ else:
_import_structure["models.pvt"].extend(["PvtImageProcessor"])
_import_structure["models.sam"].extend(["SamImageProcessor"])
_import_structure["models.segformer"].extend(["SegformerFeatureExtractor", "SegformerImageProcessor"])
+ _import_structure["models.siglip"].append("SiglipImageProcessor")
_import_structure["models.swin2sr"].append("Swin2SRImageProcessor")
_import_structure["models.tvlt"].append("TvltImageProcessor")
_import_structure["models.tvp"].append("TvpImageProcessor")
@@ -3155,6 +3164,15 @@ else:
"SEWDPreTrainedModel",
]
)
+ _import_structure["models.siglip"].extend(
+ [
+ "SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "SiglipModel",
+ "SiglipPreTrainedModel",
+ "SiglipTextModel",
+ "SiglipVisionModel",
+ ]
+ )
_import_structure["models.speech_encoder_decoder"].extend(["SpeechEncoderDecoderModel"])
_import_structure["models.speech_to_text"].extend(
[
@@ -5441,6 +5459,14 @@ if TYPE_CHECKING:
)
from .models.sew import SEW_PRETRAINED_CONFIG_ARCHIVE_MAP, SEWConfig
from .models.sew_d import SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP, SEWDConfig
+ from .models.siglip import (
+ SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ SiglipConfig,
+ SiglipProcessor,
+ SiglipTextConfig,
+ SiglipTokenizer,
+ SiglipVisionConfig,
+ )
from .models.speech_encoder_decoder import SpeechEncoderDecoderConfig
from .models.speech_to_text import (
SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP,
@@ -5966,6 +5992,7 @@ if TYPE_CHECKING:
from .models.pvt import PvtImageProcessor
from .models.sam import SamImageProcessor
from .models.segformer import SegformerFeatureExtractor, SegformerImageProcessor
+ from .models.siglip import SiglipImageProcessor
from .models.swin2sr import Swin2SRImageProcessor
from .models.tvlt import TvltImageProcessor
from .models.tvp import TvpImageProcessor
@@ -7508,6 +7535,13 @@ if TYPE_CHECKING:
SEWDModel,
SEWDPreTrainedModel,
)
+ from .models.siglip import (
+ SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ SiglipModel,
+ SiglipPreTrainedModel,
+ SiglipTextModel,
+ SiglipVisionModel,
+ )
from .models.speech_encoder_decoder import SpeechEncoderDecoderModel
from .models.speech_to_text import (
SPEECH_TO_TEXT_PRETRAINED_MODEL_ARCHIVE_LIST,
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 428eed3713..2c20873c2e 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -193,6 +193,7 @@ from . import (
segformer,
sew,
sew_d,
+ siglip,
speech_encoder_decoder,
speech_to_text,
speech_to_text_2,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index f1296b9548..9eb3f1985c 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -200,6 +200,8 @@ CONFIG_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerConfig"),
("sew", "SEWConfig"),
("sew-d", "SEWDConfig"),
+ ("siglip", "SiglipConfig"),
+ ("siglip_vision_model", "SiglipVisionConfig"),
("speech-encoder-decoder", "SpeechEncoderDecoderConfig"),
("speech_to_text", "Speech2TextConfig"),
("speech_to_text_2", "Speech2Text2Config"),
@@ -419,6 +421,7 @@ CONFIG_ARCHIVE_MAP_MAPPING_NAMES = OrderedDict(
("segformer", "SEGFORMER_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("sew", "SEW_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("sew-d", "SEW_D_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("siglip", "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speech_to_text", "SPEECH_TO_TEXT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speech_to_text_2", "SPEECH_TO_TEXT_2_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("speecht5", "SPEECHT5_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -664,6 +667,8 @@ MODEL_NAMES_MAPPING = OrderedDict(
("segformer", "SegFormer"),
("sew", "SEW"),
("sew-d", "SEW-D"),
+ ("siglip", "SigLIP"),
+ ("siglip_vision_model", "SiglipVisionModel"),
("speech-encoder-decoder", "Speech Encoder decoder"),
("speech_to_text", "Speech2Text"),
("speech_to_text_2", "Speech2Text2"),
@@ -755,6 +760,7 @@ SPECIAL_MODEL_TYPE_TO_MODULE_NAME = OrderedDict(
("maskformer-swin", "maskformer"),
("xclip", "x_clip"),
("clip_vision_model", "clip"),
+ ("siglip_vision_model", "siglip"),
]
)
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index 446c9adf1b..5180d2331a 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -97,6 +97,7 @@ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
("resnet", "ConvNextImageProcessor"),
("sam", "SamImageProcessor"),
("segformer", "SegformerImageProcessor"),
+ ("siglip", "SiglipImageProcessor"),
("swiftformer", "ViTImageProcessor"),
("swin", "ViTImageProcessor"),
("swin2sr", "Swin2SRImageProcessor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index 6657b8b1b6..7bf50a4518 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -193,6 +193,8 @@ MODEL_MAPPING_NAMES = OrderedDict(
("segformer", "SegformerModel"),
("sew", "SEWModel"),
("sew-d", "SEWDModel"),
+ ("siglip", "SiglipModel"),
+ ("siglip_vision_model", "SiglipVisionModel"),
("speech_to_text", "Speech2TextModel"),
("speecht5", "SpeechT5Model"),
("splinter", "SplinterModel"),
@@ -1102,6 +1104,7 @@ MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
("chinese_clip", "ChineseCLIPModel"),
("clip", "CLIPModel"),
("clipseg", "CLIPSegModel"),
+ ("siglip", "SiglipModel"),
]
)
diff --git a/src/transformers/models/auto/processing_auto.py b/src/transformers/models/auto/processing_auto.py
index 93dc6ab605..eee8af931e 100644
--- a/src/transformers/models/auto/processing_auto.py
+++ b/src/transformers/models/auto/processing_auto.py
@@ -77,6 +77,7 @@ PROCESSOR_MAPPING_NAMES = OrderedDict(
("seamless_m4t", "SeamlessM4TProcessor"),
("sew", "Wav2Vec2Processor"),
("sew-d", "Wav2Vec2Processor"),
+ ("siglip", "SiglipProcessor"),
("speech_to_text", "Speech2TextProcessor"),
("speech_to_text_2", "Speech2Text2Processor"),
("speecht5", "SpeechT5Processor"),
diff --git a/src/transformers/models/auto/tokenization_auto.py b/src/transformers/models/auto/tokenization_auto.py
index 5ff79fd822..2381d8153d 100644
--- a/src/transformers/models/auto/tokenization_auto.py
+++ b/src/transformers/models/auto/tokenization_auto.py
@@ -372,6 +372,7 @@ else:
"SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
),
),
+ ("siglip", ("SiglipTokenizer", None)),
("speech_to_text", ("Speech2TextTokenizer" if is_sentencepiece_available() else None, None)),
("speech_to_text_2", ("Speech2Text2Tokenizer", None)),
("speecht5", ("SpeechT5Tokenizer" if is_sentencepiece_available() else None, None)),
diff --git a/src/transformers/models/siglip/__init__.py b/src/transformers/models/siglip/__init__.py
new file mode 100644
index 0000000000..d47b7c5f5d
--- /dev/null
+++ b/src/transformers/models/siglip/__init__.py
@@ -0,0 +1,94 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_torch_available,
+ is_vision_available,
+)
+
+
+_import_structure = {
+ "configuration_siglip": [
+ "SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP",
+ "SiglipConfig",
+ "SiglipTextConfig",
+ "SiglipVisionConfig",
+ ],
+ "processing_siglip": ["SiglipProcessor"],
+ "tokenization_siglip": ["SiglipTokenizer"],
+}
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_siglip"] = ["SiglipImageProcessor"]
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_siglip"] = [
+ "SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "SiglipModel",
+ "SiglipPreTrainedModel",
+ "SiglipTextModel",
+ "SiglipVisionModel",
+ ]
+
+
+if TYPE_CHECKING:
+ from .configuration_siglip import (
+ SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP,
+ SiglipConfig,
+ SiglipTextConfig,
+ SiglipVisionConfig,
+ )
+ from .processing_siglip import SiglipProcessor
+ from .tokenization_siglip import SiglipTokenizer
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_siglip import SiglipImageProcessor
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_siglip import (
+ SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST,
+ SiglipModel,
+ SiglipPreTrainedModel,
+ SiglipTextModel,
+ SiglipVisionModel,
+ )
+
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/siglip/configuration_siglip.py b/src/transformers/models/siglip/configuration_siglip.py
new file mode 100644
index 0000000000..990bad7ace
--- /dev/null
+++ b/src/transformers/models/siglip/configuration_siglip.py
@@ -0,0 +1,302 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Siglip model configuration"""
+
+import os
+from typing import Union
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/config.json",
+}
+
+
+class SiglipTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`SiglipTextModel`]. It is used to instantiate a
+ Siglip text encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the text encoder of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the Siglip text model. Defines the number of different tokens that can be represented by
+ the `inputs_ids` passed when calling [`SiglipModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ max_position_embeddings (`int`, *optional*, defaults to 64):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ pad_token_id (`int`, *optional*, defaults to 1):
+ The id of the padding token in the vocabulary.
+ bos_token_id (`int`, *optional*, defaults to 49406):
+ The id of the beginning-of-sequence token in the vocabulary.
+ eos_token_id (`int`, *optional*, defaults to 49407):
+ The id of the end-of-sequence token in the vocabulary.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipTextConfig, SiglipTextModel
+
+ >>> # Initializing a SiglipTextConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipTextConfig()
+
+ >>> # Initializing a SiglipTextModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "siglip_text_model"
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ max_position_embeddings=64,
+ hidden_act="gelu_pytorch_tanh",
+ layer_norm_eps=1e-6,
+ attention_dropout=0.0,
+ # This differs from `CLIPTokenizer`'s default and from openai/siglip
+ # See https://github.com/huggingface/transformers/pull/24773#issuecomment-1632287538
+ pad_token_id=1,
+ bos_token_id=49406,
+ eos_token_id=49407,
+ **kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.max_position_embeddings = max_position_embeddings
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.attention_dropout = attention_dropout
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+ cls._set_token_in_kwargs(kwargs)
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the text config dict if we are loading from SiglipConfig
+ if config_dict.get("model_type") == "siglip":
+ config_dict = config_dict["text_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class SiglipVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`SiglipVisionModel`]. It is used to instantiate a
+ Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_channels (`int`, *optional*, defaults to 3):
+ Number of channels in the input images.
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size (resolution) of each patch.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipVisionConfig, SiglipVisionModel
+
+ >>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipVisionConfig()
+
+ >>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "siglip_vision_model"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ intermediate_size=3072,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ num_channels=3,
+ image_size=224,
+ patch_size=16,
+ hidden_act="gelu_pytorch_tanh",
+ layer_norm_eps=1e-6,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.image_size = image_size
+ self.attention_dropout = attention_dropout
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
+ cls._set_token_in_kwargs(kwargs)
+
+ config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
+
+ # get the vision config dict if we are loading from SiglipConfig
+ if config_dict.get("model_type") == "siglip":
+ config_dict = config_dict["vision_config"]
+
+ if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
+ logger.warning(
+ f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
+ f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
+ )
+
+ return cls.from_dict(config_dict, **kwargs)
+
+
+class SiglipConfig(PretrainedConfig):
+ r"""
+ [`SiglipConfig`] is the configuration class to store the configuration of a [`SiglipModel`]. It is used to
+ instantiate a Siglip model according to the specified arguments, defining the text model and vision model configs.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the Siglip
+ [google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`SiglipTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`SiglipVisionConfig`].
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import SiglipConfig, SiglipModel
+
+ >>> # Initializing a SiglipConfig with google/siglip-base-patch16-224 style configuration
+ >>> configuration = SiglipConfig()
+
+ >>> # Initializing a SiglipModel (with random weights) from the google/siglip-base-patch16-224 style configuration
+ >>> model = SiglipModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a SiglipConfig from a SiglipTextConfig and a SiglipVisionConfig
+ >>> from transformers import SiglipTextConfig, SiglipVisionConfig
+
+ >>> # Initializing a SiglipText and SiglipVision configuration
+ >>> config_text = SiglipTextConfig()
+ >>> config_vision = SiglipVisionConfig()
+
+ >>> config = SiglipConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "siglip"
+
+ def __init__(self, text_config=None, vision_config=None, **kwargs):
+ super().__init__(**kwargs)
+
+ if text_config is None:
+ text_config = {}
+ logger.info("`text_config` is `None`. Initializing the `SiglipTextConfig` with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("`vision_config` is `None`. initializing the `SiglipVisionConfig` with default values.")
+
+ self.text_config = SiglipTextConfig(**text_config)
+ self.vision_config = SiglipVisionConfig(**vision_config)
+
+ self.initializer_factor = 1.0
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: SiglipTextConfig, vision_config: SiglipVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`SiglipConfig`] (or a derived class) from siglip text model configuration and siglip vision
+ model configuration.
+
+ Returns:
+ [`SiglipConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
diff --git a/src/transformers/models/siglip/convert_siglip_to_hf.py b/src/transformers/models/siglip/convert_siglip_to_hf.py
new file mode 100644
index 0000000000..6adacef84f
--- /dev/null
+++ b/src/transformers/models/siglip/convert_siglip_to_hf.py
@@ -0,0 +1,413 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert SigLIP checkpoints from the original repository.
+
+URL: https://github.com/google-research/big_vision/tree/main
+"""
+
+
+import argparse
+import collections
+from pathlib import Path
+
+import numpy as np
+import requests
+import torch
+from huggingface_hub import hf_hub_download
+from numpy import load
+from PIL import Image
+
+from transformers import SiglipConfig, SiglipImageProcessor, SiglipModel, SiglipProcessor, SiglipTokenizer
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+model_name_to_checkpoint = {
+ # base checkpoints
+ "siglip-base-patch16-224": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_224_63724782.npz",
+ "siglip-base-patch16-256": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_256_60500360.npz",
+ "siglip-base-patch16-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_384_68578854.npz",
+ "siglip-base-patch16-512": "/Users/nielsrogge/Documents/SigLIP/webli_en_b16_512_68580893.npz",
+ # large checkpoints
+ "siglip-large-patch16-256": "/Users/nielsrogge/Documents/SigLIP/webli_en_l16_256_60552751.npz",
+ "siglip-large-patch16-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_l16_384_63634585.npz",
+ # multilingual checkpoint
+ "siglip-base-patch16-256-i18n": "/Users/nielsrogge/Documents/SigLIP/webli_i18n_b16_256_66117334.npz",
+ # so400m checkpoints
+ "siglip-so400m-patch14-384": "/Users/nielsrogge/Documents/SigLIP/webli_en_so400m_384_58765454.npz",
+}
+
+model_name_to_image_size = {
+ "siglip-base-patch16-224": 224,
+ "siglip-base-patch16-256": 256,
+ "siglip-base-patch16-384": 384,
+ "siglip-base-patch16-512": 512,
+ "siglip-large-patch16-256": 256,
+ "siglip-large-patch16-384": 384,
+ "siglip-base-patch16-256-i18n": 256,
+ "siglip-so400m-patch14-384": 384,
+}
+
+
+def get_siglip_config(model_name):
+ config = SiglipConfig()
+
+ vocab_size = 250000 if "i18n" in model_name else 32000
+ image_size = model_name_to_image_size[model_name]
+ patch_size = 16 if "patch16" in model_name else 14
+
+ # size of the architecture
+ config.vision_config.image_size = image_size
+ config.vision_config.patch_size = patch_size
+ config.text_config.vocab_size = vocab_size
+
+ if "base" in model_name:
+ pass
+ elif "large" in model_name:
+ config.text_config.hidden_size = 1024
+ config.text_config.intermediate_size = 4096
+ config.text_config.num_hidden_layers = 24
+ config.text_config.num_attention_heads = 16
+ config.vision_config.hidden_size = 1024
+ config.vision_config.intermediate_size = 4096
+ config.vision_config.num_hidden_layers = 24
+ config.vision_config.num_attention_heads = 16
+ elif "so400m" in model_name:
+ config.text_config.hidden_size = 1152
+ config.text_config.intermediate_size = 4304
+ config.text_config.num_hidden_layers = 27
+ config.text_config.num_attention_heads = 16
+ config.vision_config.hidden_size = 1152
+ config.vision_config.intermediate_size = 4304
+ config.vision_config.num_hidden_layers = 27
+ config.vision_config.num_attention_heads = 16
+ else:
+ raise ValueError("Model not supported")
+
+ return config
+
+
+def create_rename_keys(config):
+ rename_keys = []
+ # fmt: off
+
+ # vision encoder
+
+ rename_keys.append(("params/img/embedding/kernel", "vision_model.embeddings.patch_embedding.weight"))
+ rename_keys.append(("params/img/embedding/bias", "vision_model.embeddings.patch_embedding.bias"))
+ rename_keys.append(("params/img/pos_embedding", "vision_model.embeddings.position_embedding.weight"))
+
+ for i in range(config.vision_config.num_hidden_layers):
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_0/scale", f"vision_model.encoder.layers.{i}.layer_norm1.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_0/bias", f"vision_model.encoder.layers.{i}.layer_norm1.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_1/scale", f"vision_model.encoder.layers.{i}.layer_norm2.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/LayerNorm_1/bias", f"vision_model.encoder.layers.{i}.layer_norm2.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_0/kernel", f"vision_model.encoder.layers.{i}.mlp.fc1.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_0/bias", f"vision_model.encoder.layers.{i}.mlp.fc1.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_1/kernel", f"vision_model.encoder.layers.{i}.mlp.fc2.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MlpBlock_0/Dense_1/bias", f"vision_model.encoder.layers.{i}.mlp.fc2.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/key/kernel", f"vision_model.encoder.layers.{i}.self_attn.k_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/key/bias", f"vision_model.encoder.layers.{i}.self_attn.k_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/value/kernel", f"vision_model.encoder.layers.{i}.self_attn.v_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/value/bias", f"vision_model.encoder.layers.{i}.self_attn.v_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/query/kernel", f"vision_model.encoder.layers.{i}.self_attn.q_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/query/bias", f"vision_model.encoder.layers.{i}.self_attn.q_proj.bias"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/out/kernel", f"vision_model.encoder.layers.{i}.self_attn.out_proj.weight"))
+ rename_keys.append((f"params/img/Transformer/encoderblock_{i}/MultiHeadDotProductAttention_0/out/bias", f"vision_model.encoder.layers.{i}.self_attn.out_proj.bias"))
+
+ rename_keys.append(("params/img/Transformer/encoder_norm/scale", "vision_model.post_layernorm.weight"))
+ rename_keys.append(("params/img/Transformer/encoder_norm/bias", "vision_model.post_layernorm.bias"))
+
+ rename_keys.append(("params/img/MAPHead_0/probe", "vision_model.head.probe"))
+ rename_keys.append(("params/img/MAPHead_0/LayerNorm_0/scale", "vision_model.head.layernorm.weight"))
+ rename_keys.append(("params/img/MAPHead_0/LayerNorm_0/bias", "vision_model.head.layernorm.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_0/kernel", "vision_model.head.mlp.fc1.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_0/bias", "vision_model.head.mlp.fc1.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_1/kernel", "vision_model.head.mlp.fc2.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MlpBlock_0/Dense_1/bias", "vision_model.head.mlp.fc2.bias"))
+ rename_keys.append(("params/img/MAPHead_0/MultiHeadDotProductAttention_0/out/kernel", "vision_model.head.attention.out_proj.weight"))
+ rename_keys.append(("params/img/MAPHead_0/MultiHeadDotProductAttention_0/out/bias", "vision_model.head.attention.out_proj.bias"))
+
+ # text encoder
+
+ rename_keys.append(("params/txt/Embed_0/embedding", "text_model.embeddings.token_embedding.weight"))
+ rename_keys.append(("params/txt/pos_embedding", "text_model.embeddings.position_embedding.weight"))
+
+ for i in range(config.text_config.num_hidden_layers):
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_0/scale", f"text_model.encoder.layers.{i}.layer_norm1.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_0/bias", f"text_model.encoder.layers.{i}.layer_norm1.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_1/scale", f"text_model.encoder.layers.{i}.layer_norm2.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/LayerNorm_1/bias", f"text_model.encoder.layers.{i}.layer_norm2.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_0/kernel", f"text_model.encoder.layers.{i}.mlp.fc1.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_0/bias", f"text_model.encoder.layers.{i}.mlp.fc1.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_1/kernel", f"text_model.encoder.layers.{i}.mlp.fc2.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MlpBlock_0/Dense_1/bias", f"text_model.encoder.layers.{i}.mlp.fc2.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/key/kernel", f"text_model.encoder.layers.{i}.self_attn.k_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/key/bias", f"text_model.encoder.layers.{i}.self_attn.k_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/value/kernel", f"text_model.encoder.layers.{i}.self_attn.v_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/value/bias", f"text_model.encoder.layers.{i}.self_attn.v_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/query/kernel", f"text_model.encoder.layers.{i}.self_attn.q_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/query/bias", f"text_model.encoder.layers.{i}.self_attn.q_proj.bias"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/out/kernel", f"text_model.encoder.layers.{i}.self_attn.out_proj.weight"))
+ rename_keys.append((f"params/txt/Encoder_0/encoderblock_{i}/MultiHeadDotProductAttention_0/out/bias", f"text_model.encoder.layers.{i}.self_attn.out_proj.bias"))
+
+ rename_keys.append(("params/txt/Encoder_0/encoder_norm/scale", "text_model.final_layer_norm.weight"))
+ rename_keys.append(("params/txt/Encoder_0/encoder_norm/bias", "text_model.final_layer_norm.bias"))
+ rename_keys.append(("params/txt/head/kernel", "text_model.head.weight"))
+ rename_keys.append(("params/txt/head/bias", "text_model.head.bias"))
+
+ # learned temperature and bias
+ rename_keys.append(("params/t", "logit_scale"))
+ rename_keys.append(("params/b", "logit_bias"))
+
+ # fmt: on
+ return rename_keys
+
+
+def rename_key(dct, old, new, config):
+ val = dct.pop(old)
+
+ if ("out_proj" in new or "v_proj" in new or "k_proj" in new or "q_proj" in new) and "vision" in new:
+ val = val.reshape(-1, config.vision_config.hidden_size)
+ if ("out_proj" in new or "v_proj" in new or "k_proj" in new or "q_proj" in new) and "text" in new:
+ val = val.reshape(-1, config.text_config.hidden_size)
+
+ if "patch_embedding.weight" in new:
+ val = val.transpose(3, 2, 0, 1)
+ elif new.endswith("weight") and "position_embedding" not in new and "token_embedding" not in new:
+ val = val.T
+
+ if "position_embedding" in new and "vision" in new:
+ val = val.reshape(-1, config.vision_config.hidden_size)
+ if "position_embedding" in new and "text" in new:
+ val = val.reshape(-1, config.text_config.hidden_size)
+
+ if new.endswith("bias"):
+ val = val.reshape(-1)
+
+ dct[new] = torch.from_numpy(val)
+
+
+def read_in_q_k_v_head(state_dict, config):
+ # read in individual input projection layers
+ key_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/key/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ key_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/key/bias").reshape(-1)
+ value_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/value/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ value_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/value/bias").reshape(-1)
+ query_proj_weight = (
+ state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/query/kernel")
+ .reshape(-1, config.vision_config.hidden_size)
+ .T
+ )
+ query_proj_bias = state_dict.pop("params/img/MAPHead_0/MultiHeadDotProductAttention_0/query/bias").reshape(-1)
+
+ # next, add them to the state dict as a single matrix + vector
+ state_dict["vision_model.head.attention.in_proj_weight"] = torch.from_numpy(
+ np.concatenate([query_proj_weight, key_proj_weight, value_proj_weight], axis=0)
+ )
+ state_dict["vision_model.head.attention.in_proj_bias"] = torch.from_numpy(
+ np.concatenate([query_proj_bias, key_proj_bias, value_proj_bias], axis=0)
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+def flatten_nested_dict(params, parent_key="", sep="/"):
+ items = []
+
+ for k, v in params.items():
+ new_key = parent_key + sep + k if parent_key else k
+
+ if isinstance(v, collections.abc.MutableMapping):
+ items.extend(flatten_nested_dict(v, new_key, sep=sep).items())
+ else:
+ items.append((new_key, v))
+ return dict(items)
+
+
+@torch.no_grad()
+def convert_siglip_checkpoint(model_name, pytorch_dump_folder_path, verify_logits=True, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our SigLIP structure.
+ """
+
+ # define default SigLIP configuration
+ config = get_siglip_config(model_name)
+
+ # get checkpoint
+ checkpoint = model_name_to_checkpoint[model_name]
+
+ # get vocab file
+ if "i18n" in model_name:
+ vocab_file = "/Users/nielsrogge/Documents/SigLIP/multilingual_vocab/sentencepiece.model"
+ else:
+ vocab_file = "/Users/nielsrogge/Documents/SigLIP/english_vocab/sentencepiece.model"
+
+ # load original state dict
+ data = load(checkpoint)
+ state_dict = flatten_nested_dict(data)
+
+ # remove and rename some keys
+ rename_keys = create_rename_keys(config)
+ for src, dest in rename_keys:
+ rename_key(state_dict, src, dest, config)
+
+ # qkv matrices of attention pooling head need special treatment
+ read_in_q_k_v_head(state_dict, config)
+
+ # load HuggingFace model
+ model = SiglipModel(config).eval()
+ model.load_state_dict(state_dict)
+
+ # create processor
+ # important: make tokenizer not return attention_mask since original one doesn't require it
+ image_size = config.vision_config.image_size
+ size = {"height": image_size, "width": image_size}
+ image_processor = SiglipImageProcessor(size=size)
+ tokenizer = SiglipTokenizer(vocab_file=vocab_file, model_input_names=["input_ids"])
+ processor = SiglipProcessor(image_processor=image_processor, tokenizer=tokenizer)
+
+ # verify on dummy images and texts
+ url_1 = "https://cdn.openai.com/multimodal-neurons/assets/apple/apple-ipod.jpg"
+ image_1 = Image.open(requests.get(url_1, stream=True).raw).convert("RGB")
+ url_2 = "https://cdn.openai.com/multimodal-neurons/assets/apple/apple-blank.jpg"
+ image_2 = Image.open(requests.get(url_2, stream=True).raw).convert("RGB")
+ texts = ["an apple", "a picture of an apple"]
+
+ inputs = processor(images=[image_1, image_2], text=texts, return_tensors="pt", padding="max_length")
+
+ # verify input_ids against original ones
+ if image_size == 224:
+ filename = "siglip_pixel_values.pt"
+ elif image_size == 256:
+ filename = "siglip_pixel_values_256.pt"
+ elif image_size == 384:
+ filename = "siglip_pixel_values_384.pt"
+ elif image_size == 512:
+ filename = "siglip_pixel_values_512.pt"
+ else:
+ raise ValueError("Image size not supported")
+
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename=filename, repo_type="dataset")
+ original_pixel_values = torch.load(filepath)
+ filepath = hf_hub_download(repo_id="nielsr/test-image", filename="siglip_input_ids.pt", repo_type="dataset")
+ original_input_ids = torch.load(filepath)
+
+ if "i18n" not in model_name:
+ assert inputs.input_ids.tolist() == original_input_ids.tolist()
+
+ print("Mean of original pixel values:", original_pixel_values.mean())
+ print("Mean of new pixel values:", inputs.pixel_values.mean())
+
+ # note: we're testing with original pixel values here since we don't have exact pixel values
+ with torch.no_grad():
+ outputs = model(input_ids=inputs.input_ids, pixel_values=original_pixel_values)
+
+ # with torch.no_grad():
+ # outputs = model(input_ids=inputs.input_ids, pixel_values=inputs.pixel_values)
+
+ print(outputs.logits_per_image[:3, :3])
+
+ probs = torch.sigmoid(outputs.logits_per_image) # these are the probabilities
+ print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+ print(f"{probs[0][1]:.1%} that image 0 is '{texts[1]}'")
+
+ if verify_logits:
+ if model_name == "siglip-base-patch16-224":
+ expected_slice = torch.tensor(
+ [[-2.9621, -2.1672], [-0.2713, 0.2910]],
+ )
+ elif model_name == "siglip-base-patch16-256":
+ expected_slice = torch.tensor(
+ [[-3.1146, -1.9894], [-0.7312, 0.6387]],
+ )
+ elif model_name == "siglip-base-patch16-384":
+ expected_slice = torch.tensor(
+ [[-2.8098, -2.1891], [-0.4242, 0.4102]],
+ )
+ elif model_name == "siglip-base-patch16-512":
+ expected_slice = torch.tensor(
+ [[-2.7899, -2.2668], [-0.4295, -0.0735]],
+ )
+ elif model_name == "siglip-large-patch16-256":
+ expected_slice = torch.tensor(
+ [[-1.5827, -0.5801], [-0.9153, 0.1363]],
+ )
+ elif model_name == "siglip-large-patch16-384":
+ expected_slice = torch.tensor(
+ [[-2.1523, -0.2899], [-0.2959, 0.7884]],
+ )
+ elif model_name == "siglip-so400m-patch14-384":
+ expected_slice = torch.tensor([[-1.2441, -0.6649], [-0.7060, 0.7374]])
+ elif model_name == "siglip-base-patch16-256-i18n":
+ expected_slice = torch.tensor(
+ [[-0.9064, 0.1073], [-0.0299, 0.5304]],
+ )
+
+ assert torch.allclose(outputs.logits_per_image[:3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving processor to {pytorch_dump_folder_path}")
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model.push_to_hub(f"nielsr/{model_name}")
+ processor.push_to_hub(f"nielsr/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="siglip-base-patch16-224",
+ type=str,
+ choices=model_name_to_checkpoint.keys(),
+ help="Name of the model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--verify_logits",
+ action="store_false",
+ help="Whether to verify logits against the original implementation.",
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_siglip_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.verify_logits, args.push_to_hub)
diff --git a/src/transformers/models/siglip/image_processing_siglip.py b/src/transformers/models/siglip/image_processing_siglip.py
new file mode 100644
index 0000000000..285b6e9e55
--- /dev/null
+++ b/src/transformers/models/siglip/image_processing_siglip.py
@@ -0,0 +1,225 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for SigLIP."""
+
+from typing import Dict, List, Optional, Union
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import (
+ resize,
+ to_channel_dimension_format,
+)
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+)
+from ...utils import TensorType, is_vision_available, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_vision_available():
+ import PIL
+
+
+class SiglipImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a SigLIP image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `size`. Can be overridden by
+ `do_resize` in the `preprocess` method.
+ size (`Dict[str, int]` *optional*, defaults to `{"height": 224, "width": 224}`):
+ Size of the image after resizing. Can be overridden by `size` in the `preprocess` method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
+ Resampling filter to use if resizing the image. Can be overridden by `resample` in the `preprocess` method.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by `do_rescale` in
+ the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by `rescale_factor` in the `preprocess`
+ method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image by the specified mean and standard deviation. Can be overridden by
+ `do_normalize` in the `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `[0.5, 0.5, 0.5]`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `[0.5, 0.5, 0.5]`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ Can be overridden by the `image_std` parameter in the `preprocess` method.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ **kwargs,
+ ) -> None:
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 224, "width": 224}
+ image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: bool = None,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> PIL.Image.Image:
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Size of the image after resizing.
+ resample (`int`, *optional*, defaults to `self.resample`):
+ Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`. Only
+ has an effect if `do_resize` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to use for normalization. Only has an effect if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to use for normalization. Only has an effect if `do_normalize` is set to
+ `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size, param_name="size", default_to_square=False)
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ if do_resize and size is None:
+ raise ValueError("Size must be specified if do_resize is True.")
+
+ if do_rescale and rescale_factor is None:
+ raise ValueError("Rescale factor must be specified if do_rescale is True.")
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if do_resize:
+ height, width = size["height"], size["width"]
+ images = [
+ resize(image=image, size=(height, width), resample=resample, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_rescale:
+ images = [
+ self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_normalize:
+ images = [
+ self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) for image in images
+ ]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/siglip/modeling_siglip.py b/src/transformers/models/siglip/modeling_siglip.py
new file mode 100644
index 0000000000..b497b57fe2
--- /dev/null
+++ b/src/transformers/models/siglip/modeling_siglip.py
@@ -0,0 +1,1186 @@
+# coding=utf-8
+# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch Siglip model."""
+
+
+import math
+import warnings
+from dataclasses import dataclass
+from typing import Any, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn.init import _calculate_fan_in_and_fan_out
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_siglip import SiglipConfig, SiglipTextConfig, SiglipVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
+
+SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "google/siglip-base-patch16-224",
+ # See all SigLIP models at https://huggingface.co/models?filter=siglip
+]
+
+
+def _trunc_normal_(tensor, mean, std, a, b):
+ # Cut & paste from PyTorch official master until it's in a few official releases - RW
+ # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
+ def norm_cdf(x):
+ # Computes standard normal cumulative distribution function
+ return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
+
+ if (mean < a - 2 * std) or (mean > b + 2 * std):
+ warnings.warn(
+ "mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
+ "The distribution of values may be incorrect.",
+ stacklevel=2,
+ )
+
+ # Values are generated by using a truncated uniform distribution and
+ # then using the inverse CDF for the normal distribution.
+ # Get upper and lower cdf values
+ l = norm_cdf((a - mean) / std)
+ u = norm_cdf((b - mean) / std)
+
+ # Uniformly fill tensor with values from [l, u], then translate to
+ # [2l-1, 2u-1].
+ tensor.uniform_(2 * l - 1, 2 * u - 1)
+
+ # Use inverse cdf transform for normal distribution to get truncated
+ # standard normal
+ tensor.erfinv_()
+
+ # Transform to proper mean, std
+ tensor.mul_(std * math.sqrt(2.0))
+ tensor.add_(mean)
+
+ # Clamp to ensure it's in the proper range
+ tensor.clamp_(min=a, max=b)
+
+
+def trunc_normal_tf_(
+ tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
+) -> torch.Tensor:
+ """Fills the input Tensor with values drawn from a truncated
+ normal distribution. The values are effectively drawn from the
+ normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
+ with values outside :math:`[a, b]` redrawn until they are within
+ the bounds. The method used for generating the random values works
+ best when :math:`a \\leq \text{mean} \\leq b`.
+
+ NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
+ bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
+ and the result is subsquently scaled and shifted by the mean and std args.
+
+ Args:
+ tensor: an n-dimensional `torch.Tensor`
+ mean: the mean of the normal distribution
+ std: the standard deviation of the normal distribution
+ a: the minimum cutoff value
+ b: the maximum cutoff value
+ """
+ with torch.no_grad():
+ _trunc_normal_(tensor, 0, 1.0, a, b)
+ tensor.mul_(std).add_(mean)
+
+
+def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
+ fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
+ if mode == "fan_in":
+ denom = fan_in
+ elif mode == "fan_out":
+ denom = fan_out
+ elif mode == "fan_avg":
+ denom = (fan_in + fan_out) / 2
+
+ variance = scale / denom
+
+ if distribution == "truncated_normal":
+ # constant is stddev of standard normal truncated to (-2, 2)
+ trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
+ elif distribution == "normal":
+ with torch.no_grad():
+ tensor.normal_(std=math.sqrt(variance))
+ elif distribution == "uniform":
+ bound = math.sqrt(3 * variance)
+ with torch.no_grad():
+ tensor.uniform_(-bound, bound)
+ else:
+ raise ValueError(f"invalid distribution {distribution}")
+
+
+def lecun_normal_(tensor):
+ variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
+
+
+def default_flax_embed_init(tensor):
+ variance_scaling_(tensor, mode="fan_in", distribution="normal")
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
+class SiglipVisionModelOutput(ModelOutput):
+ """
+ Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
+
+ Args:
+ image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The image embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ image_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPTextModelOutput with CLIP->Siglip
+class SiglipTextModelOutput(ModelOutput):
+ """
+ Base class for text model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The text embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ text_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->Siglip
+class SiglipOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`SiglipTextModel`].
+ image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The image embeddings obtained by applying the projection layer to the pooled output of [`SiglipVisionModel`].
+ text_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`SiglipTextModel`].
+ vision_model_output(`BaseModelOutputWithPooling`):
+ The output of the [`SiglipVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: torch.FloatTensor = None
+ logits_per_text: torch.FloatTensor = None
+ text_embeds: torch.FloatTensor = None
+ image_embeds: torch.FloatTensor = None
+ text_model_output: BaseModelOutputWithPooling = None
+ vision_model_output: BaseModelOutputWithPooling = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+class SiglipVisionEmbeddings(nn.Module):
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=config.num_channels,
+ out_channels=self.embed_dim,
+ kernel_size=self.patch_size,
+ stride=self.patch_size,
+ padding="valid",
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
+
+ def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
+ patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
+ embeddings = patch_embeds.flatten(2).transpose(1, 2)
+
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+ return embeddings
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->Siglip
+class SiglipTextEmbeddings(nn.Module):
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__()
+ embed_dim = config.hidden_size
+
+ self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
+ self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ ) -> torch.Tensor:
+ seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, :seq_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.token_embedding(input_ids)
+
+ position_embeddings = self.position_embedding(position_ids)
+ embeddings = inputs_embeds + position_embeddings
+
+ return embeddings
+
+
+class SiglipAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ # Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ batch_size, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ k_v_seq_len = key_states.shape[-2]
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
+
+ if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
+class SiglipMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->Siglip
+class SiglipEncoderLayer(nn.Module):
+ def __init__(self, config: SiglipConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = SiglipAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+ self.mlp = SiglipMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+
+ # Ignore copy
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`):
+ Input to the layer of shape `(batch, seq_len, embed_dim)`.
+ attention_mask (`torch.FloatTensor`):
+ Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class SiglipPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = SiglipConfig
+ base_model_prefix = "siglip"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, SiglipVisionEmbeddings):
+ width = (
+ self.config.vision_config.hidden_size
+ if isinstance(self.config, SiglipConfig)
+ else self.config.hidden_size
+ )
+ nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
+ elif isinstance(module, nn.Embedding):
+ default_flax_embed_init(module.weight)
+ elif isinstance(module, SiglipAttention):
+ nn.init.xavier_uniform_(module.q_proj.weight)
+ nn.init.xavier_uniform_(module.k_proj.weight)
+ nn.init.xavier_uniform_(module.v_proj.weight)
+ nn.init.xavier_uniform_(module.out_proj.weight)
+ nn.init.zeros_(module.q_proj.bias)
+ nn.init.zeros_(module.k_proj.bias)
+ nn.init.zeros_(module.v_proj.bias)
+ nn.init.zeros_(module.out_proj.bias)
+ elif isinstance(module, SiglipMLP):
+ nn.init.xavier_uniform_(module.fc1.weight)
+ nn.init.xavier_uniform_(module.fc2.weight)
+ nn.init.normal_(module.fc1.bias, std=1e-6)
+ nn.init.normal_(module.fc2.bias, std=1e-6)
+ elif isinstance(module, SiglipMultiheadAttentionPoolingHead):
+ nn.init.xavier_uniform_(module.probe.data)
+ nn.init.xavier_uniform_(module.attention.in_proj_weight.data)
+ nn.init.zeros_(module.attention.in_proj_bias.data)
+ elif isinstance(module, SiglipModel):
+ logit_scale_init = torch.log(torch.tensor(1.0))
+ module.logit_scale.data.fill_(logit_scale_init)
+ module.logit_bias.data.zero_()
+ elif isinstance(module, (nn.Linear, nn.Conv2d)):
+ lecun_normal_(module.weight)
+ if module.bias is not None:
+ nn.init.zeros_(module.bias)
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+SIGLIP_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`SiglipConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+SIGLIP_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+SIGLIP_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+SIGLIP_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->Siglip
+class SiglipEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`SiglipEncoderLayer`].
+
+ Args:
+ config: SiglipConfig
+ """
+
+ def __init__(self, config: SiglipConfig):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ # Ignore copy
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for encoder_layer in self.layers:
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ encoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ output_attentions,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class SiglipTextTransformer(nn.Module):
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+ self.embeddings = SiglipTextEmbeddings(config)
+ self.encoder = SiglipEncoder(config)
+ self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ self.head = nn.Linear(embed_dim, embed_dim)
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is None:
+ raise ValueError("You have to specify input_ids")
+
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+
+ hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
+
+ # note: SigLIP's text model does not use a causal mask, unlike the original CLIP model.
+ # expand attention_mask
+ if attention_mask is not None:
+ # [batch_size, seq_len] -> [batch_size, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.final_layer_norm(last_hidden_state)
+
+ # Assuming "sticky" EOS tokenization, last token is always EOS.
+ pooled_output = last_hidden_state[:, -1, :]
+ pooled_output = self.head(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """The text model from SigLIP without any head or projection on top.""",
+ SIGLIP_START_DOCSTRING,
+)
+class SiglipTextModel(SiglipPreTrainedModel):
+ config_class = SiglipTextConfig
+
+ _no_split_modules = ["SiglipTextEmbeddings", "SiglipEncoderLayer"]
+
+ def __init__(self, config: SiglipTextConfig):
+ super().__init__(config)
+ self.text_model = SiglipTextTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.text_model.embeddings.token_embedding
+
+ def set_input_embeddings(self, value):
+ self.text_model.embeddings.token_embedding = value
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, SiglipTextModel
+
+ >>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> # important: make sure to set padding="max_length" as that's how the model was trained
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled (EOS token) states
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+class SiglipVisionTransformer(nn.Module):
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = SiglipVisionEmbeddings(config)
+ self.encoder = SiglipEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.head = SiglipMultiheadAttentionPoolingHead(config)
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
+ def forward(
+ self,
+ pixel_values,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ hidden_states = self.embeddings(pixel_values)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ last_hidden_state = self.post_layernorm(last_hidden_state)
+
+ pooled_output = self.head(last_hidden_state)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class SiglipMultiheadAttentionPoolingHead(nn.Module):
+ """Multihead Attention Pooling."""
+
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__()
+
+ self.probe = nn.Parameter(torch.randn(1, 1, config.hidden_size))
+ self.attention = torch.nn.MultiheadAttention(config.hidden_size, config.num_attention_heads, batch_first=True)
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.mlp = SiglipMLP(config)
+
+ def forward(self, hidden_state):
+ batch_size = hidden_state.shape[0]
+ probe = self.probe.repeat(batch_size, 1, 1)
+
+ hidden_state = self.attention(probe, hidden_state, hidden_state)[0]
+
+ residual = hidden_state
+ hidden_state = self.layernorm(hidden_state)
+ hidden_state = residual + self.mlp(hidden_state)
+
+ return hidden_state[:, 0]
+
+
+@add_start_docstrings(
+ """The vision model from SigLIP without any head or projection on top.""",
+ SIGLIP_START_DOCSTRING,
+)
+class SiglipVisionModel(SiglipPreTrainedModel):
+ config_class = SiglipVisionConfig
+ main_input_name = "pixel_values"
+
+ def __init__(self, config: SiglipVisionConfig):
+ super().__init__(config)
+
+ self.vision_model = SiglipVisionTransformer(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
+ def forward(
+ self,
+ pixel_values,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, SiglipVisionModel
+
+ >>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled features
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+
+@add_start_docstrings(SIGLIP_START_DOCSTRING)
+class SiglipModel(SiglipPreTrainedModel):
+ config_class = SiglipConfig
+
+ def __init__(self, config: SiglipConfig):
+ super().__init__(config)
+
+ if not isinstance(config.text_config, SiglipTextConfig):
+ raise ValueError(
+ "config.text_config is expected to be of type SiglipTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ if not isinstance(config.vision_config, SiglipVisionConfig):
+ raise ValueError(
+ "config.vision_config is expected to be of type SiglipVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.text_model = SiglipTextTransformer(text_config)
+ self.vision_model = SiglipVisionTransformer(vision_config)
+
+ self.logit_scale = nn.Parameter(torch.randn(1))
+ self.logit_bias = nn.Parameter(torch.randn(1))
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`SiglipTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> # important: make sure to set padding="max_length" as that's how the model was trained
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
+ >>> with torch.no_grad():
+ ... text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = text_outputs[1]
+
+ return pooled_output
+
+ @add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`SiglipVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use SiglipModel's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = vision_outputs[1]
+
+ return pooled_output
+
+ @add_start_docstrings_to_model_forward(SIGLIP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=SiglipOutput, config_class=SiglipConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, SiglipOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> import torch
+
+ >>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+ >>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+ >>> inputs = processor(text=texts, images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+
+ >>> logits_per_image = outputs.logits_per_image
+ >>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+ >>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
+ 31.9% that image 0 is 'a photo of 2 cats'
+ ```"""
+ # Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ text_embeds = text_outputs[1]
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * self.logit_scale.exp() + self.logit_bias
+ logits_per_image = logits_per_text.t()
+
+ loss = None
+ if return_loss:
+ raise NotImplementedError("SigLIP loss to be implemented")
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return SiglipOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
diff --git a/src/transformers/models/siglip/processing_siglip.py b/src/transformers/models/siglip/processing_siglip.py
new file mode 100644
index 0000000000..ecb229d28a
--- /dev/null
+++ b/src/transformers/models/siglip/processing_siglip.py
@@ -0,0 +1,143 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for SigLIP.
+"""
+
+from typing import List, Optional, Union
+
+from ...feature_extraction_utils import BatchFeature
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils_base import PaddingStrategy, PreTokenizedInput, TextInput, TruncationStrategy
+from ...utils import TensorType
+
+
+class SiglipProcessor(ProcessorMixin):
+ r"""
+ Constructs a Siglip processor which wraps a Siglip image processor and a Siglip tokenizer into a single processor.
+
+ [`SiglipProcessor`] offers all the functionalities of [`SiglipImageProcessor`] and [`SiglipTokenizer`]. See the
+ [`~SiglipProcessor.__call__`] and [`~SiglipProcessor.decode`] for more information.
+
+ Args:
+ image_processor ([`SiglipImageProcessor`]):
+ The image processor is a required input.
+ tokenizer ([`SiglipTokenizer`]):
+ The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "SiglipImageProcessor"
+ tokenizer_class = "SiglipTokenizer"
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ images: ImageInput = None,
+ padding: Union[bool, str, PaddingStrategy] = "max_length",
+ truncation: Union[bool, str, TruncationStrategy] = None,
+ max_length=None,
+ return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to SiglipTokenizer's [`~SiglipTokenizer.__call__`] if `text` is not `None` to encode
+ the text. To prepare the image(s), this method forwards the `images` argument to
+ SiglipImageProcessor's [`~SiglipImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
+ of the above two methods for more information.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. In case of a NumPy array/PyTorch tensor, each image should be of shape (C, H, W), where C is a
+ number of channels, H and W are image height and width.
+ padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `max_length`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding
+ index) among:
+ - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
+ acceptable input length for the model if that argument is not provided.
+ - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
+ lengths).
+ max_length (`int`, *optional*):
+ Maximum length of the returned list and optionally padding length (see above).
+ truncation (`bool`, *optional*):
+ Activates truncation to cut input sequences longer than `max_length` to `max_length`.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+
+ if text is None and images is None:
+ raise ValueError("You have to specify either text or images. Both cannot be none.")
+
+ if text is not None:
+ encoding = self.tokenizer(
+ text, return_tensors=return_tensors, padding=padding, truncation=truncation, max_length=max_length
+ )
+
+ if images is not None:
+ image_features = self.image_processor(images, return_tensors=return_tensors)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchFeature(data=dict(**image_features), tensor_type=return_tensors)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to SiglipTokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to SiglipTokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ @property
+ # Copied from transformers.models.clip.processing_clip.CLIPProcessor.model_input_names with CLIP->Siglip, T5->Siglip
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
diff --git a/src/transformers/models/siglip/tokenization_siglip.py b/src/transformers/models/siglip/tokenization_siglip.py
new file mode 100644
index 0000000000..7c34ab6d0c
--- /dev/null
+++ b/src/transformers/models/siglip/tokenization_siglip.py
@@ -0,0 +1,389 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Tokenization class for SigLIP model."""
+
+import os
+import re
+import string
+import warnings
+from shutil import copyfile
+from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple
+
+import sentencepiece as spm
+
+from ...convert_slow_tokenizer import import_protobuf
+from ...tokenization_utils import PreTrainedTokenizer
+from ...tokenization_utils_base import AddedToken
+
+
+if TYPE_CHECKING:
+ from ...tokenization_utils_base import TextInput
+from ...utils import logging, requires_backends
+
+
+logger = logging.get_logger(__name__)
+
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
+
+PRETRAINED_VOCAB_FILES_MAP = {
+ "vocab_file": {
+ "google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/spiece.model",
+ }
+}
+
+PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
+ "google/siglip-base-patch16-224": 256,
+}
+
+SPIECE_UNDERLINE = "▁"
+
+
+class SiglipTokenizer(PreTrainedTokenizer):
+ """
+ Construct a Siglip tokenizer. Based on [SentencePiece](https://github.com/google/sentencepiece).
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ [SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
+ contains the vocabulary necessary to instantiate a tokenizer.
+ eos_token (`str`, *optional*, defaults to `""`):
+ The end of sequence token.
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ additional_special_tokens (`List[str]`, *optional*):
+ Additional special tokens used by the tokenizer.
+ sp_model_kwargs (`dict`, *optional*):
+ Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
+ SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
+ to set:
+
+ - `enable_sampling`: Enable subword regularization.
+ - `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
+
+ - `nbest_size = {0,1}`: No sampling is performed.
+ - `nbest_size > 1`: samples from the nbest_size results.
+ - `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
+ using forward-filtering-and-backward-sampling algorithm.
+
+ - `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
+ BPE-dropout.
+ model_max_length (`int`, *optional*, defaults to 64):
+ The maximum length (in number of tokens) for model inputs.
+ do_lower_case (`bool`, *optional*, defaults to `True`):
+ Whether or not to lowercase the input when tokenizing.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
+ max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
+ model_input_names = ["input_ids", "attention_mask"]
+
+ def __init__(
+ self,
+ vocab_file,
+ eos_token="",
+ unk_token="",
+ pad_token="",
+ additional_special_tokens=None,
+ sp_model_kwargs: Optional[Dict[str, Any]] = None,
+ model_max_length=64,
+ do_lower_case=True,
+ **kwargs,
+ ) -> None:
+ requires_backends(self, "protobuf")
+
+ pad_token = (
+ AddedToken(pad_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(pad_token, str)
+ else pad_token
+ )
+ unk_token = (
+ AddedToken(unk_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(unk_token, str)
+ else unk_token
+ )
+ eos_token = (
+ AddedToken(eos_token, rstrip=True, lstrip=True, normalized=False, special=True)
+ if isinstance(eos_token, str)
+ else eos_token
+ )
+
+ self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
+
+ self.do_lower_case = do_lower_case
+ self.vocab_file = vocab_file
+
+ self.sp_model = self.get_spm_processor()
+ self.vocab_file = vocab_file
+
+ super().__init__(
+ eos_token=eos_token,
+ unk_token=unk_token,
+ pad_token=pad_token,
+ additional_special_tokens=additional_special_tokens,
+ sp_model_kwargs=self.sp_model_kwargs,
+ model_max_length=model_max_length,
+ do_lower_case=do_lower_case,
+ **kwargs,
+ )
+
+ def get_spm_processor(self):
+ tokenizer = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ with open(self.vocab_file, "rb") as f:
+ sp_model = f.read()
+ model_pb2 = import_protobuf()
+ model = model_pb2.ModelProto.FromString(sp_model)
+ normalizer_spec = model_pb2.NormalizerSpec()
+ normalizer_spec.add_dummy_prefix = False
+ model.normalizer_spec.MergeFrom(normalizer_spec)
+ sp_model = model.SerializeToString()
+ tokenizer.LoadFromSerializedProto(sp_model)
+ return tokenizer
+
+ @property
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.vocab_size
+ def vocab_size(self):
+ return self.sp_model.get_piece_size()
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.get_vocab
+ def get_vocab(self):
+ vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
+ vocab.update(self.added_tokens_encoder)
+ return vocab
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.get_special_tokens_mask
+ def get_special_tokens_mask(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
+ ) -> List[int]:
+ """
+ Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
+ special tokens using the tokenizer `prepare_for_model` method.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ already_has_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the token list is already formatted with special tokens for the model.
+
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
+ """
+ if already_has_special_tokens:
+ return super().get_special_tokens_mask(
+ token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
+ )
+
+ # normal case: some special tokens
+ if token_ids_1 is None:
+ return ([0] * len(token_ids_0)) + [1]
+ return ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._add_eos_if_not_present
+ def _add_eos_if_not_present(self, token_ids: List[int]) -> List[int]:
+ """Do not add eos again if user already added it."""
+ if len(token_ids) > 0 and token_ids[-1] == self.eos_token_id:
+ warnings.warn(
+ f"This sequence already has {self.eos_token}. In future versions this behavior may lead to duplicated"
+ " eos tokens being added."
+ )
+ return token_ids
+ else:
+ return token_ids + [self.eos_token_id]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.create_token_type_ids_from_sequences
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make
+ use of token type ids, therefore a list of zeros is returned.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of zeros.
+ """
+ eos = [self.eos_token_id]
+
+ if token_ids_1 is None:
+ return len(token_ids_0 + eos) * [0]
+ return len(token_ids_0 + eos + token_ids_1 + eos) * [0]
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.build_inputs_with_special_tokens
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. A sequence has the following format:
+
+ - single sequence: `X `
+ - pair of sequences: `A B `
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ token_ids_0 = self._add_eos_if_not_present(token_ids_0)
+ if token_ids_1 is None:
+ return token_ids_0
+ else:
+ token_ids_1 = self._add_eos_if_not_present(token_ids_1)
+ return token_ids_0 + token_ids_1
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.__getstate__
+ def __getstate__(self):
+ state = self.__dict__.copy()
+ state["sp_model"] = None
+ return state
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.__setstate__
+ def __setstate__(self, d):
+ self.__dict__ = d
+
+ # for backward compatibility
+ if not hasattr(self, "sp_model_kwargs"):
+ self.sp_model_kwargs = {}
+
+ self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ self.sp_model.Load(self.vocab_file)
+
+ def remove_punctuation(self, text: str) -> str:
+ return text.translate(str.maketrans("", "", string.punctuation))
+
+ # source: https://github.com/google-research/big_vision/blob/3b8e5ab6ad4f96e32b32826f9e1b8fd277914f9c/big_vision/evaluators/proj/image_text/prompt_engineering.py#L94
+ def canonicalize_text(self, text, *, keep_punctuation_exact_string=None):
+ """Returns canonicalized `text` (puncuation removed).
+
+ Args:
+ text (`str`):
+ String to be canonicalized.
+ keep_punctuation_exact_string (`str`, *optional*):
+ If provided, then this exact string is kept. For example providing '{}' will keep any occurrences of '{}'
+ (but will still remove '{' and '}' that appear separately).
+ """
+ if keep_punctuation_exact_string:
+ text = keep_punctuation_exact_string.join(
+ self.remove_punctuation(part) for part in text.split(keep_punctuation_exact_string)
+ )
+ else:
+ text = self.remove_punctuation(text)
+ text = re.sub(r"\s+", " ", text)
+ text = text.strip()
+
+ return text
+
+ def tokenize(self, text: "TextInput", add_special_tokens=False, **kwargs) -> List[str]:
+ """
+ Converts a string to a list of tokens.
+ """
+ tokens = super().tokenize(SPIECE_UNDERLINE + text.replace(SPIECE_UNDERLINE, " "), **kwargs)
+
+ if len(tokens) > 1 and tokens[0] == SPIECE_UNDERLINE and tokens[1] in self.all_special_tokens:
+ tokens = tokens[1:]
+ return tokens
+
+ @property
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.unk_token_length
+ def unk_token_length(self):
+ return len(self.sp_model.encode(str(self.unk_token)))
+
+ def _tokenize(self, text, **kwargs):
+ """
+ Returns a tokenized string.
+
+ We de-activated the `add_dummy_prefix` option, thus the sentencepiece internals will always strip any
+ SPIECE_UNDERLINE.
+
+ For example: `self.sp_model.encode(f"{SPIECE_UNDERLINE}Hey", out_type = str)` will give `['H', 'e', 'y']` instead of `['▁He', 'y']`.
+
+ Thus we always encode `f"{unk_token}text"` and strip the `unk_token`. Here is an example with `unk_token = ""` and `unk_token_length = 4`.
+ `self.tokenizer.sp_model.encode(" Hey", out_type = str)[4:]`.
+ """
+ text = self.canonicalize_text(text, keep_punctuation_exact_string=None)
+ tokens = self.sp_model.encode(text, out_type=str)
+
+ # 1. Encode string + prefix ex: " Hey"
+ tokens = self.sp_model.encode(self.unk_token + text, out_type=str)
+ # 2. Remove self.unk_token from ['<','unk','>', '▁Hey']
+ return tokens[self.unk_token_length :] if len(tokens) >= self.unk_token_length else tokens
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._convert_token_to_id
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.sp_model.piece_to_id(token)
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer._convert_id_to_token
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ token = self.sp_model.IdToPiece(index)
+ return token
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.convert_tokens_to_string
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ current_sub_tokens = []
+ # since we manually add the prefix space, we have to remove it
+ tokens[0] = tokens[0].lstrip(SPIECE_UNDERLINE)
+ out_string = ""
+ prev_is_special = False
+ for token in tokens:
+ # make sure that special tokens are not decoded using sentencepiece model
+ if token in self.all_special_tokens:
+ if not prev_is_special:
+ out_string += " "
+ out_string += self.sp_model.decode(current_sub_tokens) + token
+ prev_is_special = True
+ current_sub_tokens = []
+ else:
+ current_sub_tokens.append(token)
+ prev_is_special = False
+ out_string += self.sp_model.decode(current_sub_tokens)
+ return out_string.strip()
+
+ # Copied from transformers.models.t5.tokenization_t5.T5Tokenizer.save_vocabulary
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ out_vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+
+ if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
+ copyfile(self.vocab_file, out_vocab_file)
+ elif not os.path.isfile(self.vocab_file):
+ with open(out_vocab_file, "wb") as fi:
+ content_spiece_model = self.sp_model.serialized_model_proto()
+ fi.write(content_spiece_model)
+
+ return (out_vocab_file,)
diff --git a/src/transformers/pipelines/zero_shot_image_classification.py b/src/transformers/pipelines/zero_shot_image_classification.py
index b16d191754..83bd9970e8 100644
--- a/src/transformers/pipelines/zero_shot_image_classification.py
+++ b/src/transformers/pipelines/zero_shot_image_classification.py
@@ -18,6 +18,8 @@ if is_vision_available():
from ..image_utils import load_image
if is_torch_available():
+ import torch
+
from ..models.auto.modeling_auto import MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES
if is_tf_available():
@@ -120,7 +122,8 @@ class ZeroShotImageClassificationPipeline(Pipeline):
inputs = self.image_processor(images=[image], return_tensors=self.framework)
inputs["candidate_labels"] = candidate_labels
sequences = [hypothesis_template.format(x) for x in candidate_labels]
- text_inputs = self.tokenizer(sequences, return_tensors=self.framework, padding=True)
+ padding = "max_length" if self.model.config.model_type == "siglip" else True
+ text_inputs = self.tokenizer(sequences, return_tensors=self.framework, padding=padding)
inputs["text_inputs"] = [text_inputs]
return inputs
@@ -144,7 +147,12 @@ class ZeroShotImageClassificationPipeline(Pipeline):
def postprocess(self, model_outputs):
candidate_labels = model_outputs.pop("candidate_labels")
logits = model_outputs["logits"][0]
- if self.framework == "pt":
+ if self.framework == "pt" and self.model.config.model_type == "siglip":
+ probs = torch.sigmoid(logits).squeeze(-1)
+ scores = probs.tolist()
+ if not isinstance(scores, list):
+ scores = [scores]
+ elif self.framework == "pt":
probs = logits.softmax(dim=-1).squeeze(-1)
scores = probs.tolist()
if not isinstance(scores, list):
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index dbd46b5797..4d89b2942f 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -7514,6 +7514,37 @@ class SEWDPreTrainedModel(metaclass=DummyObject):
requires_backends(self, ["torch"])
+SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class SiglipModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipTextModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class SiglipVisionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class SpeechEncoderDecoderModel(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index f1a10ff571..89366aba50 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -471,6 +471,13 @@ class SegformerImageProcessor(metaclass=DummyObject):
requires_backends(self, ["vision"])
+class SiglipImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class Swin2SRImageProcessor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/siglip/__init__.py b/tests/models/siglip/__init__.py
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/tests/models/siglip/test_image_processor_siglip.py b/tests/models/siglip/test_image_processor_siglip.py
new file mode 100644
index 0000000000..5f43d6f08a
--- /dev/null
+++ b/tests/models/siglip/test_image_processor_siglip.py
@@ -0,0 +1,125 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import SiglipImageProcessor
+
+
+class SiglipImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+# Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest with CLIP->Siglip
+class SiglipImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = SiglipImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ self.image_processor_tester = SiglipImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ # Ignore copy
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+
+ # Ignore copy
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(
+ self.image_processor_dict, size={"height": 84, "width": 84}
+ )
+ self.assertEqual(image_processor.size, {"height": 84, "width": 84})
+
+ @unittest.skip("not supported")
+ # Ignore copy
+ def test_call_numpy_4_channels(self):
+ pass
diff --git a/tests/models/siglip/test_modeling_siglip.py b/tests/models/siglip/test_modeling_siglip.py
new file mode 100644
index 0000000000..b6889c1573
--- /dev/null
+++ b/tests/models/siglip/test_modeling_siglip.py
@@ -0,0 +1,631 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch Siglip model. """
+
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+import requests
+
+from transformers import SiglipConfig, SiglipTextConfig, SiglipVisionConfig
+from transformers.testing_utils import (
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import SiglipModel, SiglipTextModel, SiglipVisionModel
+ from transformers.models.siglip.modeling_siglip import SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import SiglipProcessor
+
+
+class SiglipVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPVisionModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return SiglipVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = SiglipVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPVisionModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as SIGLIP does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (SiglipVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = SiglipVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=SiglipVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="SIGLIP does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel has no base class and is not available in MODEL_MAPPING")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class SiglipTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return SiglipTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = SiglipTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTester.prepare_config_and_inputs_for_common
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (SiglipTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+ model_split_percents = [0.5, 0.8, 0.9]
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.setUp with CLIP->Siglip
+ def setUp(self):
+ self.model_tester = SiglipTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=SiglipTextConfig, hidden_size=37)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_config
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_model
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training
+ def test_training(self):
+ pass
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing_use_reentrant
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_training_gradient_checkpointing_use_reentrant_false
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Siglip does not use inputs_embeds")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_inputs_embeds
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="SiglipTextModel has no base class and is not available in MODEL_MAPPING")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_save_load_fast_init_from_base
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="SiglipTextModel has no base class and is not available in MODEL_MAPPING")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPTextModelTest.test_save_load_fast_init_to_base
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class SiglipModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = SiglipTextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = SiglipVisionModelTester(parent, **vision_kwargs)
+ self.is_training = is_training
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTester.prepare_config_and_inputs
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return SiglipConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(),
+ self.vision_model_tester.get_config(),
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = SiglipModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ "return_loss": False,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class SiglipModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (SiglipModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": SiglipModel} if is_torch_available() else {}
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.setUp with CLIP->Siglip
+ def setUp(self):
+ self.model_tester = SiglipModelTester(self)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_hidden_states_output
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_inputs_embeds
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_retain_grad_hidden_states_attentions
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not have input/output embeddings")
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model_common_attributes
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipModel does not support training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest._create_and_check_torchscript with CLIP->Siglip
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ return
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # Siglip needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_load_vision_text_config with CLIP->Siglip
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save SiglipConfig and check if we can load SiglipVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = SiglipVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save SiglipConfig and check if we can load SiglipTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = SiglipTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @slow
+ # Copied from tests.models.clip.test_modeling_clip.CLIPModelTest.test_model_from_pretrained with CLIPModel->SiglipModel, CLIP->SIGLIP
+ def test_model_from_pretrained(self):
+ for model_name in SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = SiglipModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+class SiglipModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "google/siglip-base-patch16-224"
+ model = SiglipModel.from_pretrained(model_name).to(torch_device)
+ processor = SiglipProcessor.from_pretrained(model_name)
+
+ image = prepare_img()
+ inputs = processor(
+ text=["a photo of 2 cats", "a photo of 2 dogs"], images=image, padding="max_length", return_tensors="pt"
+ ).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits_per_image = outputs.logits_per_image
+ logits_per_text = outputs.logits_per_text
+
+ # verify the logits
+ self.assertEqual(
+ logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+
+ expected_logits = torch.tensor([[-0.7567, -10.3354]], device=torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits_per_image, expected_logits, atol=1e-3))
+
+ # verify the probs
+ probs = torch.sigmoid(logits_per_image) # these are the probabilities
+ expected_probs = torch.tensor([[3.1937e-01, 3.2463e-05]], device=torch_device)
+ self.assertTrue(torch.allclose(probs, expected_probs, atol=1e-3))
diff --git a/tests/models/siglip/test_tokenization_siglip.py b/tests/models/siglip/test_tokenization_siglip.py
new file mode 100644
index 0000000000..586d6b0089
--- /dev/null
+++ b/tests/models/siglip/test_tokenization_siglip.py
@@ -0,0 +1,462 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import tempfile
+import unittest
+
+from transformers import SPIECE_UNDERLINE, AddedToken, BatchEncoding, SiglipTokenizer
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, slow
+from transformers.utils import cached_property, is_tf_available, is_torch_available
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+if is_torch_available():
+ FRAMEWORK = "pt"
+elif is_tf_available():
+ FRAMEWORK = "tf"
+else:
+ FRAMEWORK = "jax"
+
+
+@require_sentencepiece
+@require_tokenizers
+class SiglipTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = SiglipTokenizer
+ test_rust_tokenizer = False
+ test_sentencepiece = True
+ test_sentencepiece_ignore_case = True
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.setUp with T5->Siglip
+ def setUp(self):
+ super().setUp()
+
+ # We have a SentencePiece fixture for testing
+ tokenizer = SiglipTokenizer(SAMPLE_VOCAB)
+ tokenizer.save_pretrained(self.tmpdirname)
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_convert_token_and_id with T5->Siglip
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 1
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+
+ def test_full_tokenizer(self):
+ tokenizer = SiglipTokenizer(SAMPLE_VOCAB)
+
+ tokens = tokenizer.tokenize("This is a test")
+ self.assertListEqual(tokens, ["▁this", "▁is", "▁a", "▁t", "est"])
+
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), [66, 46, 10, 170, 382])
+
+ tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
+ self.assertListEqual(
+ tokens,
+ [
+ SPIECE_UNDERLINE,
+ "i",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "9",
+ "2",
+ "0",
+ "0",
+ "0",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "é",
+ ],
+ )
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(ids, [7, 23, 21, 84, 55, 24, 19, 7, 0, 602, 347, 347, 347, 12, 66, 46, 72, 80, 6, 0])
+
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(
+ back_tokens,
+ [
+ SPIECE_UNDERLINE,
+ "i",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "",
+ "2",
+ "0",
+ "0",
+ "0",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "",
+ ],
+ )
+
+ @cached_property
+ def siglip_tokenizer(self):
+ return SiglipTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.get_tokenizer with T5->Siglip
+ def get_tokenizer(self, **kwargs) -> SiglipTokenizer:
+ return self.tokenizer_class.from_pretrained(self.tmpdirname, **kwargs)
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_rust_and_python_full_tokenizers with T5->Siglip
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ return
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "I was born in 92000, and this is falsé."
+
+ tokens = tokenizer.tokenize(sequence)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ def test_eos_treatment(self):
+ tokenizer = self.siglip_tokenizer
+ batch_with_eos_added = tokenizer(["hi", "I went to the gym", ""])
+ batch_without_eos_added = tokenizer(["hi", "I went to the gym", ""])
+ self.assertListEqual(batch_with_eos_added["input_ids"], batch_without_eos_added["input_ids"])
+
+ def test_prepare_batch(self):
+ tokenizer = self.siglip_tokenizer
+ src_text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
+ expected_src_tokens = [262, 266, 476, 8532, 270, 4460, 3949, 1682, tokenizer.eos_token_id]
+ batch = tokenizer(src_text, padding=True, return_tensors=FRAMEWORK)
+ self.assertIsInstance(batch, BatchEncoding)
+
+ if FRAMEWORK != "jax":
+ result = list(batch.input_ids.numpy()[0])
+ else:
+ result = list(batch.input_ids.tolist()[0])
+
+ self.assertListEqual(expected_src_tokens, result)
+
+ self.assertEqual((2, 9), batch.input_ids.shape)
+
+ def test_empty_target_text(self):
+ tokenizer = self.siglip_tokenizer
+ src_text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
+ batch = tokenizer(src_text, padding=True, return_tensors=FRAMEWORK)
+ # check if input_ids are returned and no decoder_input_ids
+ self.assertIn("input_ids", batch)
+ self.assertNotIn("decoder_input_ids", batch)
+ self.assertNotIn("decoder_attention_mask", batch)
+
+ def test_max_length(self):
+ tokenizer = self.siglip_tokenizer
+ tgt_text = ["Summary of the text.", "Another summary."]
+ targets = tokenizer(
+ text_target=tgt_text, max_length=32, padding="max_length", truncation=True, return_tensors=FRAMEWORK
+ )
+ self.assertEqual(32, targets["input_ids"].shape[1])
+
+ def test_eos_in_input(self):
+ tokenizer = self.siglip_tokenizer
+ src_text = ["A long paragraph for summarization. "]
+ tgt_text = ["Summary of the text. "]
+ expected_src_tokens = [262, 266, 476, 8532, 270, 4460, 3949, 1682, 1]
+ expected_tgt_tokens = [6254, 267, 260, 1443, 1]
+
+ batch = tokenizer(src_text, text_target=tgt_text)
+
+ self.assertEqual(expected_src_tokens, batch["input_ids"][0])
+ self.assertEqual(expected_tgt_tokens, batch["labels"][0])
+
+ @unittest.skip(reason="SiglipTokenizer strips the punctuation")
+ def test_subword_regularization_tokenizer(self):
+ pass
+
+ @unittest.skip(reason="SiglipTokenizer strips the punctuation")
+ def test_pickle_subword_regularization_tokenizer(self):
+ pass
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_special_tokens_initialization with T5->Siglip
+ def test_special_tokens_initialization(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ added_tokens = [f"" for i in range(100)] + [AddedToken("", lstrip=True)]
+
+ tokenizer_r = self.rust_tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+ tokenizer_cr = self.rust_tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs, from_slow=True
+ )
+ tokenizer_p = self.tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+
+ p_output = tokenizer_p.encode("Hey this is a token")
+ r_output = tokenizer_r.encode("Hey this is a token")
+ cr_output = tokenizer_cr.encode("Hey this is a token")
+
+ special_token_id = tokenizer_r.encode("", add_special_tokens=False)[0]
+
+ self.assertEqual(p_output, r_output)
+ self.assertEqual(cr_output, r_output)
+ self.assertTrue(special_token_id in p_output)
+ self.assertTrue(special_token_id in r_output)
+ self.assertTrue(special_token_id in cr_output)
+
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_special_tokens_initialization_with_non_empty_additional_special_tokens with T5->Siglip
+ def test_special_tokens_initialization_with_non_empty_additional_special_tokens(self):
+ tokenizer_list = []
+ if self.test_slow_tokenizer:
+ tokenizer_list.append((self.tokenizer_class, self.get_tokenizer()))
+
+ if self.test_rust_tokenizer:
+ tokenizer_list.append((self.rust_tokenizer_class, self.get_rust_tokenizer()))
+
+ for tokenizer_class, tokenizer_utils in tokenizer_list:
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer_utils.save_pretrained(tmp_dir)
+
+ with open(os.path.join(tmp_dir, "special_tokens_map.json"), encoding="utf-8") as json_file:
+ special_tokens_map = json.load(json_file)
+
+ with open(os.path.join(tmp_dir, "tokenizer_config.json"), encoding="utf-8") as json_file:
+ tokenizer_config = json.load(json_file)
+
+ added_tokens_extra_ids = [f"" for i in range(100)]
+
+ special_tokens_map["additional_special_tokens"] = added_tokens_extra_ids + [
+ "an_additional_special_token"
+ ]
+ tokenizer_config["additional_special_tokens"] = added_tokens_extra_ids + [
+ "an_additional_special_token"
+ ]
+
+ with open(os.path.join(tmp_dir, "special_tokens_map.json"), "w", encoding="utf-8") as outfile:
+ json.dump(special_tokens_map, outfile)
+ with open(os.path.join(tmp_dir, "tokenizer_config.json"), "w", encoding="utf-8") as outfile:
+ json.dump(tokenizer_config, outfile)
+
+ # the following checks allow us to verify that our test works as expected, i.e. that the tokenizer takes
+ # into account the new value of additional_special_tokens given in the "tokenizer_config.json" and
+ # "special_tokens_map.json" files
+ tokenizer_without_change_in_init = tokenizer_class.from_pretrained(
+ tmp_dir,
+ )
+ self.assertIn(
+ "an_additional_special_token", tokenizer_without_change_in_init.additional_special_tokens
+ )
+ # self.assertIn("an_additional_special_token",tokenizer_without_change_in_init.get_vocab()) # BySiglipTokenization no vocab
+ self.assertEqual(
+ ["an_additional_special_token"],
+ tokenizer_without_change_in_init.convert_ids_to_tokens(
+ tokenizer_without_change_in_init.convert_tokens_to_ids(["an_additional_special_token"])
+ ),
+ )
+
+ # Now we test that we can change the value of additional_special_tokens in the from_pretrained
+ new_added_tokens = added_tokens_extra_ids + [AddedToken("a_new_additional_special_token", lstrip=True)]
+ tokenizer = tokenizer_class.from_pretrained(
+ tmp_dir,
+ additional_special_tokens=new_added_tokens,
+ )
+
+ self.assertIn("a_new_additional_special_token", tokenizer.additional_special_tokens)
+ self.assertEqual(
+ ["a_new_additional_special_token"],
+ tokenizer.convert_ids_to_tokens(
+ tokenizer.convert_tokens_to_ids(["a_new_additional_special_token"])
+ ),
+ )
+
+ def test_sentencepiece_tokenize_and_convert_tokens_to_string(self):
+ """Test ``_tokenize`` and ``convert_tokens_to_string``."""
+ if not self.test_sentencepiece:
+ return
+
+ tokenizer = self.get_tokenizer()
+ text = "This is text to test the tokenizer."
+
+ if self.test_sentencepiece_ignore_case:
+ text = text.lower()
+
+ tokens = tokenizer.tokenize(text)
+
+ self.assertTrue(len(tokens) > 0)
+
+ # check if converting back to original text works
+ reverse_text = tokenizer.convert_tokens_to_string(tokens)
+
+ if self.test_sentencepiece_ignore_case:
+ reverse_text = reverse_text.lower()
+
+ expected_text = "this is text to test the tokenizer"
+ self.assertEqual(reverse_text, expected_text)
+
+ special_tokens = tokenizer.all_special_tokens
+ special_tokens_string = tokenizer.convert_tokens_to_string(special_tokens)
+ for special_token in special_tokens:
+ self.assertIn(special_token, special_tokens_string)
+
+ if self.test_rust_tokenizer:
+ rust_tokenizer = self.get_rust_tokenizer()
+ special_tokens_string_rust = rust_tokenizer.convert_tokens_to_string(special_tokens)
+ self.assertEqual(special_tokens_string, special_tokens_string_rust)
+
+ # overwritten from `test_tokenization_common` since Siglip has no max length
+ # Copied from tests.models.t5.test_tokenization_t5.T5TokenizationTest.test_pretrained_model_lists with T5->Siglip
+ def test_pretrained_model_lists(self):
+ # We should have at least one default checkpoint for each tokenizer
+ # We should specify the max input length as well (used in some part to list the pretrained checkpoints)
+ self.assertGreaterEqual(len(self.tokenizer_class.pretrained_vocab_files_map), 1)
+ self.assertGreaterEqual(len(list(self.tokenizer_class.pretrained_vocab_files_map.values())[0]), 1)
+
+ @slow
+ def test_tokenizer_integration(self):
+ tokenizer = SiglipTokenizer.from_pretrained("google/siglip-base-patch16-224")
+
+ # fmt: off
+ texts = [
+ 'the real mountain view',
+ 'Zürich',
+ 'San Francisco',
+ 'a picture of a laptop with the lockscreen on, a cup of cappucino, salt and pepper grinders. The view through the window reveals lake Zürich and the Alps in the background of the city.',
+ ]
+
+ expected_input_ids = [
+ [260, 638, 3293, 870, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [262, 761, 5879, 5345, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [262, 264, 452, 20563, 15949, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [262, 266, 1357, 267, 262, 266, 4429, 275, 260, 3940, 6360, 277, 262, 266, 3064, 267, 3549, 388, 16538, 296, 298, 2617, 263, 4869, 14998, 264, 260, 870, 393, 260, 1710, 7958, 4324, 262, 761, 5879, 5345, 263, 260, 1518, 388, 264, 268, 260, 1970, 267, 260, 741, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ ]
+ # fmt: on
+
+ for text, expected in zip(texts, expected_input_ids):
+ input_ids = tokenizer(text, padding="max_length").input_ids
+ self.assertListEqual(input_ids, expected)
+
+ def test_some_edge_cases(self):
+ tokenizer = SiglipTokenizer.from_pretrained("google/siglip-base-patch16-224", legacy=False)
+
+ sp_tokens = tokenizer.sp_model.encode(">", out_type=str)
+ self.assertEqual(sp_tokens, ["", ">"])
+ tokens = tokenizer.tokenize(">")
+ self.assertNotEqual(sp_tokens, tokens)
+ self.assertEqual(tokens, [""])
+
+ tokens = tokenizer.tokenize("")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, tokenizer.sp_model.encode("", out_type=str))
+
+ tokens = tokenizer.tokenize(" ")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, tokenizer.sp_model.encode(" ", out_type=str))
+
+ tokens = tokenizer.tokenize("▁")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, tokenizer.sp_model.encode("▁", out_type=str))
+
+ tokens = tokenizer.tokenize(" ▁")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, tokenizer.sp_model.encode("▁", out_type=str))
+
+
+@require_sentencepiece
+@require_tokenizers
+class CommonSpmIntegrationTests(unittest.TestCase):
+ """
+ A class that regroups important test to make sure that we properly handle the special tokens.
+ """
+
+ @classmethod
+ def setUpClass(cls):
+ tokenizer = SiglipTokenizer(SAMPLE_VOCAB, extra_ids=0, legacy=False)
+ tokenizer.add_special_tokens(
+ {"additional_special_tokens": [AddedToken("", rstrip=False, lstrip=False)]}
+ )
+ cls.tokenizer = tokenizer
+
+ def test_add_dummy_prefix(self):
+ # make sure `'▁'` is prepended, and outputs match sp_model's
+ # `sentencepiece.NormalizerSpec.add_dummy_prefix` attribute
+ input_ids = self.tokenizer.encode(". Hello", add_special_tokens=False)
+ self.assertEqual(input_ids, [37, 86, 20])
+ self.assertEqual(input_ids, [37, 86, 20])
+ tokens = self.tokenizer.tokenize(". Hello")
+ self.assertEqual(tokens, ["▁he", "ll", "o"])
+
+ tokens = self.tokenizer.tokenize("")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, self.tokenizer.sp_model.encode("", out_type=str))
+
+ tokens = self.tokenizer.tokenize(" ")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, self.tokenizer.sp_model.encode(" ", out_type=str))
+
+ tokens = self.tokenizer.tokenize("▁")
+ self.assertEqual(tokens, [])
+ self.assertEqual(tokens, self.tokenizer.sp_model.encode("▁", out_type=str))
+
+ def test_remove_extra_whitespaces(self):
+ # make sure the extra spaces are eaten
+ # sentencepiece.NormalizerSpec.remove_extra_whitespaces attribute
+ input_ids = self.tokenizer.encode(" . Hello", add_special_tokens=False)
+ self.assertEqual(input_ids, [37, 86, 20])
+ self.assertEqual(input_ids, [37, 86, 20])
+ tokens = self.tokenizer.tokenize(" . Hello")
+ self.assertEqual(tokens, ["▁he", "ll", "o"])
+
+ # `'▁'` is also a whitespace
+ input_ids = self.tokenizer.encode("▁He is not")
+ self.assertEqual(input_ids, [37, 46, 44, 2])
+ tokens = self.tokenizer.tokenize("▁He is not")
+ self.assertEqual(tokens, ["▁he", "▁is", "▁not"]) # no extra space added
+
+ input_ids = self.tokenizer.encode("▁He is not ▁He")
+ self.assertEqual(input_ids, [37, 46, 44, 37, 2])
+ tokens = self.tokenizer.tokenize("▁He is not ▁He")
+ self.assertEqual(tokens, ["▁he", "▁is", "▁not", "▁he"]) # spaces are eaten by spm even if not start
diff --git a/tests/pipelines/test_pipelines_zero_shot_image_classification.py b/tests/pipelines/test_pipelines_zero_shot_image_classification.py
index 197019f42e..7adae8ee96 100644
--- a/tests/pipelines/test_pipelines_zero_shot_image_classification.py
+++ b/tests/pipelines/test_pipelines_zero_shot_image_classification.py
@@ -241,3 +241,37 @@ class ZeroShotImageClassificationPipelineTests(unittest.TestCase):
]
* 5,
)
+
+ @slow
+ @require_torch
+ def test_siglip_model_pt(self):
+ image_classifier = pipeline(
+ task="zero-shot-image-classification",
+ model="google/siglip-base-patch16-224",
+ )
+ # This is an image of 2 cats with remotes and no planes
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ output = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
+
+ self.assertEqual(
+ nested_simplify(output),
+ [
+ {"score": 0.198, "label": "2 cats"},
+ {"score": 0.0, "label": "a remote"},
+ {"score": 0.0, "label": "a plane"},
+ ],
+ )
+
+ output = image_classifier([image] * 5, candidate_labels=["2 cats", "a plane", "a remote"], batch_size=2)
+
+ self.assertEqual(
+ nested_simplify(output),
+ [
+ [
+ {"score": 0.198, "label": "2 cats"},
+ {"score": 0.0, "label": "a remote"},
+ {"score": 0.0, "label": "a plane"},
+ ]
+ ]
+ * 5,
+ )
diff --git a/utils/check_copies.py b/utils/check_copies.py
index 3d352cc831..ea6f2d6591 100644
--- a/utils/check_copies.py
+++ b/utils/check_copies.py
@@ -1061,6 +1061,7 @@ MODELS_NOT_IN_README = [
"Vision Encoder decoder",
"VisionTextDualEncoder",
"CLIPVisionModel",
+ "SiglipVisionModel",
]
# Template for new entries to add in the main README when we have missing models.
diff --git a/utils/check_repo.py b/utils/check_repo.py
index 1d6193ebd7..0de932fffa 100644
--- a/utils/check_repo.py
+++ b/utils/check_repo.py
@@ -214,7 +214,6 @@ IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
"ChineseCLIPVisionModel",
"CLIPTextModel",
"CLIPTextModelWithProjection",
- "CLIPVisionModel",
"CLIPVisionModelWithProjection",
"ClvpForCausalLM",
"ClvpModel",
@@ -309,6 +308,8 @@ IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
"SeamlessM4Tv2NARTextToUnitForConditionalGeneration",
"SeamlessM4Tv2CodeHifiGan",
"SeamlessM4Tv2ForSpeechToSpeech", # no auto class for speech-to-speech
+ "SiglipVisionModel",
+ "SiglipTextModel",
]
# DO NOT edit this list!
diff --git a/utils/check_table.py b/utils/check_table.py
index 6eec475403..0042ce72fc 100644
--- a/utils/check_table.py
+++ b/utils/check_table.py
@@ -171,7 +171,7 @@ MODEL_NAMES_WITH_SAME_CONFIG = {
"XLS-R": "Wav2Vec2",
"XLSR-Wav2Vec2": "Wav2Vec2",
}
-MODEL_NAMES_TO_IGNORE = ["CLIPVisionModel"]
+MODEL_NAMES_TO_IGNORE = ["CLIPVisionModel", "SiglipVisionModel"]
def get_model_table_from_auto_modules() -> str: