Add documented support for object detection w/ DETR
This commit is contained in:
parent
75dcb2900e
commit
e95811edad
|
|
@ -6,7 +6,7 @@
|
||||||
[](https://github.com/xenova/transformers.js/blob/main/LICENSE)
|
[](https://github.com/xenova/transformers.js/blob/main/LICENSE)
|
||||||
|
|
||||||
|
|
||||||
Run 🤗 Transformers in your browser! We currently support [BERT](https://huggingface.co/docs/transformers/model_doc/bert), [ALBERT](https://huggingface.co/docs/transformers/model_doc/albert), [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert), [T5](https://huggingface.co/docs/transformers/model_doc/t5), [T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1), [FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5), [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [BART](https://huggingface.co/docs/transformers/model_doc/bart), [CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen), [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper), [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), [Vision Transformer](https://huggingface.co/docs/transformers/model_doc/vit), and [VisionEncoderDecoder](https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder) models, for a variety of tasks including: masked language modelling, text classification, text-to-text generation, translation, summarization, question answering, text generation, automatic speech recognition, image classification, zero-shot image classification, and image-to-text.
|
Run 🤗 Transformers in your browser! We currently support [BERT](https://huggingface.co/docs/transformers/model_doc/bert), [ALBERT](https://huggingface.co/docs/transformers/model_doc/albert), [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert), [T5](https://huggingface.co/docs/transformers/model_doc/t5), [T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1), [FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5), [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [BART](https://huggingface.co/docs/transformers/model_doc/bart), [CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen), [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper), [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), [Vision Transformer](https://huggingface.co/docs/transformers/model_doc/vit), [VisionEncoderDecoder](https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder), and [DETR](https://huggingface.co/docs/transformers/model_doc/detr) models, for a variety of tasks including: masked language modelling, text classification, text-to-text generation, translation, summarization, question answering, text generation, automatic speech recognition, image classification, zero-shot image classification, image-to-text, and object detection.
|
||||||
|
|
||||||
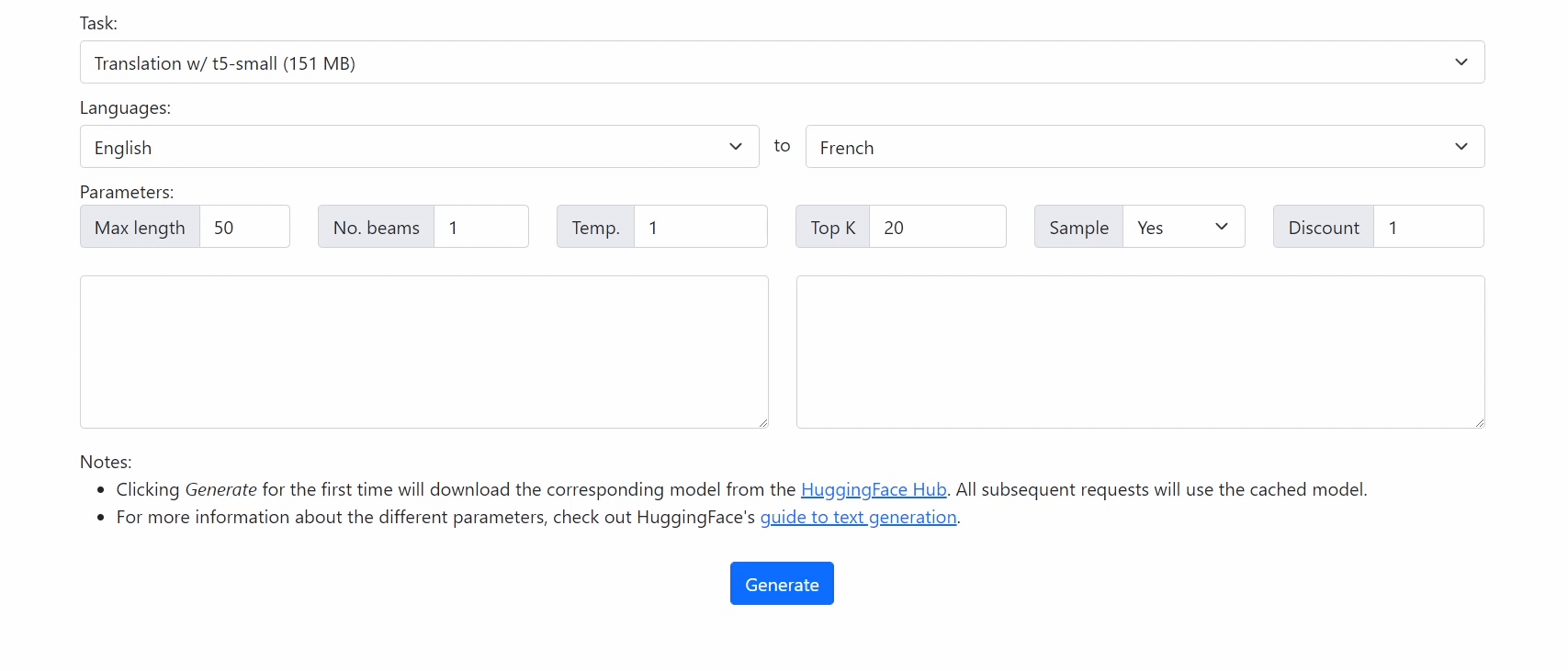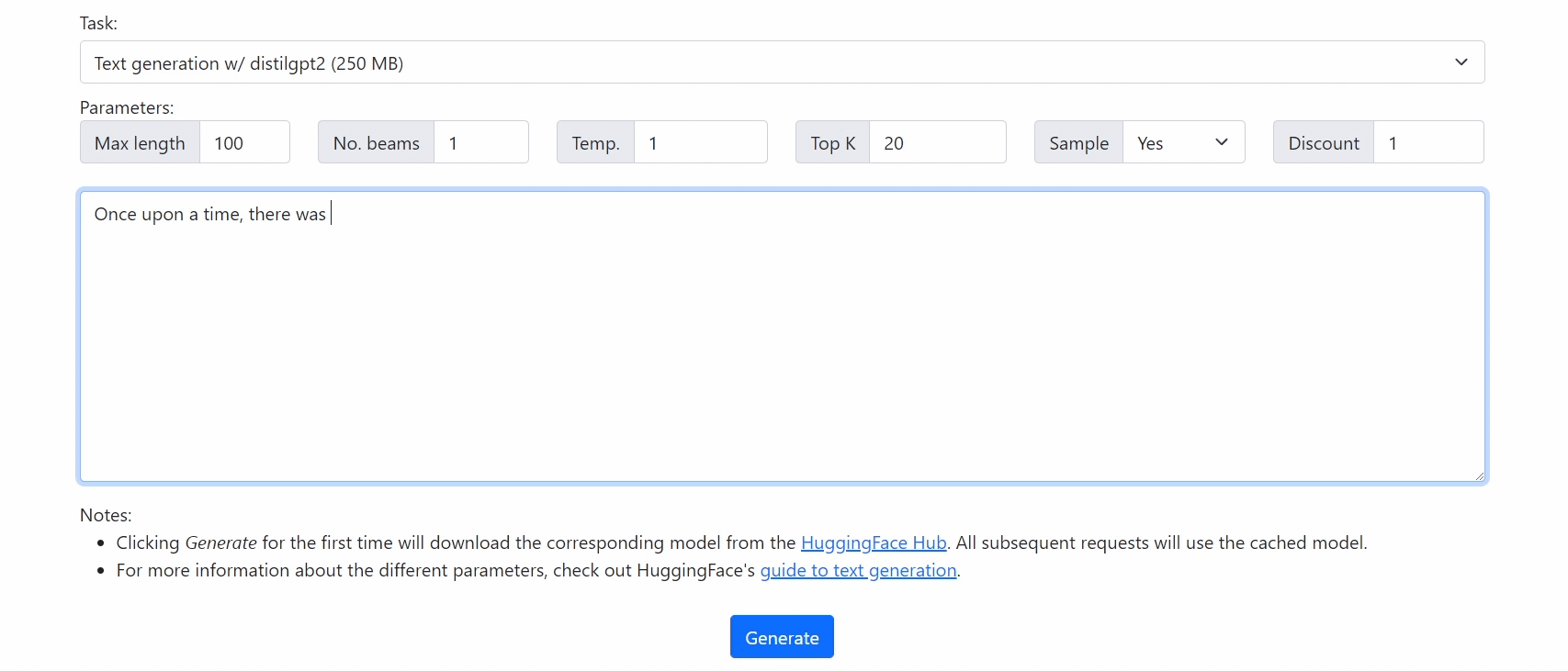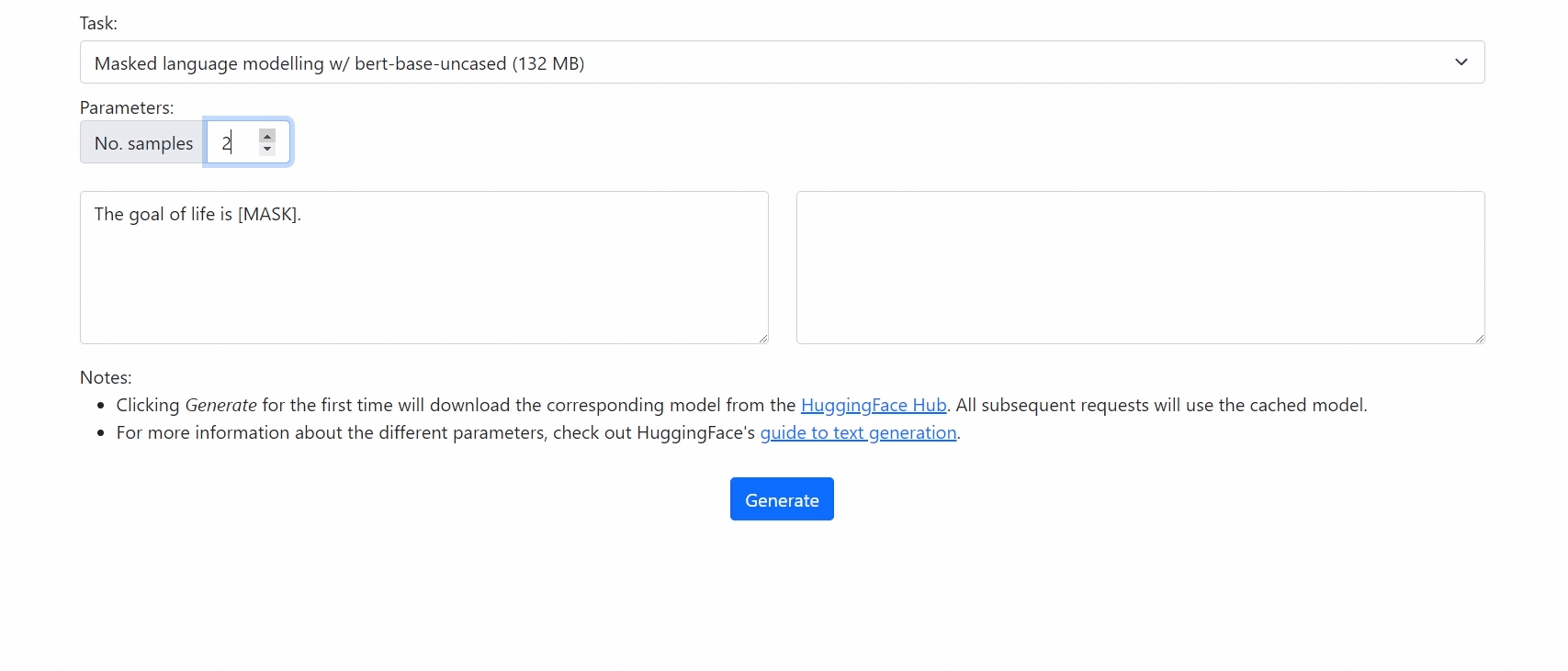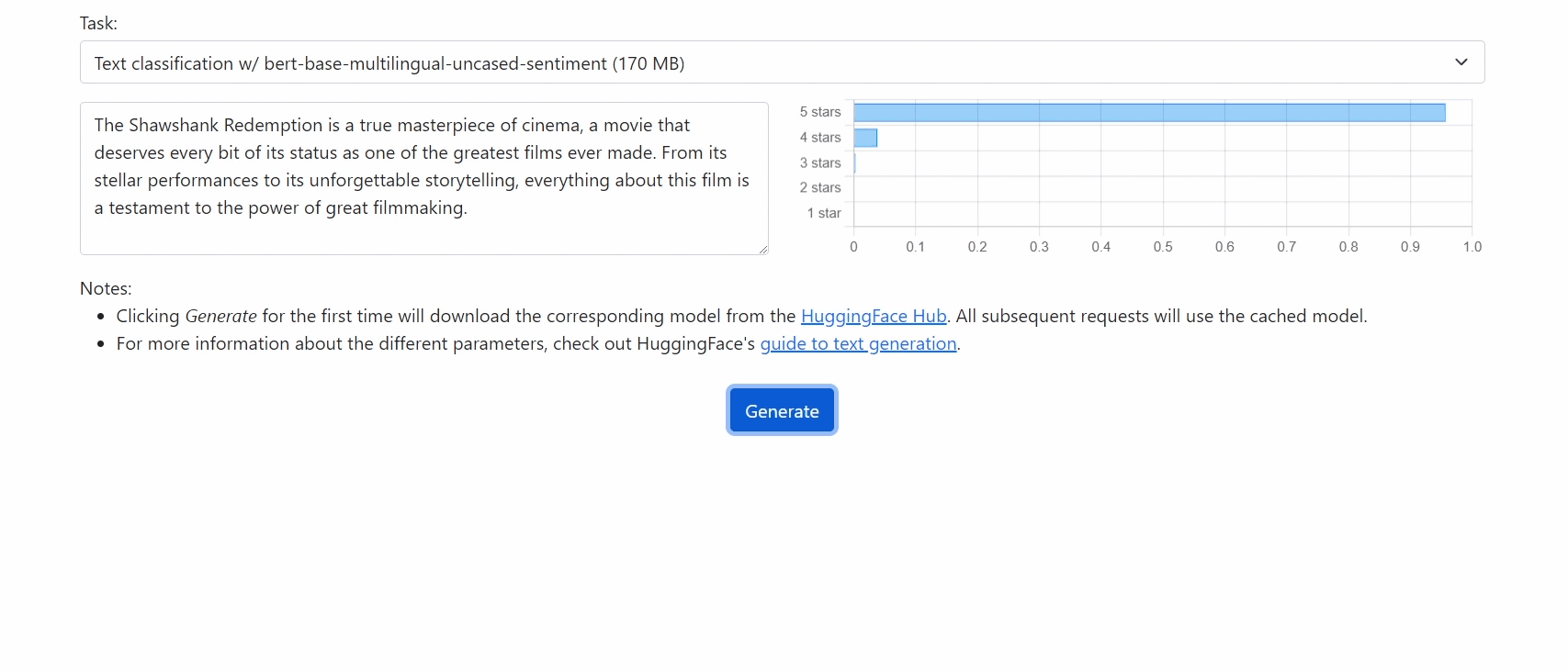
|

|
||||||
|
|
||||||
|
|
|
||||||
20
index.html
20
index.html
|
|
@ -752,6 +752,17 @@ env.onnx.wasm.wasmPaths = '/path/to/files/';</code></pre>
|
||||||
</a>.
|
</a>.
|
||||||
</div>
|
</div>
|
||||||
</li>
|
</li>
|
||||||
|
<li class="list-group-item d-flex justify-content-between align-items-start">
|
||||||
|
<div class="ms-2 me-auto">
|
||||||
|
<div class="fw-bold">object-detection</div>
|
||||||
|
Supported models: <code>facebook/detr-resnet-50</code>,
|
||||||
|
<code>facebook/detr-resnet-101</code>.
|
||||||
|
For more information, check out the
|
||||||
|
<a href="https://huggingface.co/tasks/object-detection">
|
||||||
|
Object detection docs
|
||||||
|
</a>.
|
||||||
|
</div>
|
||||||
|
</li>
|
||||||
<li class="list-group-item d-flex justify-content-between align-items-start">
|
<li class="list-group-item d-flex justify-content-between align-items-start">
|
||||||
<div class="ms-2 me-auto">
|
<div class="ms-2 me-auto">
|
||||||
<div class="fw-bold">embeddings</div>
|
<div class="fw-bold">embeddings</div>
|
||||||
|
|
@ -905,6 +916,15 @@ env.onnx.wasm.wasmPaths = '/path/to/files/';</code></pre>
|
||||||
Encoder Decoder Models docs</a>.
|
Encoder Decoder Models docs</a>.
|
||||||
</div>
|
</div>
|
||||||
</li>
|
</li>
|
||||||
|
<li class="list-group-item d-flex justify-content-between align-items-start">
|
||||||
|
<div class="ms-2 me-auto">
|
||||||
|
<div class="fw-bold">DETR</div>
|
||||||
|
Tasks: Object detection
|
||||||
|
<code>(AutoModelForObjectDetection)</code>.
|
||||||
|
For more information, check out the <a
|
||||||
|
href="https://huggingface.co/docs/transformers/model_doc/detr">DETR docs</a>.
|
||||||
|
</div>
|
||||||
|
</li>
|
||||||
</ol>
|
</ol>
|
||||||
<br>
|
<br>
|
||||||
<p class="mb-2">Don't see your model type or task supported? Raise an
|
<p class="mb-2">Don't see your model type or task supported? Raise an
|
||||||
|
|
|
||||||
|
|
@ -1,7 +1,7 @@
|
||||||
{
|
{
|
||||||
"name": "@xenova/transformers",
|
"name": "@xenova/transformers",
|
||||||
"version": "1.3.2",
|
"version": "1.3.2",
|
||||||
"description": "Run 🤗 Transformers in your browser! We currently support BERT, ALBERT, DistilBERT, T5, T5v1.1, FLAN-T5, GPT2, BART, CodeGen, Whisper, CLIP, Vision Transformer, and VisionEncoderDecoder models, for a variety of tasks including: masked language modelling, text classification, text-to-text generation, translation, summarization, question answering, text generation, automatic speech recognition, image classification, zero-shot image classification, and image-to-text.",
|
"description": "Run 🤗 Transformers in your browser! We currently support BERT, ALBERT, DistilBERT, T5, T5v1.1, FLAN-T5, GPT2, BART, CodeGen, Whisper, CLIP, Vision Transformer, VisionEncoderDecoder, and DETR models, for a variety of tasks including: masked language modelling, text classification, text-to-text generation, translation, summarization, question answering, text generation, automatic speech recognition, image classification, zero-shot image classification, image-to-text, and object detection.",
|
||||||
"main": "./src/transformers.js",
|
"main": "./src/transformers.js",
|
||||||
"directories": {
|
"directories": {
|
||||||
"test": "tests"
|
"test": "tests"
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue